Adobe Analytics: RSIDを間違えてしまったデータを正しいRSに入れ直す

こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
今回はAdobe Analytcsのフル処理データソース(Full Processing DataSource)についてです。
RSID(s_account)を間違えて開発RSのままでサイトを公開してしまって、本番サイトのデータを開発RSに送ってしまった場合の対処方法として、フル処理データソースを使います。
ほとんど使うことはない機能なのですが、知っておくと役に立つかも知れない機能です。
以下、手順です。
1. データフィードで誤って計測していた期間のデータを取り出す
2. hit_data.tsvをフル処理データソース用に加工する
3. データソースを作成する
4. FTPでデータソースファイルをアップロードする
1. データフィードで誤って計測していた期間のデータを取り出す
まずは、データフィードを使って、開発RSに入ってしまったraw dataをエクスポートします。
以前のブログエントリーで、データフィードをSFTPで配信する方法を書きましたので、データフィードの配信設定の作成方法については下記の記事を参考にしてください。
Adobe Analytics: データフィードをGoogle Compute EngineのLinuxインスタンスにSFTP転送する
データフィードで配信するカラムを絞る事もできるのですが、そこはcutコマンドで後ほどやりますので、とりあえず全1013カラムを取り出します。
2. hit_data.tsvをフル処理データソース用に加工する
データフィードのtar.gzファイルがSFTPに配信されたら、それを展開して、hit_data.tsvを取り出します。
$ tar -zxf exturhogedev_2017-10-17.tar.gz
取り出したら、hit_data.tsvからcutコマンドで必要なカラムだけ取り出しましょう。
cutコマンドを使ったデータフィードカラムの抽出方法も前に書きましたので、下記の記事も参考にしてください。
Adobe Analytics: データフィードをGoogle BigQueryのテーブルにロードする
今回は下記のカラムを抽出します。
9 campaign
11 channel
36 evar1
37 evar2
38 evar3
286 event_list
305 hit_time_gmt
351 page_event
352 page_event_var1
356 page_url
357 pagename
819 prop1
820 prop2
821 prop3
898 referrer
957 user_server
988 visid_high
989 visid_low
ブラウザの高さや幅なんかもインポート出来るんですが、今回は省略します。
$ cut -f 9,11,36,37,38,286,305,351,352,356,357,819,820,821,898,957,988,989 hit_data.tsv > extract.tsv
※もしmacOS上でillegal byte sequenceエラーが出る場合は、頭に「LC_ALL=C 」をつけてやると動きます。
次に、必要カラムだけまとめたextract.tsvを、データソースファイルに変換します。
インポートするデータソースファイルのヘッダとして使用可能なアイテムは下記のヘルプに記載されています。
Full Processing – Data Sources User Guide
データフィードの値をそのまま使えれば良いのですが、変換が必要な箇所があります。
i) event_listの値
データフィードのevent_listの値は、200(event1), 201(event2) というように、数値変換されてしまってるのですが、データソースの場合はevent1, event2のようにevents変数の値と同じものに直してやる必要があります。
ii) page_eventの値
データフィードのpage_eventの値は、10(カスタムリンク), 11(ダウンロードリンク), 12(離脱リンク)というように数値変換されてしまってるので、これもそれぞれo, d, eに直します。
iii) VisitorID
フル処理データソースには、VisitorIDまたはipAddressのいずれかのカラムが必要です。
あと、IP除外を設定しているならexclude_hit=0の行を除外する必要があります。
→そもそもIPアドレスもデータフィードで抽出してるので、この加工プロセスでフィルタリングするのもアリです。とりあえず今回は省略。
Node.jsで簡単なプログラムを書いて、event_listとpage_eventの変換と、visid_high + visid_lowの値をVisitorIDにセットする事にしました。
/* filter.js */
var file = 'extract.tsv';
var csvparse = require('csv-parse');
var fs = require('fs');
var ws = fs.createWriteStream('datasource.txt');
//header
ws.write("campaign channel eVar1 eVar2 eVar3 events timestamp linkType linkName pageURL pageName prop1 prop2 prop3 referrer server visitorID" + "\n");
var rs = null;
try {
rs = fs.createReadStream(file, 'utf-8');
rs.on('error', function (err) {
console.error(err);
});
} catch (err) {
console.error(err);
}
var parser = csvparse({delimiter:"\t"});
parser.on('data', function (data) {
var line = [];
var flg = true;
for (var i=0; i<data.length; i++) {
if (i == 5) { //event_list
var chk = data[i].split(",");
var events = [];
for (var j=0; j<chk.length; j++) {
switch(chk[j]) {
case "200": events.push("event1"); break;
case "201": events.push("event2"); break;
case "202": events.push("event3"); break;
}
}
line.push(events.join(","));
} else if (i == 7) { //page_event
if (data[i] == "10") {
line.push("o");
} else if (data[i] == "11") {
line.push("d");
} else if (data[i] == "12") {
line.push("e");
} else {
line.push("");
}
} else if (i == 16) { //visid_high
line.push(data[16] + data[17]);
} else if (i == 17) { //visid_low
// do nothing
} else {
line.push(data[i]);
}
}
if (flg) {
ws.write(line.join('\t') + '\n');
}
}
});
parser.on('error', function (err) {
console.error(err);
});
rs.pipe(parser);
これを実行すると、データソース用の入力ファイル datasource.txt が出来上がります。
3. データソース設定を作成する
AdobeAnalytics管理画面からデータソース設定を作成します。
AAにログインして、[管理者] > [データソース] を開きます。
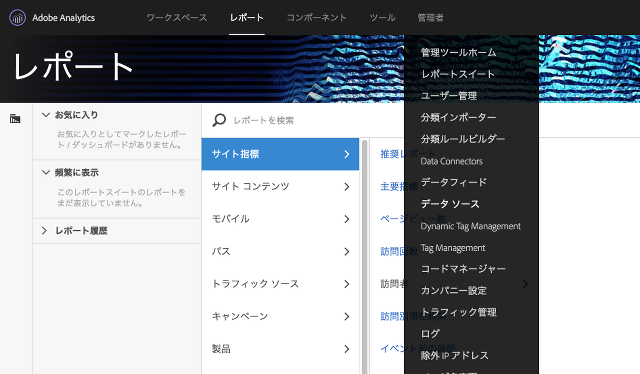
[作成]タブを開き > [汎用] > [一般的なデータソース(フル処理)]を選んで[アクティブにする]ボタンをクリックします。
するとデータソース作成ウィザードが始まるので、名前やメールアドレスを入力して、次へ進みます。
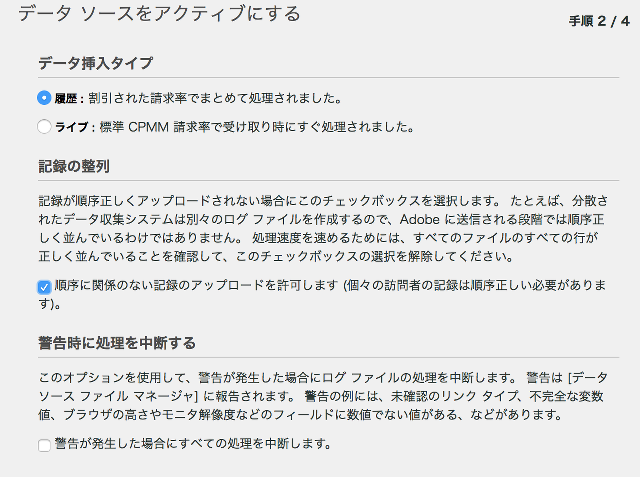
手順2/4で、[履歴]と[順序に関係のない…]の項目にチェックを入れます。
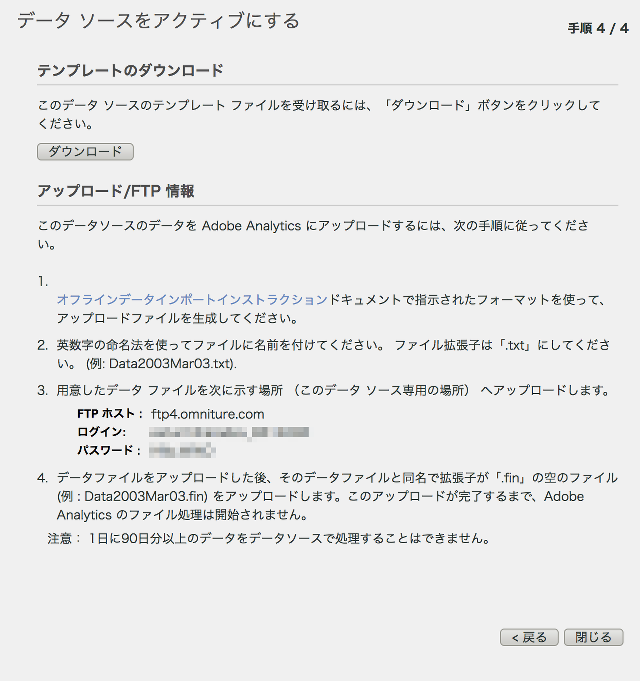
最後まで進むと、FTP情報が表示されます。ホスト名・ログイン・パスワードをメモしておきます。
テンプレートはダウンロードしなくてOKです。
4. FTPでデータソースファイルをアップロードする
以上でファイルをアップロードする準備出来たので、FTPツールでファイルをアップロードします。
さきほど作ったdatasource.txtをアップロードします。
その後、完了通知ファイルとして、同じ名前で拡張子を.finにした0バイトのテキストファイル datasource.fin をアップロードします。
しばらくしてデータソースの[管理]タブを開くと、インポート結果が表示されます。
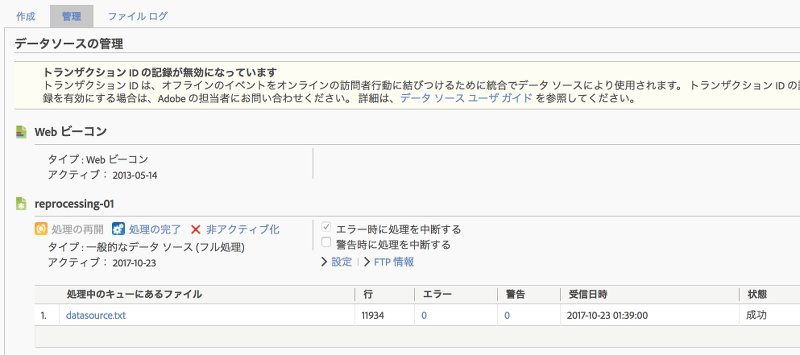
11,934行のデータのインポートが成功した事がわかります。
データソースのファイルアップロードの注意点は、90日以上の日付をいっぺんにアップロード出来ないのと、あとは50MB以上のファイルだと失敗するようです。
その場合は、ファイルを分割してください。
また、分割したファイルの全てにヘッダー行が存在する必要があるので、忘れずにヘッダー行を挿入してください。
そして落とし穴は、データソースでインポートした訪問者と、Webのビーコンで収集した訪問者は「つながらない」という点です。
ヘルプにはこのように書いてあります。
フル処理データソースのデータは個別の訪問者プロファイルを使用して処理されるので、たとえアップロードされたデータ内の訪問者 ID が JavaScript やその他の AppMeasurement ライブラリを使用して収集されたデータと一致しても、eVar の割り当てに関しては訪問者プロファイルが関連付けられることはありません。
Webとデータソースでは処理系が異なるのでしょうね。
これは仕様なので仕方ないので、visid_high+visid_lowをキーにして、サードパーティの分析ツールを使うなど、「Adobe外」での処理が必要です。
弊社では、本日紹介したようなAdobe Analyticsのデータ再処理やデータフィードを用いた分析業務支援サービスを提供しております。
お問い合わせはこちらからどうぞ。
ブログへの記事リクエストはこちらまで