※本記事はTC19のDevsOnStageで発表と、TC19でのセッション「Data Model Enhancement | TableauSoftware」の情報を基に作成しています。実際のリリースまでに多少の変更などはあることが予想される点、予めご了承ください。
こんにちは、エクスチュアの渡部です。
今年のTableauConference2019の発表の目玉の一つ、「新データモデリング(リレーションシップ)」について紹介します。
データモデリングの発表はこちらをご覧ください。
リレーションシップとは、来年度のTableauで実装予定の新しいデータモデル(≒データソース画面での設定方法)です。
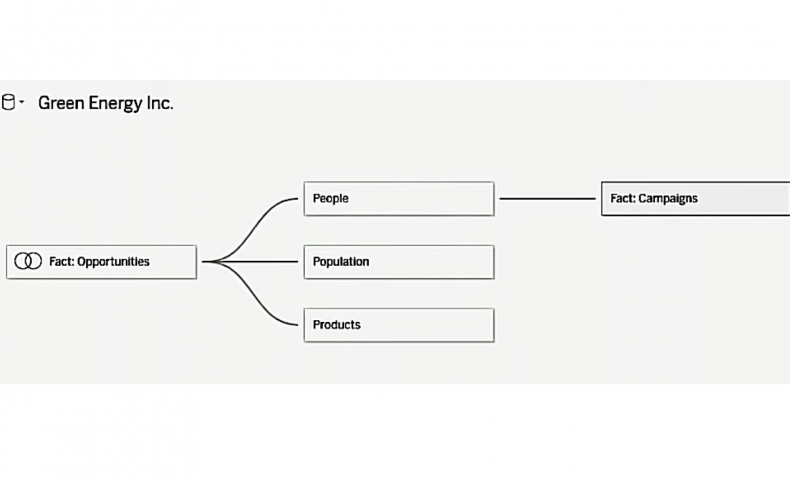
多分ですが、対応バージョンになると、おそらくデータソースの作成画面が急にこんな感じに変化します。
従来は、物理テーブルを配置→複数配置する場合は結合を定義していました。
一方でリレーションシップでは、論理テーブルを配置→複数配置する場合は「リレーション」を定義する形になります。ここで重要なのは「リレーションを定義したからといって実際の結合はここでは行われない」ということです。
「???」って感じですね。安心してください。
リレーションシップは既存機能の変更や置き換えではなく「機能の追加」です。
過去の数字が急にバグることもないし、見て見ぬ振りして従来の結合やユニオンやブレンドで貫き通すことも可能です。
ただ、リレーションシップは本当に画期的な機能ですので、みなさんも必要な場面では積極的に使用されることを推奨します。今回はそんなリレーションシップの魅力の解説が行えればと思います。
============================================================
● リレーションシップが可能にした「集計結合」
繰り返しますが、リレーションシップになっても、従来の結合やブレンド、ユニオン、カスタムSQLなどは全て使えます。
見慣れた下のような画面に遷移することも可能です。
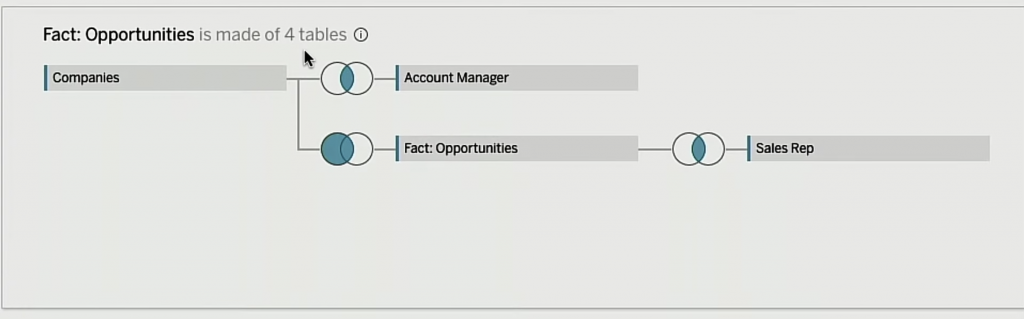
リレーションシップの効果が使えるのは、下図の様にリレーションを結んだ場合です。
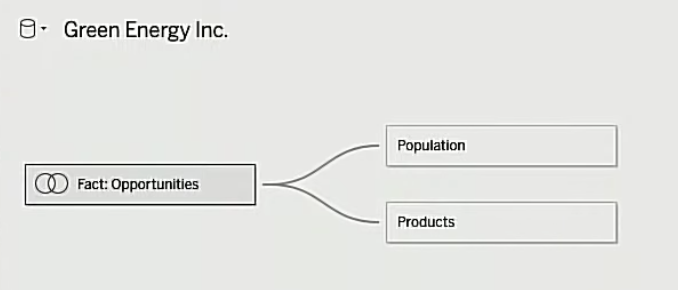
では、リレーションで何が出来るようになったのでしょうか。従来の結合とは何が違うのでしょうか。
答えはリレーションは「集計結合を使う」という点です。従来の結合を使った時のように「結合してから集計する」処理を行うのではなく「集計してから結合する」処理を行います。
説明します。
例えば、以下のデータで「サイトごとの目標達成率(売上÷目標)」を見たいときどうしますか?
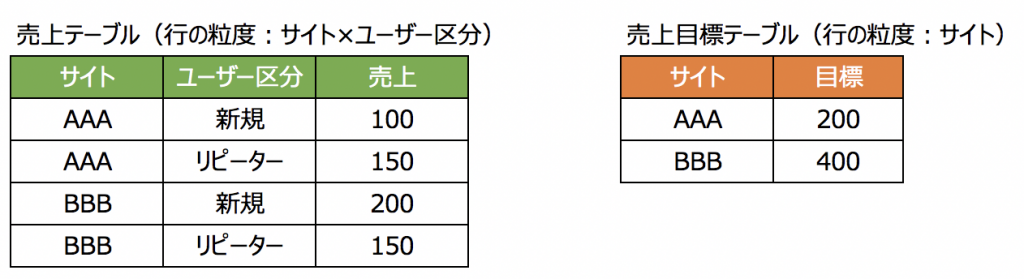
<従来の結合を使う場合>
まずは従来の結合を使う場合で考えます。
多分、以下のように「結合してから集計」で結果を出すと思います。
無事出せました。
ただ、目標達成率の計算フィールドを見てください。

分母である「目標」列の集計方法が少し複雑ですね。
「サイトごとの目標の合計」が出したい数字なのに、なぜMAXとかFIXEDとかが出てくるのでしょうか。
その理由は、最初の結合の結果、「目標」列の値が繰り返されてしまったからです。
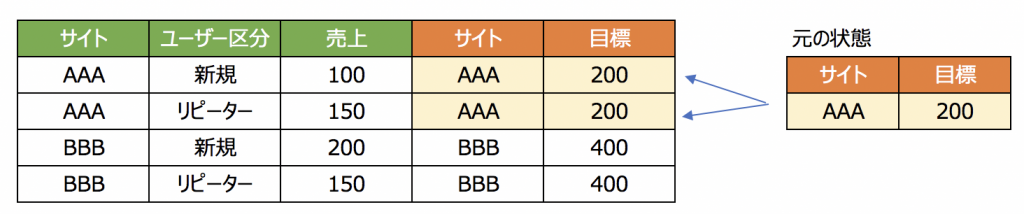
そのため「この状況を踏まえて集計関数を組まざるをえない」状況です。
そこで、「最大値で使う」「FIXEDで繰り返しを排除する」などの方向になり、計算が複雑になっている訳です。
これ、頭を悩ます方も少なくないのではないでしょうか。結合により生じた繰り返しに気づかず「合計したら値が倍になっていました・・・」みたいなことは、TableauだけでなくSQLや他BIでもよく起こる「集計ミスあるある」の一つです。
ところがそんな「集計ミスあるある」をTableauは放置しませんでした。
今回Tableauがリレーションシップで可能にした「集計結合」は、そんな悩みを解放する仕組みです。
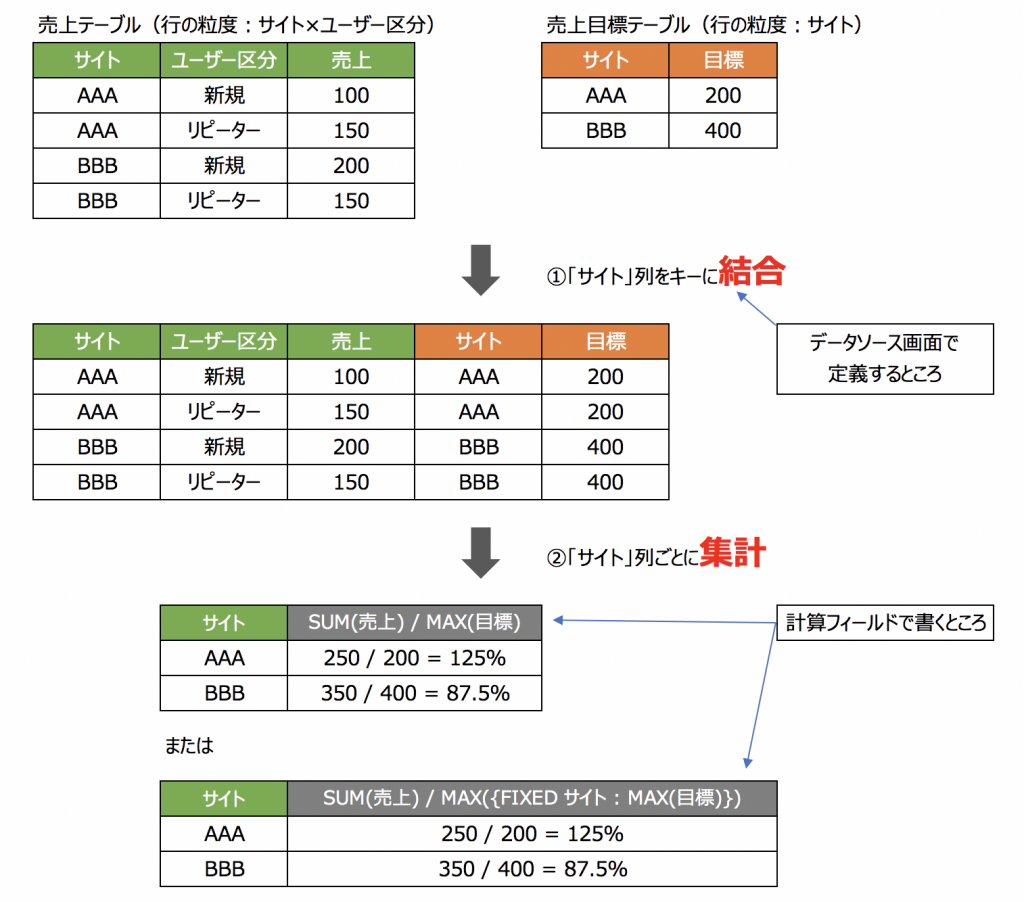
<集計結合の場合>
「結合の値の繰り返しによって集計が複雑になるのなら、値の繰り返しが起こる前に集計してしまおう」というのが「集計結合」のアプローチです。集計結合では、各ソースを元テーブルの状態の時点で集計してから結合するため、「結合前のテーブルの状態に対する集計方法を選べば良い」のです。
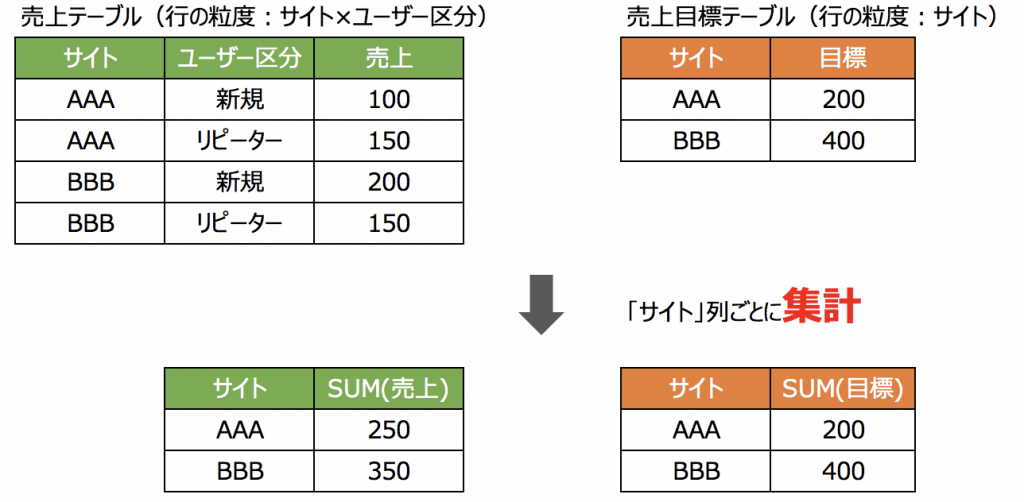
今回でいうと、結合前のテーブルの状態はこれです。
この状態でサイトごとの売上と目標の合計を出せば良いわけです。
つまり、サイトごとに、SUM(売上) / SUM(目標) で良いわけです。
さっきと比べるとはるかにシンプルですね。
集計後の結合はリレーションで定義されたキーを使ってTableauが行います。
こんな感じです。
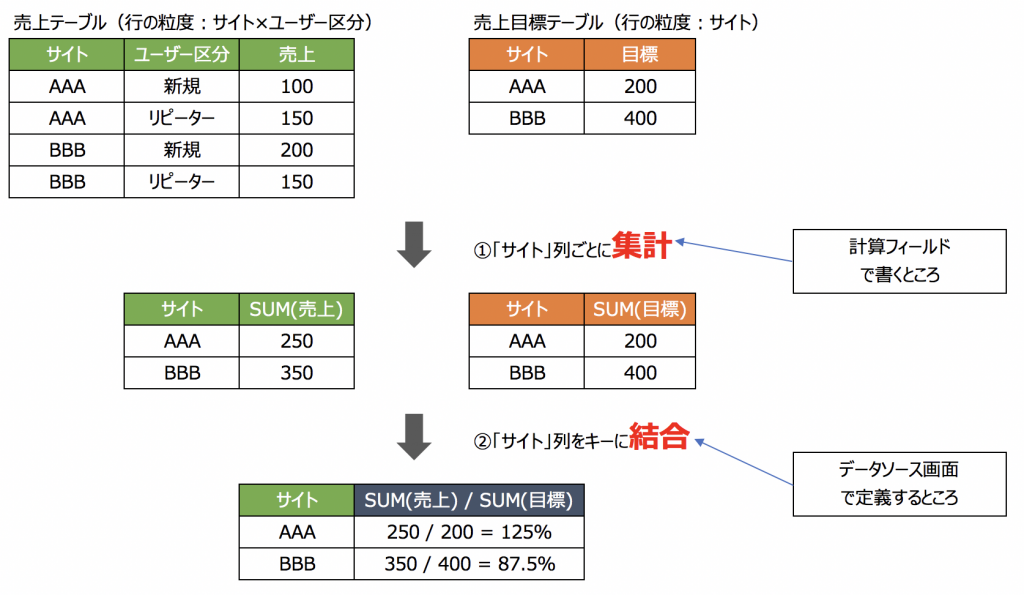
ものすごく簡単です。
リレーションシップを使う限り「行の粒度は今どうなってるんだっけ・・・」とは考える必要はありません。
「集計結合」によってデータの取り扱いをより直感的に行える様になります。
============================================================
● リレーションシップのパフォーマンスへの効果
リレーションシップのメリットは、これだけではありません。
パフォーマンス面でも大きな効果を発揮します。
リレーションシップでは、結合が必要なグラフ(シート)でしか集計結合を行わないのです。
従来の、結合が定義されていたら全てのシートで結合を行う処理とは大きく異なります。
例えばさっきのこの2つのテーブルを置いて、リレーションをサイト列で定義したとします。
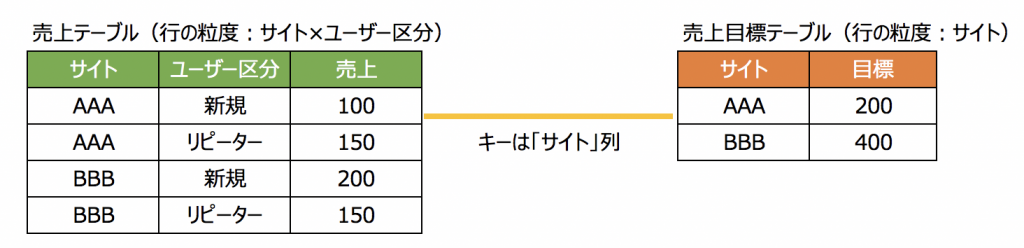
ではこのデータソースを用いて、「サイト×ユーザー区分ごとの売上」を出してみましょう。
これは売上テーブルだけの情報で出せますね。
であればTableauは結合を行いません。売上テーブルに対してクエリを発行して結果を出すだけです。当然逆も然り。
でも、「売上目標達成率(売上÷目標)」のような、「テーブルを跨ぐ必要がある場合のみ」Tableauは集計結合を行なって値を算出します。ここら辺の判断は、描画で使用されている列からTableauが論理的に判断してくれます。
これによって余分な結合処理が行われなくなるため、パフォーマンス面でのメリットを享受することができます。
ちなみに上記の特徴を少し応用すると、一見ジャンルの違う色々なテーブルを1つのデータソースに入れても良いわけです。
例えば行の粒度が全く違う「広告出稿テーブル」と「店舗売上テーブル」の2つを入れて、「日付」でリレーション組みます。広告の分析は広告のテーブルだけ、店舗の分析は店舗のテーブルだけにクエリが発行されるので、お互いに影響を与えません。日別で広告出稿量と売上を重ねるグラフを作った時だけ、両方のテーブルにクエリが発行され、集計結合してくれるのです。
「データソースやデータマートの数を激減させることが出来るので管理やメンテナンスが行いやすくなる」
これもリレーションシップのメリットと言えるでしょう。
============================================================
リレーションシップの使用方法
では、リレーションシップはどのように使うのでしょうか。
具体的には以下の2ステップになります。
①必要なソースを配置する。
②各ソースを紐づける際のリレーションを定義する。
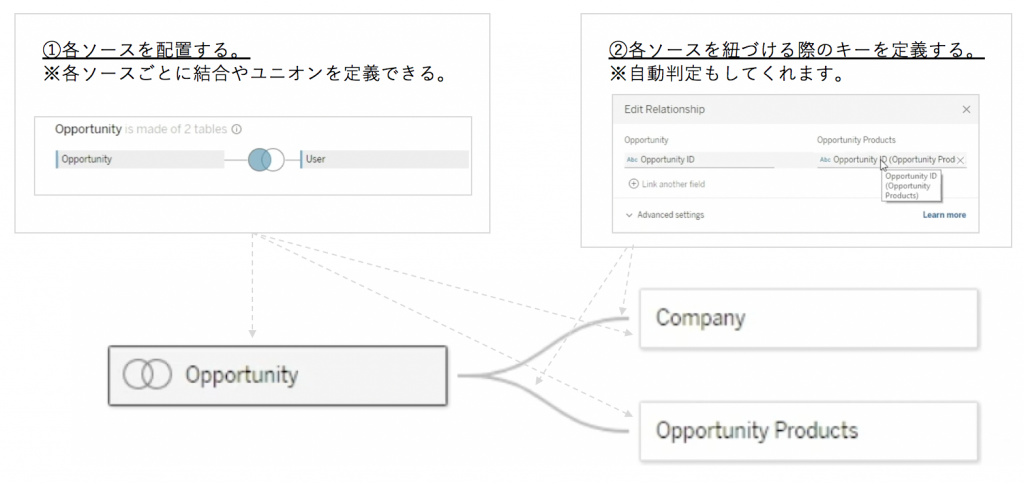
①も②もこれまでのUIと少しだけ似ていますが、内容は結構違います。
①は従来「物理テーブル」でしたが、リレーションシップでは「論理テーブル」です。結合やユニオンが各ソース単位で定義出来ます。
②は従来「結合方法と結合キー」を定義しましたが、リレーションシップでは「結合方法を定義しません。」どの結合方法が使用されるかどうかは、シートで使用されているディメンションやメジャーに基づいて判定されます。
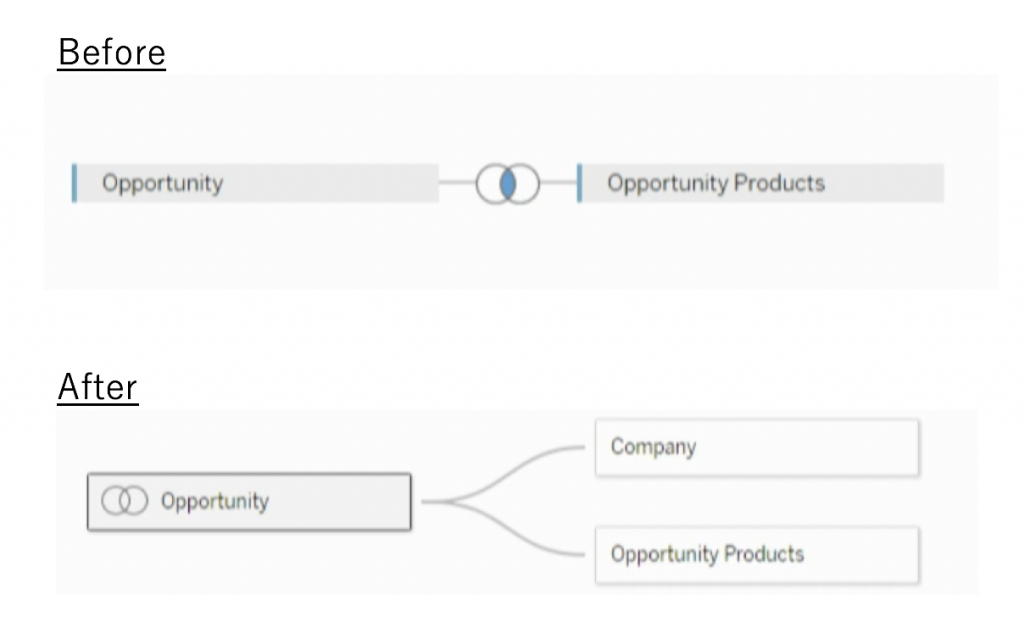
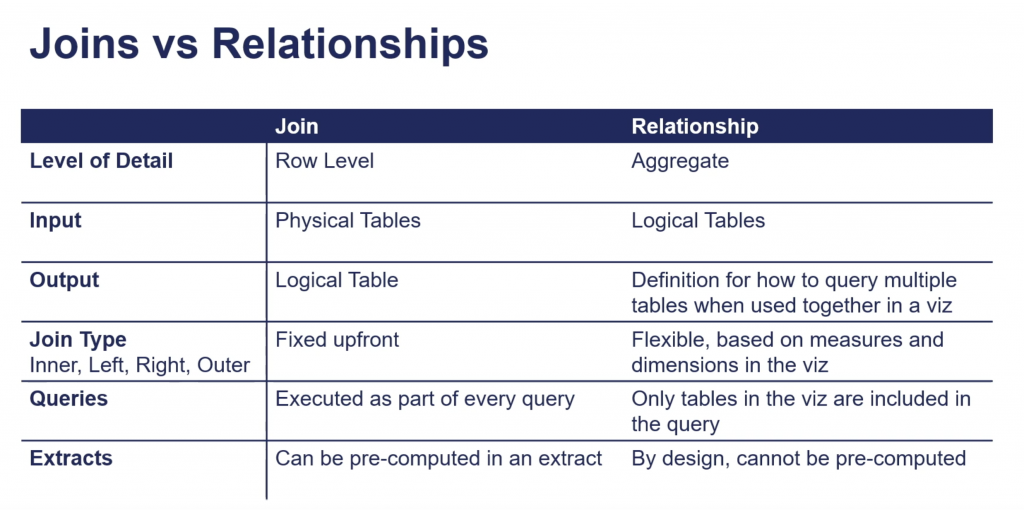
上記セッションでは従来のJOINとリレーションシップの違いを下記のようにまとめています。
================================================================
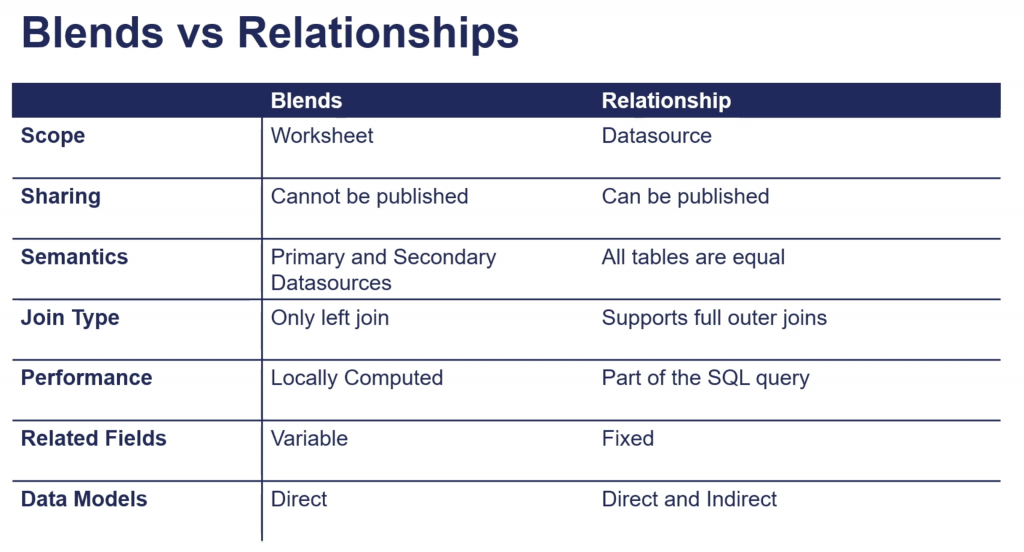
備考:リレーションシップと「ブレンド」との違い
ここまでみて、「これってブレンドみたいなもの?」となるかもしれません。
正解です。ブレンドもリレーションシップのように「集計結合」が出来るし、「必要な時だけ勝手に結合」をします。似てますね。
ただ、今回のリレーションシップは「ブレンドの上位互換」と考えて良いと思います。
ブレンドはセカンダリソースに多くの制約があったり、ローカル処理のため処理スピードに限界があったりします。
ただし、リレーションシップでは、
・各ソースにプライマリ/セカンダリという概念がなく、どのソースも平等に扱える
・集計後の結合をSQLの一部で行える(DB側で処理できる)
・LEFT JOIN / INNER JOIN / FULL JOIN問わず使用できる
というメリットがあり、ブレンドの物足りない点を補っています。
上記セッションではブレンドとの比較を下記のようにまとめています。
================================================================
以上がリレーションシップの解説になります。魅力は伝わりきったでしょうか。
これで興味を持ち、英語に抵抗がなく、50分の尺に耐えられる勉強熱心な方は是非
https://youtu.be/ndLL_yY0FZ4
を見てください。ここでは挙げきれていないリレーションシップの魅力やより実践的な使い方を、遥かにわかりやすい説明で受けることが出来ます。
また、Pre-Releaseプログラムに参加して実際に触ってみることも出来ます。
興味がある方は、是非実際に手を動かして触ってみてください。
また、ミスリードがないようしっかり理解した上で書いているつもりですが、もし現時点での誤りを見つけた場合、大変お手数ですがブログのリクエストフォーム から教えて頂けるとありがたいです。。
エクスチュアはTableau・GCP・AWSなどを用いたデータ分析環境の構築支援を行なっています。
問い合わせはこちらまで










