Looker: エンジニアがBIで分析ダッシュボードを作る

こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
今回はBIツール「Looker」についてです。
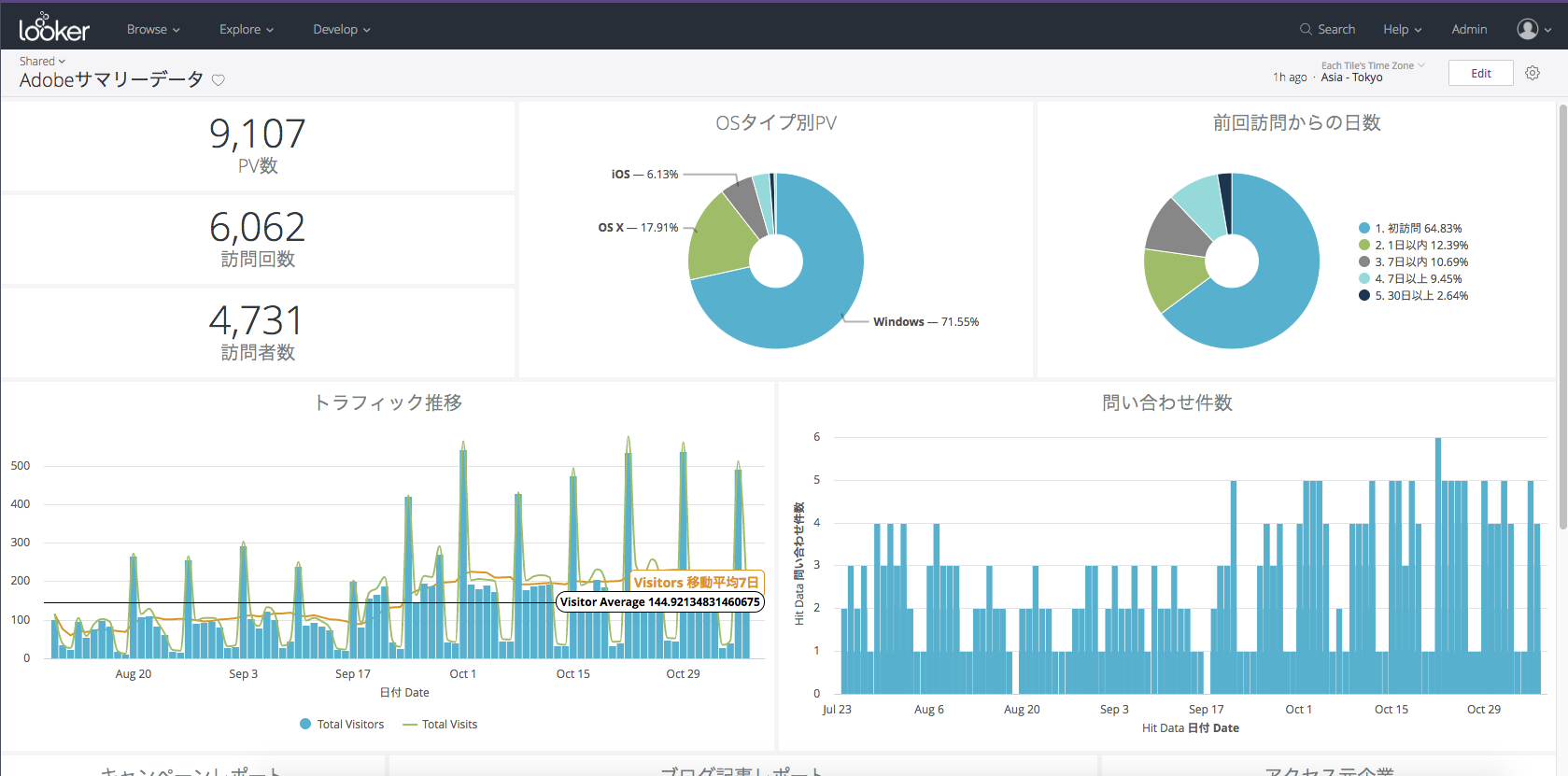
Lookerとは、「エンジニア向けBI」とでも言えるBIツール。
LookMLというマークアップ記述を使ってディメンションと指標を定義した上でビジュアライズを行うという、とても渋いBIツールです。
「マウスで管理画面ポチポチ系」の作業が苦手で大嫌いな私にとっては、まさにGame Changerというか「これだよこれ」というべきBIです。
「オラBigQuery大好きエンジニアだけど可視化はお絵書きセンスねーからよく分かんねーづら」と日和見してる場合ではありません。
そんなLookerって何よ?という方のためにちょっとだけ特徴を紹介します。
1. Lookerにはデータストレージがない
なんと、Lookerはストレージ領域を持っていない。
じゃ、どうするか?
すでに構築されてる自前のDWH/DBに接続して、そこからデータを持ってきます。
弊社はBigQuery大好き人間が集まっているので、常日頃からGA360のBigQueryエクスポートデータと、AdobeのデータフィードをBigQueryにロードしてから弄り回しております。
そしてLookerはまさに「そこ」に接続します。
キャッシュなどの一時的なデータを記録するためのデータセットもBigQuery内に作ります。
もちろんRedshiftなどの他のDWH/DBにも対応してます。弊社はBigQuery一択。
2. データの定義は管理者がLookMLで行う
プロジェクトを作成して、BigQueryからデータセットを取り込むと、「モデル」と呼ばれるグループが出来上がり、
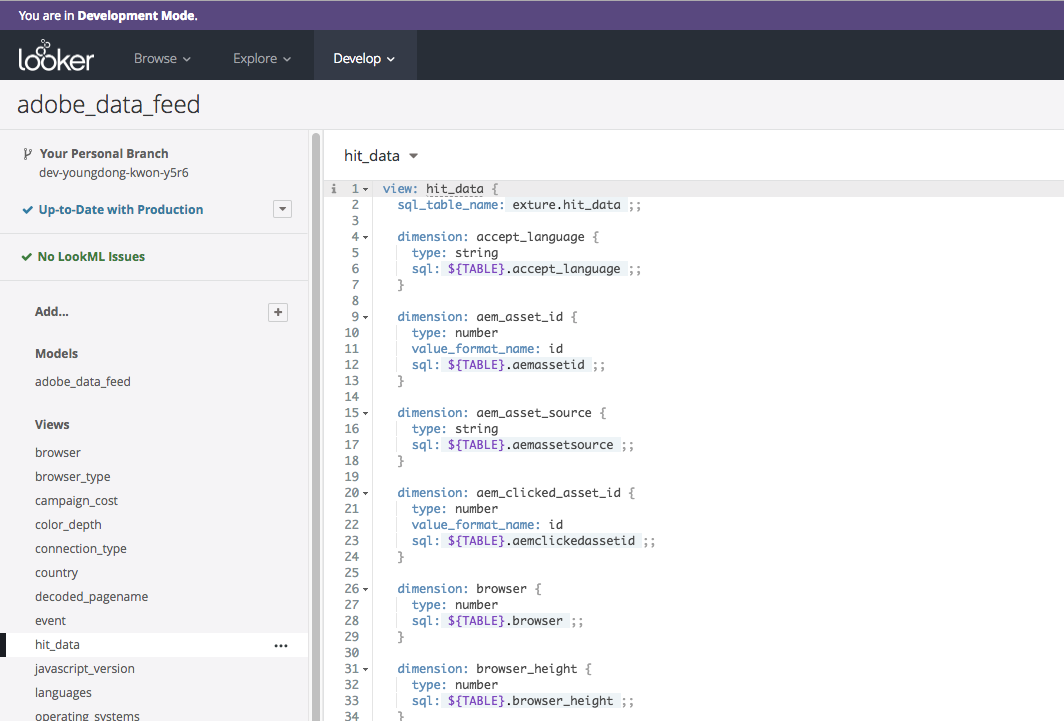
そのモデル内には「ビュー」と呼ばれる各テーブルのカラムを元にしたディメンションと指標がLookMLで定義されます。
hit_dataのビューはLookMLでこのようになります。
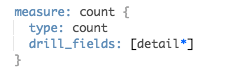
各ビューにはデフォルトで「カウント」というデフォルト指標が存在します。
行数をCOUNTするだけの指標です。
ではAdobeで言う「訪問回数」と「実訪問者数」はどうすれば良いか?
ついでに、クリックを除外した「ページビュー数」は?
これらはLookMLで定義します。
LookMLの編集は、Developmentモードという編集モードに入ってから行います。
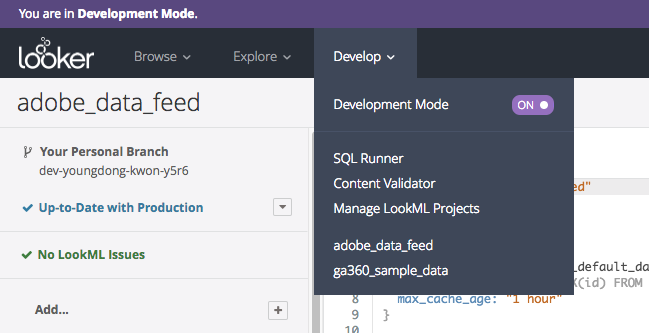
Developmentモードで編集した内容は、Production環境にデプロイするまでは他のユーザーには一切影響はありません。
まずは訪問者と訪問回数の根拠となるIDを作ります。
post_visid_highとpost_visid_lowを結合して、post_visitor_idというディメンションを作ります。
さらに、それらにvisit_numを結合したsession_idというディメンションも作成します。
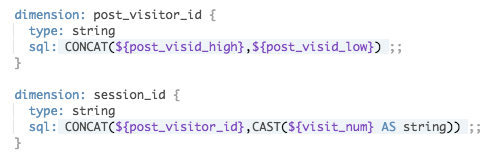
そして、これらのIDをCOUNT DISTINCTします。
filtersパラメータを使って、exclude_hitが0のものだけにします。
ページビューはさらにpost_page_eventが0のものに絞ります。

あらかじめこのようにフィルターをかけた指標を定義することで、ダッシュボードを作る人がバラバラの指標を作らなくて済みます。
また、LookMLはプロジェクト毎にGitで管理します。
複数の管理者がいる場合は、それぞれにブランチが自動的に作成されます。
Gitレポジトリは、GitHubやGitLab、Bitbucketなどのものが使えます。
しかし弊社でよく使ってるGoogle Cloud Source Repositoriesには未対応でした。。
3. 複数テーブルのJOINも簡単
広告コストデータをインポートしたテーブルを用意して、それをAdobeのデータフィードとJOINしたい。
これもLookMLで簡単に出来ます。
AdobeAnalyticsで言うところの数値型SAINTとDataSourcesをかけたようなものですね。

4. データを定義したらあとはExplore
データを定義したあとは、いきなりダッシュボードを作るのではなく、Explore機能を使って各データを抽出して、そして可視化して行きます。
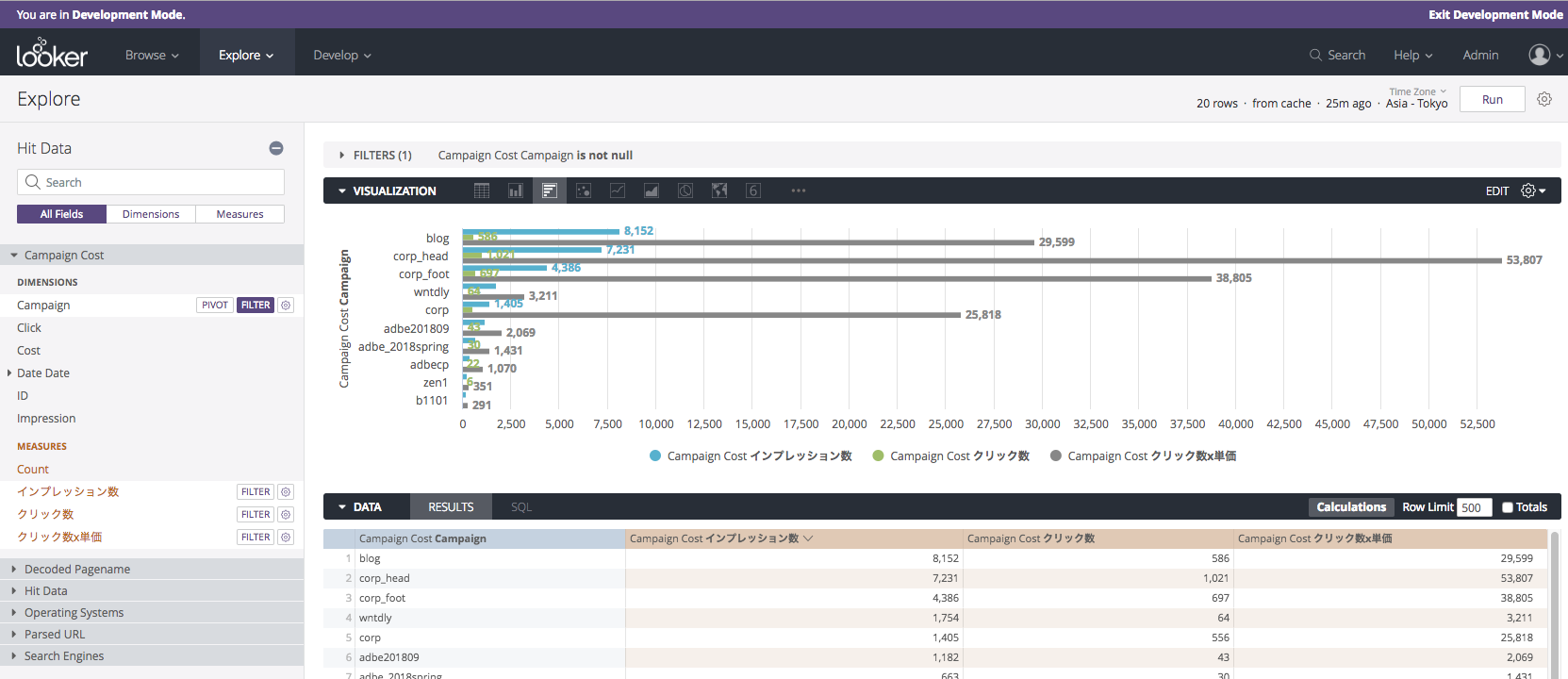
例えば「訪問者数の7日移動平均」なども、イチイチSQLを書かなくてもLookerがバックグラウンドで動的に生成したSQLで取り出したデータを元に描画します。
つまり、データを分析する人はワザワザSQLを書く必要はありません。
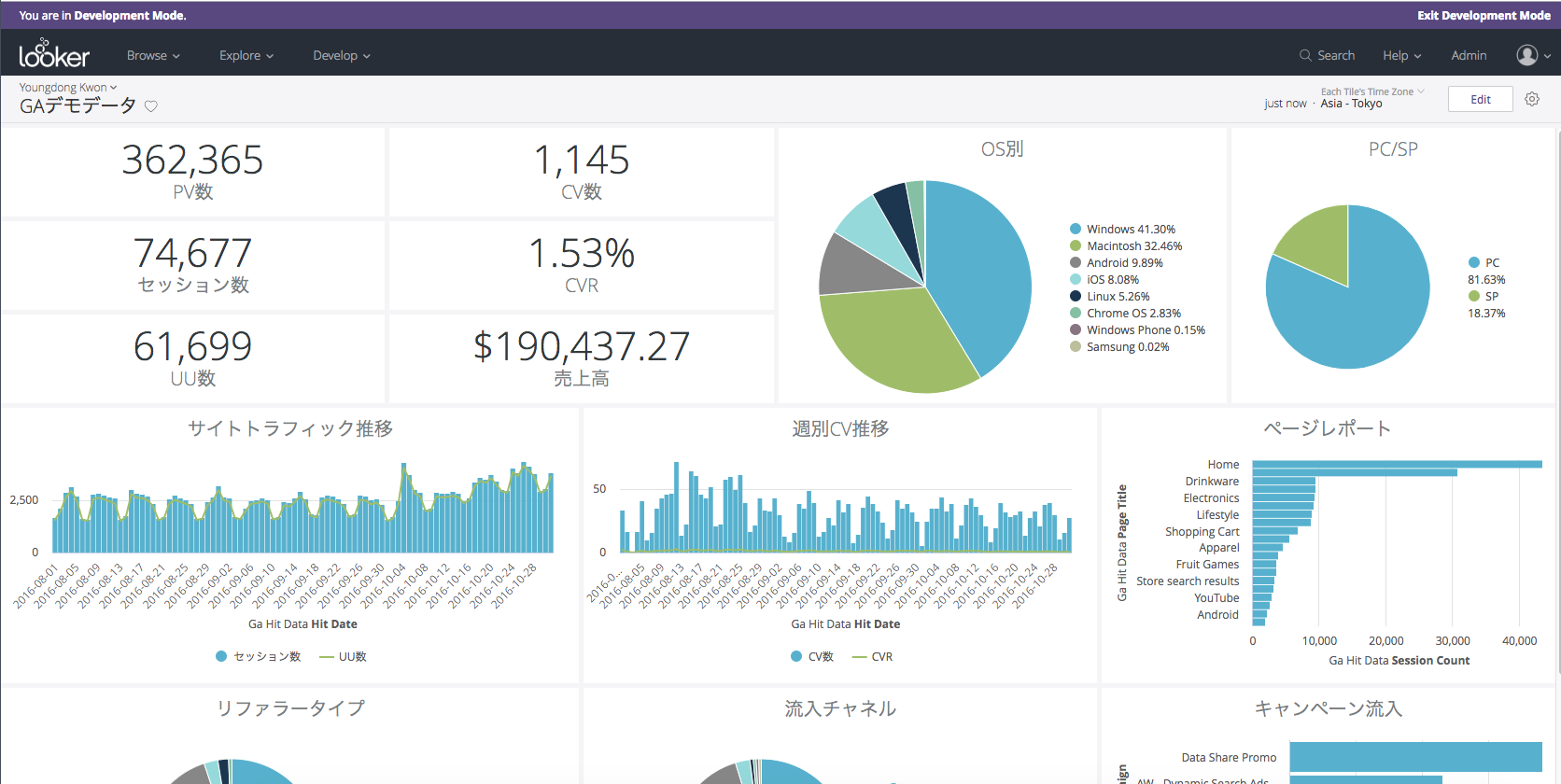
データ抽出した結果のビジュアライゼーション要素は、「Look」と呼ばれるタイルとして保存していきます。
そして最後にこれらのLookタイルを並べればダッシュボードが出来上がります。
まとめ
Lookerのデータ定義はマークアップ記述によって行われますが、データ抽出・ダッシュボード作成はGUIから簡単に行なえます。
社内にダッシュボードやレポートが氾濫していて、データや指標の定義がバラバラなんていう「データの無政府状態」に頭を抱える必要もありません。
今後このブログでもLookerを使った分析Tips等を随時載せて行きます。
弊社ではLooker以外にも、TableauやDomo、GoogleデータポータルなどのBIツールを使って、Adobe/GAなどのWeb解析データと、CRMデータやDWHなどのデータを統合したデータ分析基盤構築サービスを行っております。
お問い合わせはこちらからどうぞ。
ブログへの記事リクエストはこちらまで




