※2019年9月4日追記
この記事は情報が古いので、新しい記事を書きました↓。
Adobe Analytics: DatafeedをGoogle BigQueryにロード(2019年9月版)
こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
前回のブログの続きです。
今回は、Adobe AnalyticsのデータフィードファイルをGoogle BigQueryのテーブルにロードする方法についてです。
データフィードファイルを加工してアップロード用ファイルを作成する
データフィードファイル(.tar.gz)をGoogle Compute EngineのVMにSFTP転送したので、そのファイルをtarコマンドで展開します。
$ tar -zxvf exturedev_2017-05-17.tar.gz
tar.gzを展開すると、中身は以下のようなファイルになってます。
browser.tsv
browser_type.tsv
color_depth.tsv
column_headers.tsv
connection_type.tsv
country.tsv
event.tsv
hit_data.tsv
javascript_version.tsv
languages.tsv
operating_systems.tsv
plugins.tsv
referrer_type.tsv
resolution.tsv
search_engines.tsv
主役はhit_data.tsvです。Adobe Analyticsで収集したヒットデータは、このhit_data.tsvファイルに入ってます。
残りのファイルはルックアップ用データでして、ヒットデータに含まれるメタデータのキーデータとマッピングするためのものです。
hit_data.tsvどのくらいのデータが含まれるか見て見ましょう。
$ wc -l hit_data.tsv 1131 hit_data.tsv
1131行(件)のヒットデータが含まれます。
弊社のテストデータなのでこんなもんです。
ではカラム数がどれだけあるか見ましょう。
$ wc -w column_headers.tsv 1013 column_headers.tsv
Adobe Analyticsの全カラムをデータフィード配信したので、全部で1000カラム以上含まれてます。
そしてこれらのデータを全てBigQueryに取り込むためのテーブルを作ろうとすると中々忙しいので、今日はそこまでやりません。
hit_data.tsvから必要なカラムだけ抜き取り、そのデータを格納するためのテスト用の小さなテーブルを作って見ます。
まずは、column_headers.tsvをタブ区切りファイルから、改行区切りファイルに変換します。
$ cat column_headers.tsv | tr '\t' '\n' > column_headers-desc.txt
それからviでcolumn_headers-desc.txtファイルを開き、必要な各カラムの行数を調べます。
$ vi column_headers-desc.txt :set nu
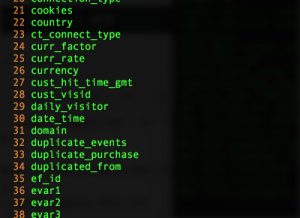
:set nuで行数を確認します
今回使うカラムは、下記の9カラムだけにしてみます。
30 date_time
287 exclude_hit
304 hit_source
623 post_event_list
661 post_page_url
662 post_pagename
812 post_visid_high
813 post_visid_low
994 visit_num
cutコマンドを使って、上記に該当するカラムを取り出してvisid_details.txtというファイルを作ります。
$ cut -f 30,287,304,623,661,662,812,813,994 hit_data.tsv > visid_details.txt
これでロードするファイルは出来上がりました。
続いてBigQueryの用意をします。
BigQueryのセットアップをする
BigQueryもGoogle Cloud Platformの常時無料プランで利用できます。
月間1TBクエリまででしたら、いつまでも無料です。
GCPのダッシュボードから、[BigQuery]を開いて、BigQueryの利用を開始します。
BigQueryのUIが開いたら、今回データフィードをインポートするための[データセット]と[テーブル]を作成するのですが、せっかくなのでBigQueryクライアントライブラリを使ってデータセットとテーブルを作成してみます。
BigQueryクライアントライブラリ
https://cloud.google.com/bigquery/docs/reference/libraries?hl=ja
最近個人的によく使ってるNode.jsでやってみます。
npmでライブラリをインストールしておきます。
$ npm install --save @google-cloud/bigquery
ライブラリをインストールしたら、Node.jsでAPIを実装します。
/* bqdataset.js */
var BigQuery = require('@google-cloud/bigquery');
var projectId = 'hogehoge'; //GCPプロジェクトIDに置き換える
var bigquery = BigQuery({
projectId: projectId
});
var datasetName = 'my_adobe_datafeed';
// dataset作成
bigquery.createDataset(datasetName)
.then((results) => {
const dataset = results[0];
console.log("Dataset " + dataset.id + " created.");
});
bqdataset.jsという名前で保存して、nodeで実行するとmy_adobe_datafeedデータセットが出来上がります。
$ node bqdataset.js
わざわざAPI使わなくてもBigQueryのUIから作った方が早いんですが、あえてAPIで実行します。
データセットの次は、テーブルです。
これもAPIで作って見ます。
/* bqtable.js*/
var BigQuery = require('@google-cloud/bigquery');
var projectId = 'hogehoge'; //GCPプロジェクトIDに置き換える
var bigquery = BigQuery({
projectId: projectId
});
var datasetName = 'my_adobe_datafeed';
var dataset = bigquery.dataset(datasetName);
var tableId = 'online_users';
var options = {
schema: 'date_time:timestamp,exclude_hit:integer,hit_source:integer,post_event_list,post_page_url,post_pagename,post_visid_high:integer,post_visid_low:integer,visit_num:integer'
};
dataset.createTable(tableId, options).then(function(data) {
var apiResponse = data[1];
console.log(apiResponse);
});
これもBigQueryUIから作った方が早いかも知れませんが、いずれ1000カラム以上あるテーブルを作るとしたらAPIの方が効率が良いので、覚えておいて損はしません。
bqtable.jsを実行すると、online_usersテーブルが出来上がります。
$ node bqtable.js
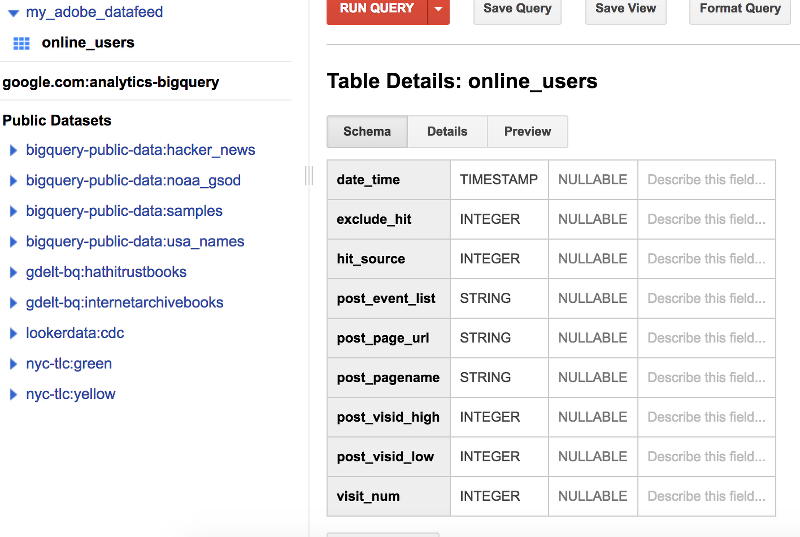
online_usersテーブル
BigQueryにデータをロードする
さて、テーブルが用意できたので、今度はさきほど作ったvisid_details.txtをonline_usersテーブルにロードします。
これも例のごとく、わざわざAPIで実行してみます。
/* bqload.js */
var BigQuery = require('@google-cloud/bigquery');
var projectId = 'hogehoge'; //GCPプロジェクトIDに置き換える
var bigquery = BigQuery({
projectId: projectId
});
var datasetName = 'my_adobe_datafeed';
var dataset = bigquery.dataset(datasetName);
var table = dataset.table('online_users');
var metadata = {
fieldDelimiter: "\t"
};
var fs = require('fs');
fs.createReadStream('visid_details.txt')
.pipe(table.createWriteStream(metadata))
.on('complete', function(job) {
console.log("load completed.");
});
bqload.jsを実行すると、visid_deitals.txtのデータがonline_usersテーブルにロードされます。
$ node bqload.js
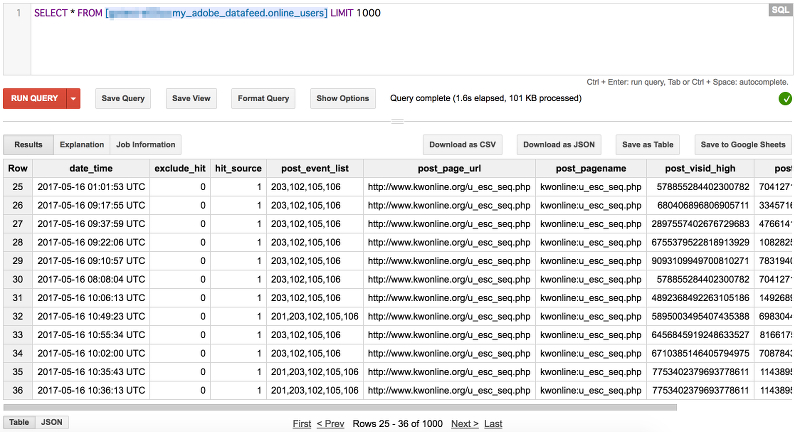
データがテーブルに入ったかどうか見てみましょう。
BigQueryのUIから[COMPOSE QUERY]を開き、以下のクエリを実行してみます。
SELECT * FROM [hogehoge:my_adobe_datafeed.online_users] LIMIT 1000
※hogehogeは、GCPプロジェクトIDに置き換えてください。
正しくデータがロードされてれば、結果が返ってきます。
今回は、データフィードファイルを展開して、BigQueryテーブルにロードする方法について説明しました。
次回は、BigQuery上でページビュー数や訪問者数などを抽出するためのクエリについて書いてみようと思います。
続き: Adobe Analytics: データフィードをBigQueryで集計する
ブログへの記事リクエストはこちらまで