こんにちは。エクスチュアでインターンをさせて頂いている中野智基です。
今回の投稿から複数回に分けて、Google Cloud Platform(以下GCP)の機能の一つであるBQMLについて記事を書いていきたいと思います。
昨今、日本中で話題の機械学習ですが、BQMLを用いればPythonのコードがかけなくても簡単なSQLの知識だけで機械学習を行うことができます。
私はML勉強中の身ですが、自ら学んだ知識などをこの記事にまとめていく所存です!!
どうせなので、GCP上の各機能を連動させながらBQMLを使っていきたいと思います。
みなさんのお役に立てれば光栄です。
以下が目次です。
こんな感じの流れで記事を書いていくつもりです。
目次
第1回:GCPの機能を連動させて、BQMLを用いてKaggleコンペに挑む
第2回:Source Repositoryを用いてGCE上でPythonコードを実行し、BQMLと精度比較をする
第3回:Dataprepやpandasでデータ整形をした上で、PythonとBQMLの精度比較をする
番外編:新機能のk-means法をはじめとする、ここまでで触れなかったBQML機能の紹介
前提とする知識
この「GCPのBQMLを使ってKaggleコンペに挑んでみた」シリーズでは、
・gitの仕組みや使い方
・Linuxコマンド
・SQLの書き方
・GCPアカウントの発行の仕方
・GCP各機能の初歩的な使い方(ex. GCEにどう接続するか等)
などの基本的な知識は所与のものとして扱います。なので、そうした知識については解説いたしません。
ただし、用いたコードなどは全て載せるので、分からない部分は適宜ググるなどして調べていただきたいです。
なお、最適化されたコードとは限らないのでご注意ください。
第1回:GCPの機能を連動させて、BQMLを用いてKaggleコンペに挑む
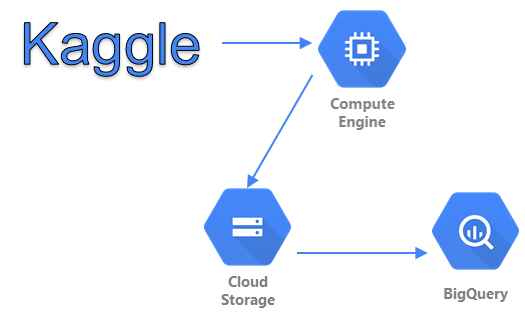
今回の記事では、
①:GCE(Google Compute Engine)を用いて、Kaggleからデータを取得する。
②:取得したデータをGCEからGCS(Google Cloud Storage)に移す。
③:GCSからBQ(BigQuery)にデータを移し、テーブルを作成する。
④:BQ上で機械学習を実行する。(BQMLの実行)
という流れで分析を行っていきます。
Kaggleからデータを取得する
Kaggleというのは、世界規模で機械学習のコンペが行われているコミュニティーです。
予測結果の上位には賞金が出ることも多く、世界中から優秀なデータサイエンティストがこぞって参加しています。
また、そうした方たちがデータ分析の方法を共有してくれているページもあるので、ぜひ見てみてください。
ここでは、GCEから「kaggle」コマンドを用いてデータを取得します。
ローカルに保存する必要がないので、容量の大きいデータを自機にダウンロードしたくない人には向いています。
ただし、「こんなことするのは面倒くさい。BQMLの機能だけ見てみたい。」という人は、もちろんローカルでダウンロードしても問題ありません。
そういう人は、ここからの部分を全部すっ飛ばしても大丈夫です。(こちらのリンクをクリックしてください。)
ではまず、GCEのインスタンスを立てましょう。
ここで注意するべきポイントは2つです。
(1):適切なマシンタイプを選択する
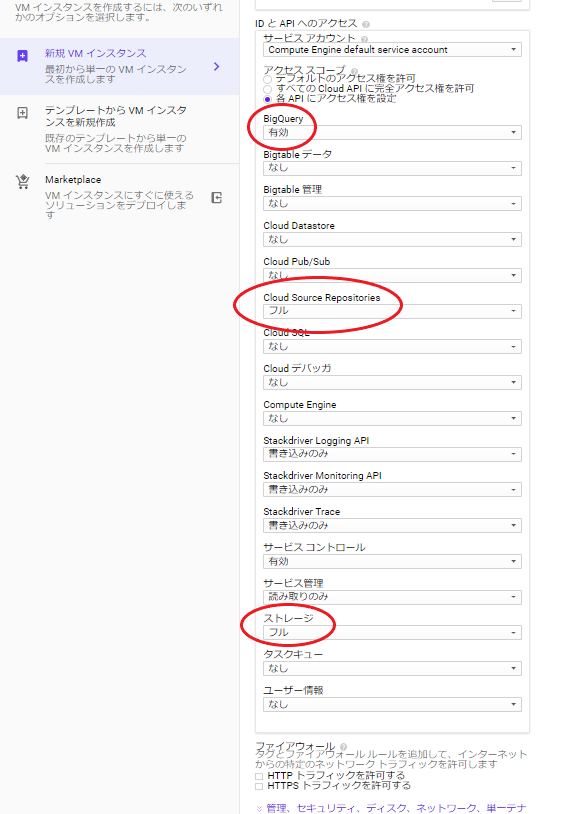
(2):GCEに、他のサービスへのアクセス権を付与しておく
(1)では、機械学習で用いたいデータの容量を考えて、メモリの大きさなどを決めましょう。
(2)では、この後用いるGCS、Source Repository(今回は使わないが、次回以降に用いる)、BQのアクセス権を付与しておきましょう。
以下、参考画像です。
(マシンタイプは、第二回以降で容量の大きいデータを扱うので「n1-highmem-16(vCPU x 16、メモリ 104 GB)」とかがお勧めです。)
GCEのインスタンスが立てられたら、今後使っていくコマンドのための環境設定を行います。
接続方法はなんでもよいので(一番簡単なのは、画面上の「SSH」ボタンを押すこと)、まずはGCEに接続しましょう。
今後は、このGCE上にコードを入力して実行していきます。
このシリーズで必要となるコマンドは、
・pip
・git
・kaggle
です。pipとgitは、
apt-get install python3-pip apt-get install git
でインストールできます。
(権限の問題でGCE上でコードが実行できない場合は、文頭に「sudo」を追加すると解決するかもしれません。)
kaggleコマンドを使うには、APIトークンを発行しなければならないので、まずはkaggleにユーザー登録しましょう。
登録が完了したら、My Accountページで「create API token」をクリックし、jsonファイルをダウンロードします。
そうしたら、GCSにjsonファイルをアップロードしましょう。ここは手作業で行います。
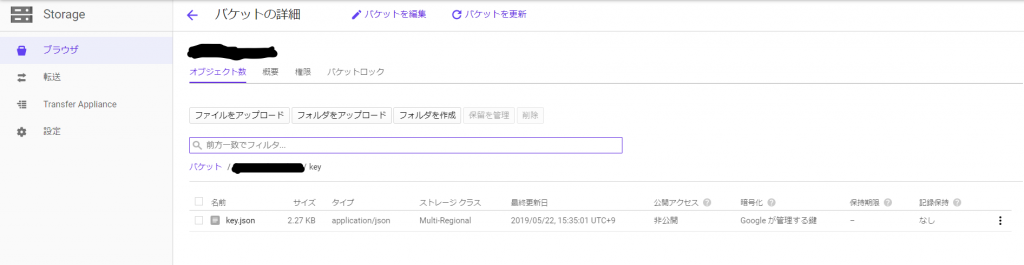
こんな感じでGCS上にデータを入れてください。
次に、kaggleコマンドを使うためにはGCE上で「.kaggle/kaggle.json」というファイル配置になっている必要があるので、そのための操作をします。
以下がそのコマンドです。
フォルダーを生成し、jsonファイルをGCSからGCEに移します。
「gsutil」はGCSを操作するコマンドです。
そしてkaggleコマンドをpipでインストールします。
(特に説明はしていませんが、GCE上のファイル構造には注意してください。パスの問題でエラーが吐かれることもあるかもしれないので。
また、コード上で大文字になっている部分は、自分自身の情報を入力してください。)
mkdir .kaggle gsutil cp gs://YOUR_PROJECT_NAME/kaggle.json ./.kaggle pip3 install kaggle
ここまで行って、ようやくkaggleからデータをGCE経由でダウンロードできるようになりました。
では、「kaggle」コマンドを用いてデータをダウンロードしましょう。
今回は、kaggleのチュートリアルとして紹介されているタイタニック号のデータを用います。
(参照リンク:https://www.kaggle.com/c/titanic)
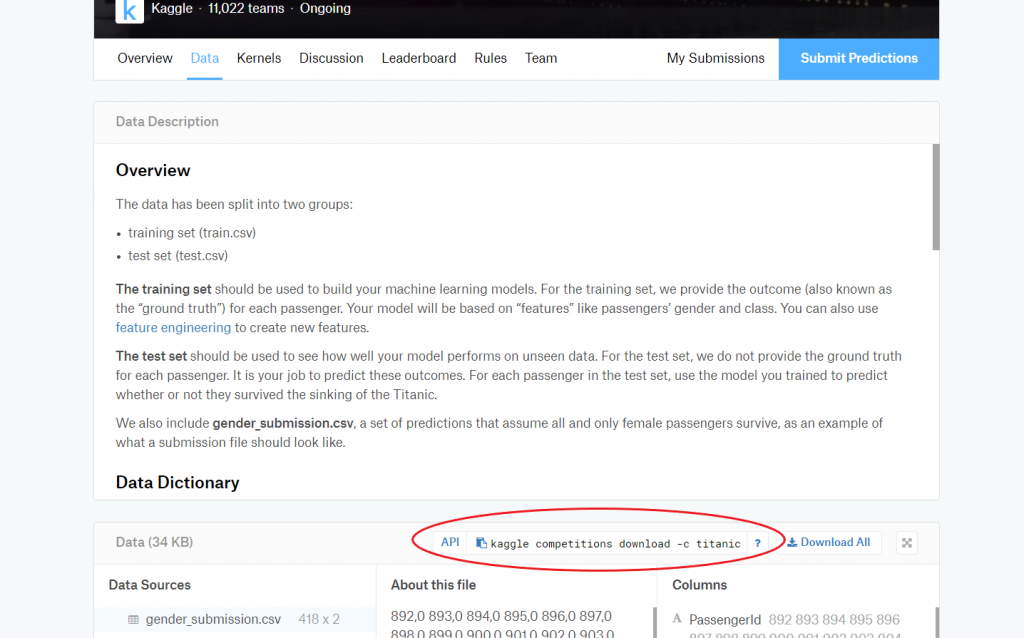
上の画像の赤線で囲まれた部分をコピーしてください。クリックするとコピーできます。
コピーが完了したら、それを貼り付けてGCE上で実行しましょう。
今回の場合は、
kaggle competitions download -c titanic
となります。
取得したデータをGCSに移す
無事にデータをダウンロード出来たら、それをGCSに移しましょう。
もちろん、GCEから直接BQにデータを入れることもできるのですが、今回は諸々の事情でこの手続きを踏んでいます。
(SQL以外の言語を用いる必要性が生まれるため)
データを移す操作は、先ほども出てきた「gsutil」コマンドで実行できます。
これはGCSを扱うためのコマンドでしたね。
先ほどとは異なり、今回はGCE → GCSという風にデータを移します。
コードは以下の通りです。
gsutil cp DOWNLOAD_FILE_NAME gs://YOUR_PROJECT_NAME/YOUR_REPOSITORY_NAME/
ここで注意しておきたいのは、機械学習を行う際にはトレーニングデータとテストデータが必要だという点です。
おそらく、GCEの中には
①:train.csv
②:test.csv
③:gender_submission.csv
という3種類のファイルがダウンロードされていることでしょう。
今回は、①と②の2つをGCSに移してください。
トレーニングデータを分割してモデル精度を測る方法もありますが、今回はテストデータを用います。
(SQL以外の…以下略)
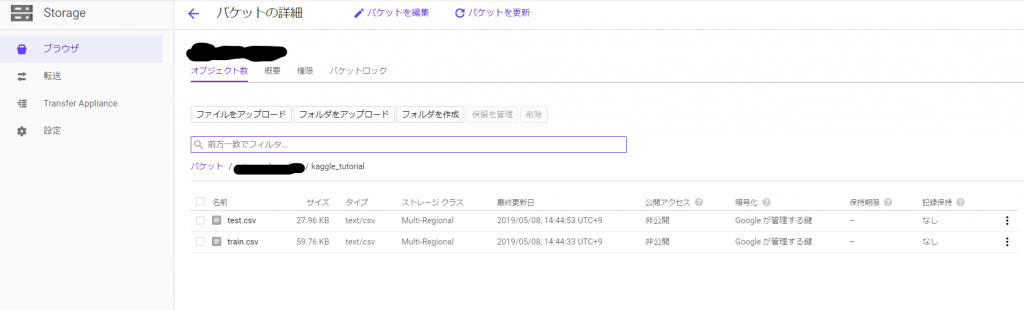
こんな感じでデータが移せれば成功です。
GCSからBQにデータを移し、テーブルを作成する
ここからは、BQのインタフェースを用いていきます。
GCEの料金体系は従量課金制なので、使っていない間はインスタンスを停止しておきましょう。第1回では、これ以降にGCEを用いることはないので、とりあえずインスタンスを停止することをお勧めします。
さて、では早速BQ上にテーブルを作成していきましょう。
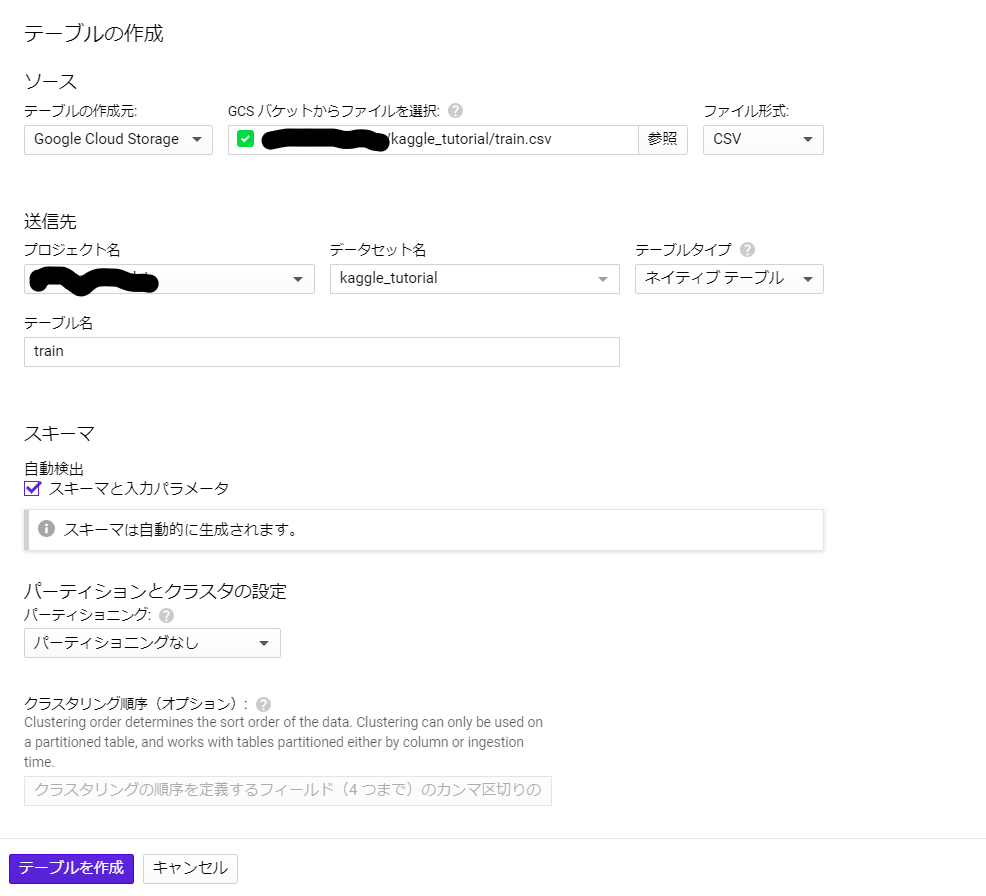
まず、適当な名前でデータセットを作ります。今回は「kaggle_tutorial」とします。
次に、「kaggle_tutorial」に「train」テーブルと「test」テーブルを追加しましょう。
データセットをクリックすると、「テーブルを作成」というボタンが出てくるので、そこをクリックしましょう。
GCSのデータを選択してテーブルを作成する手順は、以下の画像の通りです。
(ローカルにデータをダウンロードした人は、「テーブルの作成元」を選択するときに「アップロード」を選んでください)
テーブルを作成したら、BQ上でデータを確認してみましょう。
テーブル名をクリックして、プレビューボタンを押すことでデータの情報が可視化されます。
もちろん、SQLを用いてこのデータを分析・加工することもできます。
が、今回は何もせずにただBQMLのモデルに突っ込んでみたいと思います。
そうしたデータの前処理の話は、第3回に行うつもりです。興味がある人は、そちらを見てみてください。
以下が、今回使うタイタニック号のトレーニングデータです。
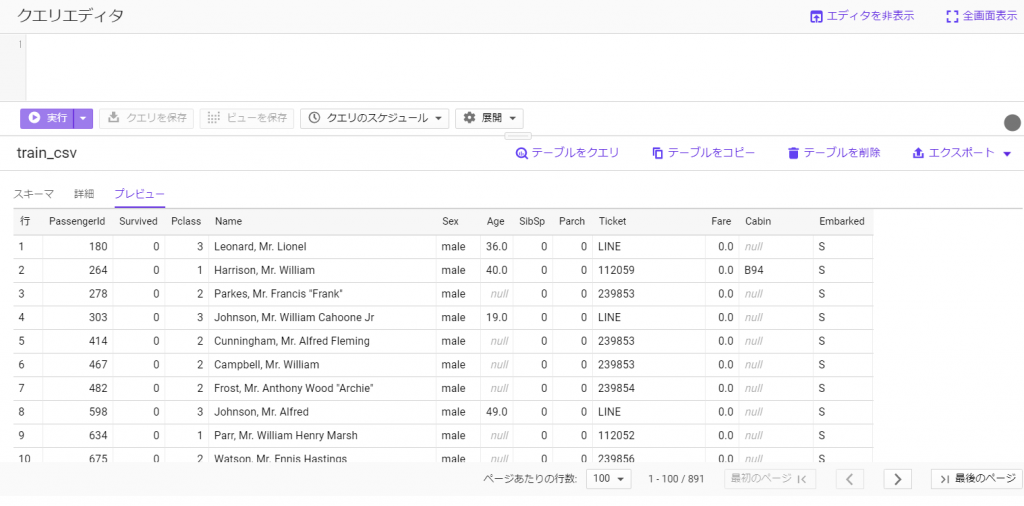
BQMLを実行する
ついにBQにテーブルを作成することができました。
まあ今回の例では、ローカルにダウンロードしてそれを直接BQに投げれば一瞬で終わる話だったのですが…。
では、本題でもあるBQMLを使っていきましょう。
基本的にBQMLの手順は、
①:モデルを作成する
②:トレーニング情報を確認する
③:作成したモデルを用いて、未知の結果を予測する
という3段階になっています。
まず、モデルを作成していきます。
BQML用のクエリを書いていきましょう。
create or replace model `YOUR_PROJECT_NAME.kaggle_tutorial.model` options(model_type='logistic_reg', input_label_cols=["Survived"]) as select PassengerId, Survived, Pclass, Name, Sex, Age, SibSp, Parch, Ticket, Fare, Cabin, Embarked from `YOUR_PROJECT_NAME.kaggle_tutorial.train_csv`
「model_type = ‘logistic_reg’」で今回のモデルはロジスティック回帰のモデルであること、「input_label_cols=[“Survived”]」で目的変数は[“Survived”]であることを定義しています。BQ上のカラム名を正確に書かないとエラーが出るので、注意してください。
(補足:ロジスティック回帰は、複数のクラスの中から該当するクラスを予測する際に使います。今回の例だと、タイタニック号に乗っていたその乗客が生存できたのかということを予測します。なので、今回は二値予測ですね。
逆に線形回帰は、数値の予測に使います。これは第2回以降の例で用いますが、企業の売り上げや電力需要などの定量的な値を予測します。)
説明変数に対して何の加工もせずに全てをぶち込む暴挙に走っているのは、今回は多めに見てください…。
このクエリを実行すると、データセットの中にモデルが作成されるかと思います。
(学習率などの詳細なパラメータも個別に設定はできるのですが、今回は省略しています。次回以降のどこかで紹介できればと思います。)
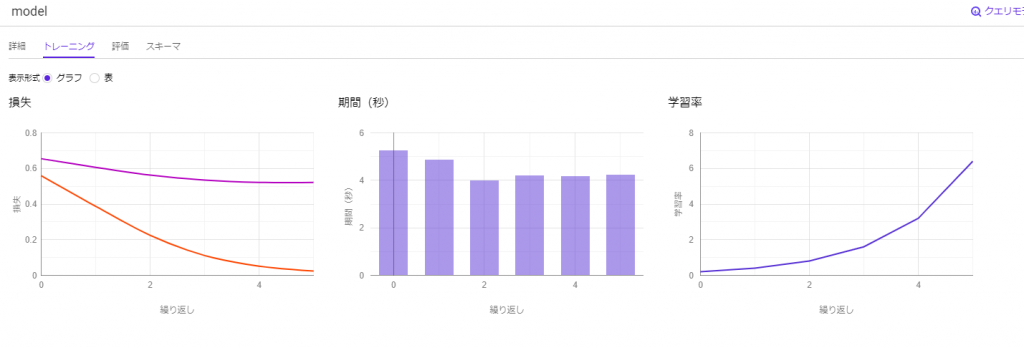
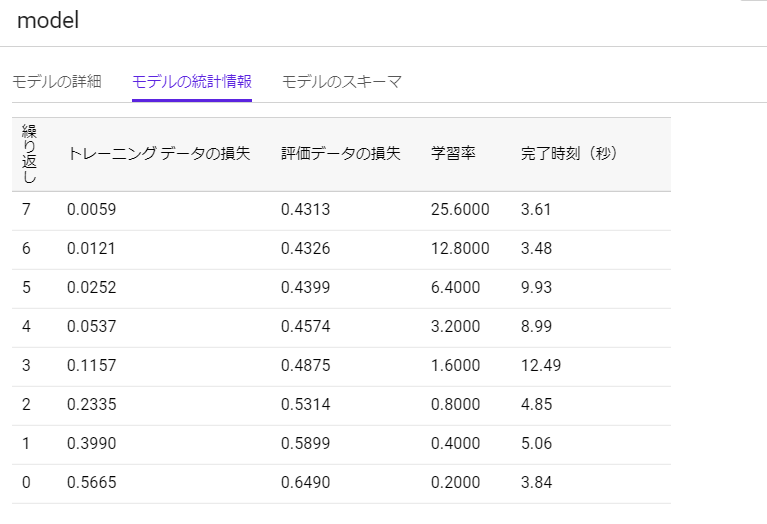
以下がモデルの情報です。
以前は損失や学習率がグラフとして可視化されていたのですが、いつの間にかこんな形式に変わったようです。
上が以前、下が今です。(下の画像は後で再度見返します。「モデル情報の画像」と言ったら、この画像のことです。)
では次に、モデルの評価をしていきましょう。
BQMLでは、内部でデータをトレーニング用とテスト用に分けて勝手にモデルを評価してくれています。
なので、上に貼ったような画像を見るだけでも十分モデルを評価することができます。
が、今回は自分でコードを書いてきちんと評価をしましょう。
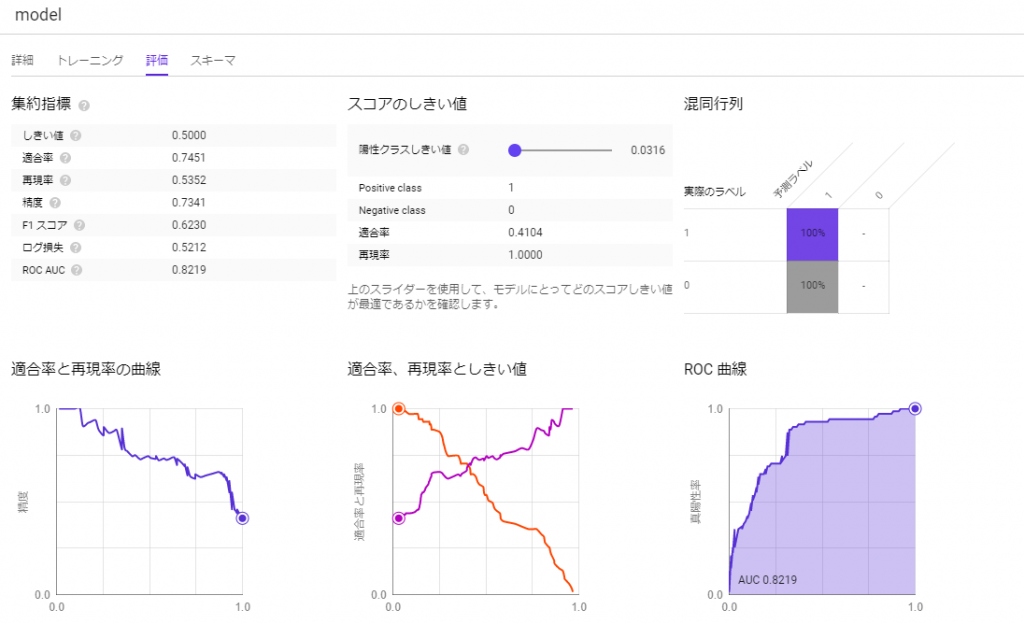
参考までに、以下の画像は以前までのBQMLで見れていた指標です。
今はこうした詳細な情報は見ることができないようです。
では、早速トレーニング情報を見ていきましょう。
以下が、モデルを評価するためのクエリです。
select * from ml.evaluate(model `YOUR_PROJECT_NAME.kaggle_tutorial.model`, (select PassengerId, Survived, Pclass, Name, Sex, Age, SibSp, Parch, Ticket, Fare, Cabin, Embarked from `YOUR_PROJECT_NAME.kaggle_tutorial.train_csv`))
このクエリを実行すると、以下のような結果が出てきます。

「log_loss」という値に着目してください。
これは、ロジスティック回帰における損失の値です。つまり、実際の結果と予測結果がどれだけ乖離しているのかを表しています。
しかし、「モデル情報の画像」を見ると、BQMLが出した指標とは大きく異なっていることが分かります。
これは、典型的な過学習が起きているためです。
つまり、作成したモデルはトレーニングデータそのものの特徴に依存しすぎてしまい、未知のデータに対してはここまでの高い精度は出せないということを意味しています。
元来、BQMLが内部で行ってくれているように、トレーニング用とテスト用に分けてモデルを評価するのが普通です。
それを今回は使用したデータでそのままモデルを評価してしまったため、このような事態が起きたのです。
参考までに、以下が自分でデータを分割した際のモデル情報です。
トレーニングデータに依存しないモデル自身の評価ができていることが分かるかと思います。

さて、それでは最後にテストデータの結果予測を行いましょう。
以下のクエリで実行できます。
select PassengerId, predicted_Survived as Survived from ml.predict(MODEL `YOUR_PROJECT_NAME.kaggle_tutorial.model`, TABLE `YOUR_PROJECT_NAME.kaggle_tutorial.test`) order by 1
テストデータの予測が完了したら、Kaggleに結果を提出してみましょう。
結果をCSVファイルでダウンロードし、それをCompetitionのSubmit Predictionで提出します。
ちなみに今回の結果は、「0.73205」でした。
なんとも言えないですね。はい。
まとめ
今回は、GCPを活用したBQMLの使い方を記事にしました。
次回は、Pythonで行った機械学習とBQMLの精度比較などを行います。
今回用いた機能に加えてSource Repositoryなども用いて、PythonなどのコードをGCE上で実行するということも行っていきたいと思います。
興味があれば、ぜひ次の記事も読んでみてください。
弊社はGCPなどを使った分析基盤の構築から、可視化・分析まで行う企業です。
お問い合わせはこちらまで。
ブログへの記事リクエストはこちらまで。












