はじめに
こんにちは、石原と申します。
こちらの記事は前回の記事からの続きになっております。まだ前回の記事を読んでいない方がいらっしゃる場合は、ぜひ先にそちらをご覧ください。
前回はVertex AI Embeddings for Textによって、文章のベクトル化(テキストエンベディング)を行いました。また、このベクトルを用いることでセマンティック検索や、リコメンデーション、分類などを行うことができるようになることをご紹介しました。
今回は実際に作成したエンベディング値を用いて検索エンジンを作成していきたいと思います。
ベクトル検索(Vector Search)とは
ベクトル検索とはベクトルデータベースに保存されたベクトル値の中から、クエリベクトルに対して最近傍のベクトルを検出する仕組みのことです。
従来の検索エンジンが検索キーワードの指定や、単語の出現頻度、語彙の類似性に大きく影響を受けていたのに対して、ベクトル検索ではベクトル空間内での距離を使用して類似度を求めます。これによってキーワードの完全一致を必要としない曖昧な検索を行うことが可能になっています。
ベクトル検索では2020年にGoogleが発表したScaNNと呼ばれるアルゴリズムが使用されています。今回そちらの説明については省略させていただきますが、興味のある方は以下のリンクをどうぞ。
https://github.com/google-research/google-research/tree/master/scann
費用と注意
Vertex AIの費用についてはVertex AI Search と Conversation の料金を確認ください。
オプションなしの検索でクエリ1000件ごとに$2.00がかかります。
また、ベクトル検索サービスはサーバーレスのため、デプロイしてからデプロイを解除するまでの間、料金が発生し続けてしまいます。今回の記事をテストを行う際には注意してください。
インデックス料金としては$5.00 GiB/月かかります。
今回の実装でもデータ量によって費用は変動しますが数ドルは消費する場合がありますのでご注意ください。
実装の手順
では公式のクイックスタートガイドを参考に作成していきます。
前回のノートブックが実行状態の場合は、続けて実行するとデータの読み込みの手間がかからないため、「エンベディングデータの識別名のリストを用意」までスキップしていただいて大丈夫です。
前回のノートブックにエンベディングデータをGooge Driveに保存する方法を追記しておりますので、そちらから読み込むという形で実装していきます。使用しているコードはこちら。
まずは、前回の記事と同じく必要なモジュールをインストールしていきます。
!pip3 install --upgrade google-cloud-aiplatform \
google-cloud-storage \
'google-cloud-bigquery[pandas]'

再起動も同じように実行してください。
次にプロジェクトIDとリージョンを入力します。
PROJECT_ID = "YOUR-PROJECT-ID"
REGION = "asia-northeast1"
次にアカウントの認証とモジュールのインポートを行います。
from google.colab import auth
auth.authenticate_user()
import pandas as pd
import json
次にエンベディングデータを用意します。
今回の記事では、前回の記事と同じ方法で作成したエクスチュアのブログのエンベディングデータを用いて実装を進めます。前回のドキュメントと同じくStackOverflowのデータでの確認も可能ですので、ご自身のエンベディングデータを用いて実装を進めてください。
Google Driveからのエンベディングデータ読み込み
Google Driveを使用する場合は以下のコマンドを実行してドライブをマウントしてください。
from google.colab import drive
drive.mount('/content/drive')
実行後は、/content/drive/MyDrive/以下に自分のGoogleDriveのファイルが配置されているため、そちらからファイルにアクセス出来ます。
filepath = f'/content/drive/MyDrive/{file_name}'
df = pd.read_csv(filepath)
エンベディングデータの識別名のリストを用意
各エンベディングデータの名前をリストで保存します。
今回実装するブログの場合は記事タイトルをリストとして持ちます。
title = ['Vertex AI Vector Search による社内ブログ検索エンジンを作成してみた',....]
データの準備ができたのでベクトル検索の構築を行っていきます。
APIの有効化
また、下記のAPIについて有効化されていない場合は有効化をしてください。
- compute.googleapis.com
- aiplatform.googleapis.com
- storage.googleapis.com
有効化のコマンドは以下の通りです。
! gcloud services enable compute.googleapis.com aiplatform.googleapis.com storage.googleapis.com --project "{PROJECT_ID}"
エンベディングデータのGoogle Cloud Storageへのアップロード
ベクトル検索を使用するためにはエンベディングデータをjson形式にしてGCSへアップロードする必要があります。以下のコマンドではjson形式に変換し、Google Driveへアップロードを行っています。
out_jsonlist = [{"id":id, "name":name, "embedding":value} for id,name,value in zip(df.index.tolist(),title,df.values.tolist())]
with open(filepath, mode='w') as f:
# {"id": 1,"name":ブログタイトル,"embedding":[1,1,1,1,1....]}の結果を出力
for s in out_jsonlist:
f.write(json.dumps(s))
f.write('\n')
アップロードするバケットの名前を指定します。
output_filename = "blog-embs.json"
filepath = f'/content/drive/MyDrive/{output_filename}'
BUCKET_NAME = "YOUR-BUCKET-NAME"
LOCATION = "asia-northeast1"
BUCKET_URI = f"gs://{BUCKET_NAME}"
以下のコマンドによってGoogle Cloud Storgeのバケットを作成し、jsonファイルをアップロードします。
! gsutil mb -l $LOCATION -p $PROJECT_ID $BUCKET_URI
! gsutil cp $filepath $BUCKET_URI
エンベディングデータをベクトル検索に登録
以降の作業はデータ量によっては実行に1時間程度かかる場合があるので注意してください。
また、途中で作業を中断する場合は必ずクリーンアップした状態で終了してください。
デプロイが完了した状態ではVector Searchの利用料金が発生し続けるのでご注意ください。記事の最後にバケットの削除、デプロイの解除、インデックスエンドポイントの削除、インデックスの削除を行う方法も掲載しておりますので参照してください。
ベクトル検索インデックスへの登録
各パラメータを以下のように設定しています。
- INDEX_NAME : 検索に使用するデータ名
- INDEX_ENDPOINT_NAME : 検索の際にリクエストを投げるエンドポイント名
- DEPLOYED_INDEX_ID : インデックス名とエンドポイントをデプロイする際のID
- DIMENSIONS : エンベディングデータの次元数(Vertex AI Embeddings for Textを使用している場合は768次元)
- Approximate_Neighbors_Count : 検索結果の件数
from google.cloud import aiplatform
aiplatform.init(project=PROJECT_ID, location=LOCATION)
INDEX_NAME = "your_index"
INDEX_ENDPOINT_NAME = "your_index_endpoint"
DEPLOYED_INDEX_ID = "your_index_deployed"
DIMENSIONS = 768
Approximate_Neighbors_Count = 10
こちらではベクトル計算高速化のためにインデックスの構築が行われています。
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = INDEX_NAME,
contents_delta_uri = BUCKET_URI,
dimensions = DIMENSIONS,
approximate_neighbors_count = Approximate_Neighbors_Count
)
インデックスエンドポイントの作成
次にエンドポイントを作成します。
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = INDEX_ENDPOINT_NAME,
public_endpoint_enabled = True
)
インデックスのデプロイ
インデックスエンドポイントに対してインデックスをデプロイします。
これによってエンドポイントへリクエストを送信することで、インデックスのベクトル検索が可能になります。
my_index_endpoint.deploy_index(
index = my_index, deployed_index_id = DEPLOYED_INDEX_ID
)
検索の実施
それでは検索を実際に行っていきます。検索の際にはエンベディングデータが必要になります。自然言語からの検索を行う場合は、インプットをエンベディングデータに変換する処理を挿入する必要があります。
今回の例では登録しているブログ記事のエンベディングを用いて検索を行います。
product_names = {}
product_embs = {}
with open(filepath) as f:
for l in f.readlines():
p = json.loads(l)
id = p['id']
product_names[id] = p['name']
product_embs[id] = p['embedding']
今回はブログの中から「 SnowflakeのData Clean Roomを基礎から一番詳しく解説(1回目)」を選択して検索してみます。記事のエンベディングデータのID番号が8番だったのでそちらを取得します。
no = 8
query_name = product_names[no]
query_emb = product_embs[no]
print(query_name)
以下のコードで結果を検索します。
response = my_index_endpoint.find_neighbors(
deployed_index_id = DEPLOYED_INDEX_ID,
queries = [query_emb],
num_neighbors = Approximate_Neighbors_Count
)
それでは結果を確認してみます。
queriesにリスト形式で入力したエンベディング値をすべて検索するので、1つだけの検索結果を取得する場合はリストの先頭要素に入った結果を取得する必要があります。
for idx, neighbor in enumerate(response[0]):
print(f"{neighbor.distance:.4f} {product_names[int(neighbor.id)]}")
実際に実行してみた結果が以下のようになりました。
左側の値がより大きいほど近い内容であることを示しています。
今回の例ではインデックス内のデータを用いて検索を行っているので、自分自身がもっとも近い結果として得られています。
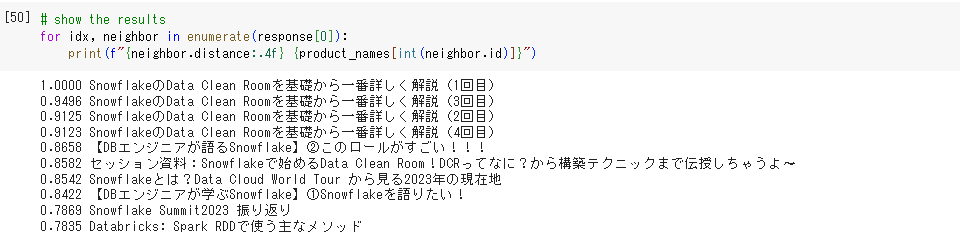
上位の結果はsnowflake関連のブログになっており、テキストエンベディングの意味的理解が確認できるかと思います。(検索時にはキーワードを入力していないのでテキスト検索にはなっていないことが確認できます。)
この検索をアプリ等で実装することでセマンティック検索エンジンの作成や、リコメンデーション機能などを実現することが可能になります。
クリーンアップ方法について
本ページのコードを実行した後には以下を必ず実行し、Vertex AI Searchの料金が発生しないようにしてください。
# delete Index Endpoint
my_index_endpoint.undeploy_all()
my_index_endpoint.delete(force = True)
# delete Index
my_index.delete()
# delete Cloud Storage bucket
! gsutil rm -r {BUCKET_URI}
まとめ
今回はVertex AI Vector Searchを使用した検索エンジンの実装を行っていきました。
前回の結果では意味をもたなかったエンベディング値がAIの意味理解という点において高い効果を発揮しているということがわかるかと思います。
今回紹介したVertex AI Vector Searchは、検索だけでなくリコメンデーションなどにも用いることが出来ます。ぜひ、各々のサービスに適した活用方法を考えてみてください。
エクスチュアはマーケティングテクノロジーを実践的に利用することで企業のマーケティング活動を支援しています。
ツールの活用にお困りの方はお気軽にお問い合わせください。
参考文献
https://github.com/google-research/google-research/tree/master/scann