
こんちには、喜田です。
エクスチュアでは顧客のSnowflakeデータクリーンルーム(DCR)に関するご支援を経て、DCRの概念や必要性を理解してきました。理解するにつれ、技術的・法的・消費者感情・投資対効果といった様々なハードルがあり、これらを越えていち早く普及の土台ができあがることが何より重要であると考えており、少なくとも構築に必要な技術要素はどんどんオープンに、また企業同士の取り組みに対して損得抜きにアドバイス・意見交換しあえるような関係性を目指しています。
BigQueryでもDCRがプレビューに
本記事は2023年10月25日に作成しています。8月末にサンフランシスコで開催されたGoogle Coud Nextの発表でBigQuery(Analytics Hub)でもデータクリーンルームの発表がありました。
感覚値ですがユーザシェアが大きいBigQueryのネイティブ機能として実装されたことで、DCRの概念が浸透し、また気軽にトライしてみようという各社の取り組みへの起爆剤になるのではないかと考えています。
DCRの根幹は「セキュア/プライバシーを重視しながらデータを相手に利用させる」「データ授受のためのETL開発負担をなくす」というところにあります。
そのため仕組み上、どうしてもデータのコピーや転送を発生させないためには同じクラウドプロバイダー同士といった制約が生じるのが現状です。つまり、マーケットシェアの大きいBigQueryこそが、BigQueryユーザ同士でDCRの仕組みを利用して利を得るという形を実現しやすいと捉えています。
Analytics Hub×Privacy Policyによるクリーンルーム
Analytics Hub上に実装されたクリーンルーム機能
BigQueryにはパーティ間のデータ授受を簡単に実現するためのAnalytics Hub機能が提供されており、データクリーンルーム機能はそのAnalytics Hubのサブセットとして提供されています。
非常に簡単なUIで(DCRの概念そのものは理解したうえでですが)2~3分で公開までの仕組みが作れてしまいました。手順的にもほぼ一本道で必要項目を入力するだけで良く、対象テーブルが決まっていて、相手が決まっていれば悩むことはほぼないでしょう。
Privacy Policy機能でビューに対するクエリを制限
一方、Analytics Hubで公開するテーブル(ビューを含む)側での準備をきちんと考えておく必要があることがわかりました。
公開単位は「データセット」であり、通常BigQueryのデータセットには特定業務に必要なテーブルやビューが一式入っていると思います。これをそのままクリーンルームで公開すると意図しないテーブルが公開されてしまうことになりますので、公開用テーブルは公開用データセットに切り出しておく必要があります。
公開用データセットに切り出すといっても、大げさな対応は不要で、元テーブルを参照するビューを公開用データセットに作成すればよいです。このビューを作成するときに考慮することとして、
- 非公開列はビューに含めないこと
何言ってるの?というぐらい当然の話ですが、データクリーンルーム側の機能で公開列を絞ることができないので、このビュー定義で公開列を制限しておくことが必須になります。 - 新機能:Privacy Policyの利用を検討すること
データクリーンルームで顧客のプライバシーを維持しながら、相手パーティにデータを利用させるということを実現するために、個人情報列が隠れるような「集計値」のみクエリできるようにします。SQLで言ったらGROUP BYを強制するということです。そのための機能がPrivacy Policyです。
Privacy Policyの実装例
実行例とともにこの新機能の動作を紹介します。
公開予定のテーブルdcr_origin.customerは、とある調査会社が持っている顧客の居住地やマーケットセグメント情報を含む15万件のデータとします。実際の値の一部は以下のようなものです。(TPC-Hベンチマークのcustomer表を利用)
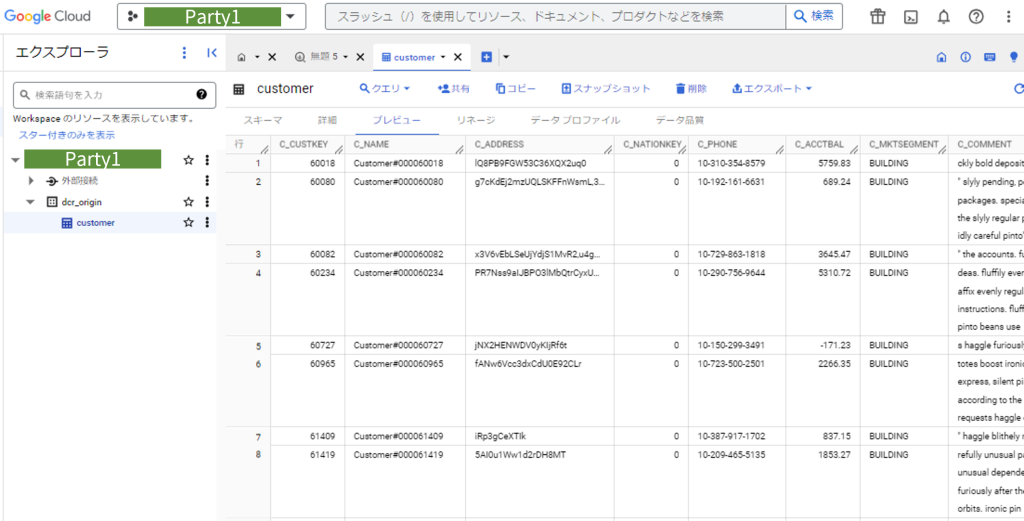
ここで、c_custkey はここでは単なる連番ですが、実際の顧客データベースにおけるメールアドレスのような個人情報列であると想定して検証を進めていきます。
このcustomer表を公開用にPrivacy Policyをつけたビューとして定義します。通常のビュー定義「CREATE VIEW xxx AS SELECT・・・」にOPTIONSとして privacy_policyを指定します。
thresholdはGROUP BYによって得られた集計値が少ない場合(本例では3件以下)は結果を返さないこと、privacy_unit_columnsは個人情報列なので値を見せたくない、言い換えるとGROUP BY句に指定させないカラムです。
-- プライバシーポリシーを指定したビューを作成
CREATE OR REPLACE VIEW dcr_provider.customer_barriered
OPTIONS(
privacy_policy= '{"aggregation_threshold_policy": {"threshold": 3, "privacy_unit_columns": "c_custkey"}}'
)
AS ( SELECT * FROM dcr_origin.customer);
こうして作成したビューは、自パーティ内でもすでにバリヤーがかかっています。まずはOKなSQLから実行してみます。ポイントは2点あり、
ポリシー付きビューに対するSELECTでは、「WITH AGGREGATION_THRESHOLD句」を明記しないとエラーになります。
実行可能なSQLはcount(*)とか、GROUP BYを含んで集計値を返すSQLになっています。
SELECT WITH AGGREGATION_THRESHOLD
count(*)
FROM dcr_provider.customer_barriered;
f0_
-------
150000
SELECT WITH AGGREGATION_THRESHOLD
c_nationkey,count(*) AS cnt
FROM dcr_provider.customer_barriered
GROUP BY c_nationkey;
c_nationkey cnt
----------- -----
0 5925
1 5975
2 5999
3 6020
:
次にNGな例
/* 禁止されるSQL */
SELECT
count(*)
FROM dcr_provider.customer_barriered;
-- You must use SELECT WITH AGGREGATION_THRESHOLD or GROUP BY privacy unit column because a privacy policy has been set by a data owner.
-- OKなSQLで書いたcountと同じ内容だがWITH AGGREGATION_THRESHOLD句がない
SELECT WITH AGGREGATION_THRESHOLD
c_custkey,count(*) AS cnt
FROM dcr_provider.customer_barriered
GROUP BY c_custkey;
-- SELECT WITH AGGREGATION_THRESHOLD with implicit options must not GROUP BY the privacy unit column.
-- 禁止されているc_custkeyカラムでGROUP BYしようとしている
-- これが許されると、「Aさんのメアド:1件」 みたいな行が15万件返るのでNG
SELECT WITH AGGREGATION_THRESHOLD
c_nationkey,array_agg(c_custkey) AS custkey_list
FROM dcr_provider.customer_barriered
GROUP BY c_nationkey;
-- array_agg is not supported in a SELECT WITH AGGREGATION_THRESHOLD query.
-- これをちゃんと防いでくれてよかった。通常テーブルに対してやると以下のようになる。
SELECT
c_nationkey,array_agg(c_custkey) AS custkey_list
FROM dcr_origin.customer
GROUP BY c_nationkey;
/*
c_nationkey custkey_list
----------- -----------------------------
0 [40018,60080,52082,34234,...]
1 [27583,14805,32159,19827,...]
40018、60080とかはc_custkey列、つまりメアド相当です。
list_agg関数は集約関数のフリをして値を全部見せてしまう悪い子です!笑
*/
SQLが次々でてきて脳が疲れる記事になってしまいました(笑)
ポイントは、実行可能なクエリに制限をかけるような機能がついたということ、制限=GROUP BYの強制であり、目的はプライバシー列の保護に他なりません。
Analytics Hubでのデータ公開
シンプルUIで簡単に公開設定できてしまうので多くは語りません。
ポイントはリージョン指定で公開したいデータセットの配置場所を選んでおくこと、データセットの中身は丸ごと公開することになるので、前項でやったようなバリヤー済みビューを用意しておくことぐらいです。
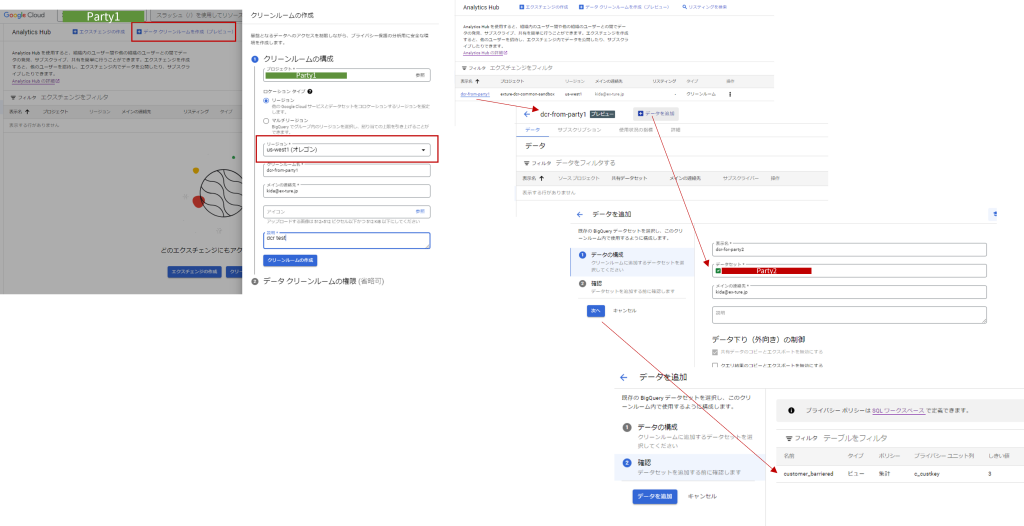
冒頭でも少し書いたように、DCRにはデータ授受にあたってのETL開発負荷を下げるという目的もありました。リージョンをまたいだデータ共有となると同じGoogle同士でも理論上その負担は発生します(更新頻度をどのぐらいにするとか、データサイズがどれだけで複製を持つだけでおいくらかかるとか。)ので、データセットの置き場所で公開するという考え方で良いと思います。
受け取り側のパーティ2でも非常に簡単でした。こちらのAnalytics Hubで「リスティングを検索」とすると公開相手に既に選んでもらっているため一覧に表示され、サブスクリプション要求を送信することができました。
その後はBigQueryのクエリ作成時など左袖に出るオブジェクトのツリーにしっかり出てきて、通常のテーブルと同じようにクエリすることができます。
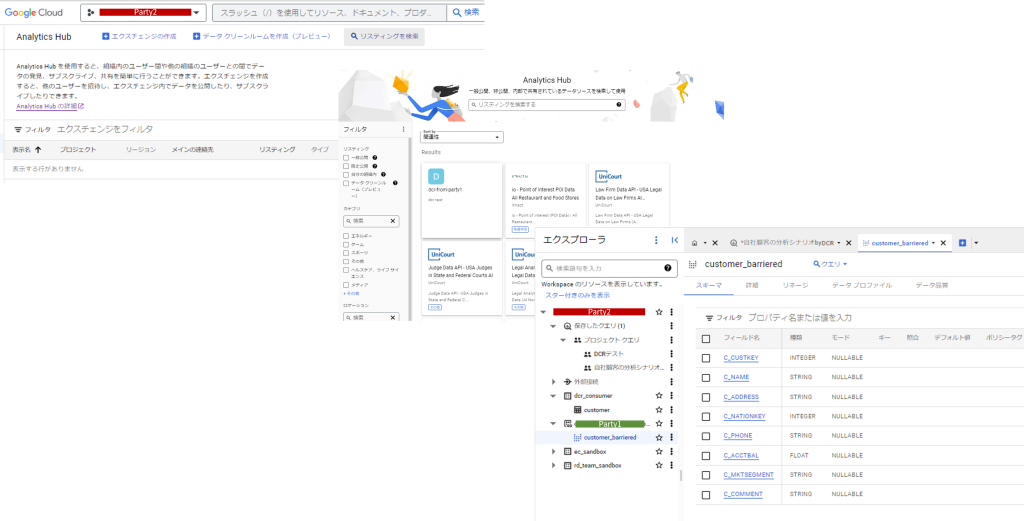
パーティ2(自社データセット)側にある自社customerと、パーティ1に公開してもらったcustomer_barrieredが見えています。
クリーンルームならではの分析シナリオ例
シンプルながら誰でもクリーンルームの価値を理解できるであろうシナリオで説明します。
Party1が提供するのは先ほどのcustomer_barriered、
Party2は、何かの商品を売っている企業で、自社顧客について一切の属性付けができていない状態とします。以前に購入してくれた方のメアド、名前ぐらいだけ持っていて、マーケ施策といえばリピートを促すDMを一斉送信するぐらいでした。
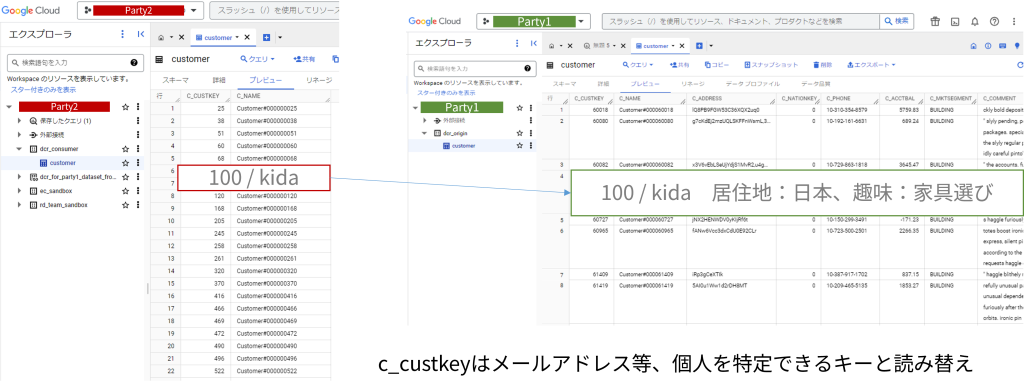
ここにParty1から購入した多数の個人の趣味嗜好・居住地といったデータを当てた時に、いままで全く見えていなかった自社顧客の特徴がわかる(かもしれない)、次のマーケ戦略を考えることに役立てます。
ただし、上記のスクリーンショットに挙げたようにkidaという個人の趣味嗜好が丸わかりになってはいけません。なので、Party1ではPrivacy Policyを定義し、GROUP BY後の集計結果だけを返します。「居住地が日本の人が何人いますよ~」「家具選びはみんな大好きみたいですよ~」といった示唆を与えてくれるわけですね。
両パーティの件数の重なりを把握
DCRで分析を進めるにあたり、両パーティのデータの重なりを理解するのが初めの一歩と言えます。
/* 自社で持っている顧客リストの件数 */
SELECT count(*) AS cnt
FROM dcr_consumer.customer;
cnt
-----
3000
/* 外部から購入したデータの件数(まだJOINしていない)*/
SELECT WITH AGGREGATION_THRESHOLD -- Privacy Policy用のクエリ
count(*) AS cnt
FROM dcr_from_party1_dcr_for_party2.customer_barriered;
cnt
-------
150000
いよいよ両パーティのデータをJOINしてみます。SQLのレベルで言えば、ごく基本のJOINで難しいことはもはやありません。
SELECT WITH AGGREGATION_THRESHOLD
count(*) AS matched_cnt
FROM
dcr_consumer.customer AS local -- 自社の3000人
JOIN
dcr_from_party1_dcr_for_party2.customer_barriered AS remote -- 購入した15万人
ON
local.c_custkey = remote.c_custkey -- 共通のキー(例:メールアドレス)でJOIN
;
matched_cnt
-----------
2000
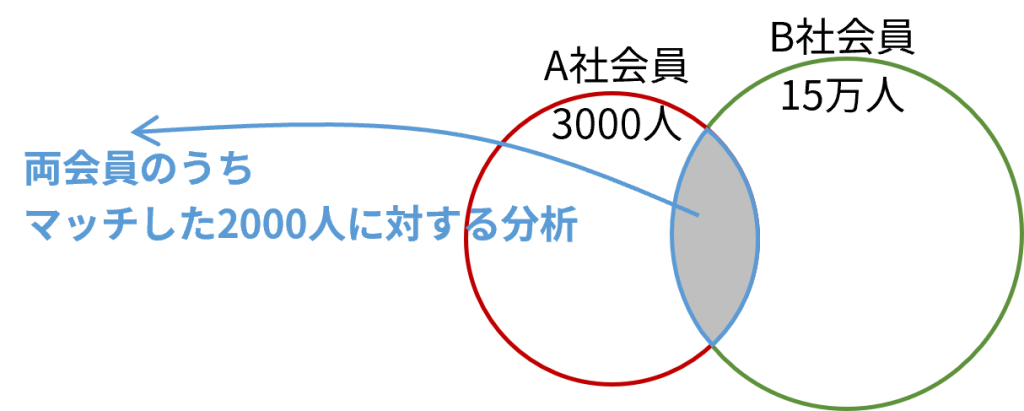
3000人のうち2000人がマッチする極端なサンプルデータでした。ベン図の面積がおかしいのはご容赦ください・・・
顧客属性を調べて自社顧客の趣味嗜好を理解しよう!
次のクエリも、ここにGROUP BYを加えてあるセグメントに属する人数を確認していくSQLになります。両社のデータをJOINするので、この重なりにあたる2000人の集団を対象に理解を深めていきます。
SELECT WITH AGGREGATION_THRESHOLD
c_nationkey,c_mktsegment,count(*) AS matched_cnt
FROM
dcr_consumer.customer AS local -- 自社の3000人
JOIN
dcr_from_party1_dcr_for_party2.customer_barriered AS remote --15万人
ON
local.c_custkey = remote.c_custkey -- 共通のキー(例:メールアドレス)でJOIN
GROUP BY
c_nationkey,c_mktsegment -- 居住国とマーケセグメントでGROUP BY
;
/*
c_nationkey c_mktsegment matched_cnt
----------- ------------ -----------
0 BUILDING 11 -- 均等に割れば平均16人前後になるはず
1 BUILDING 15
2 BUILDING 14
3 BUILDING 8
4 BUILDING 4
5 BUILDING 13
6 BUILDING 11
7 BUILDING 5
8 BUILDING 10
9 BUILDING 9
10 BUILDING 6
11 BUILDING 6
12 BUILDING 184 -- 桁違いの特徴を発見
13 BUILDING 7
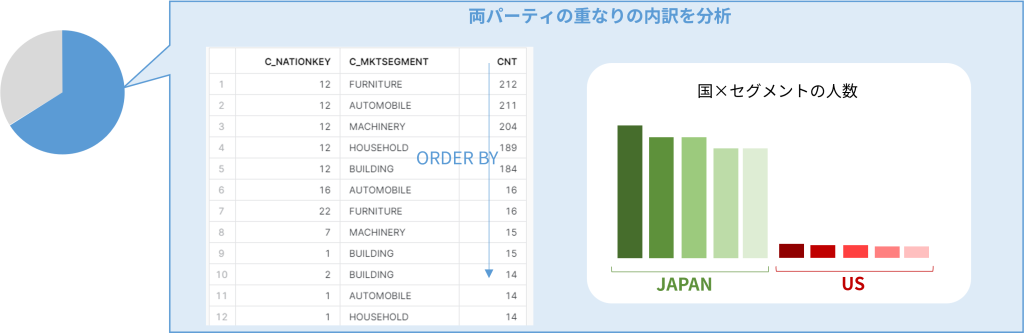
元データの特徴として、15万件中、25ヵ国の居住地が均等に6000人前後ずつ、5種のマーケットセグメントが均等に3万人前後ずつ、「日本在住で車に興味がある人」は25ヵ国×5種=125セグメントのうちの1つにあたり、約1200人が属するデータとなっています。
そのようなデータから、均等に選ばれた2000人の集団であれば、15万:2000=1200:16で、「日本在住で車に興味があるA社顧客」は16人!みたいな推測となるのですが、その10倍近い184人が該当するセグメントを発見しました。
では、そのようなセグメントが他にないか、ORDER BY付きで調べてみます。
SELECT WITH AGGREGATION_THRESHOLD
c_nationkey,c_mktsegment,count(*) AS matched_cnt
FROM
dcr_consumer.customer AS local -- 自社の3000人
JOIN
`dcr_from_party1_dcr_for_party2.customer_barriered` AS remote -- 購入した15万人
ON
local.c_custkey = remote.c_custkey -- 共通のキー(例:メールアドレス)でJOIN
GROUP BY
c_nationkey,c_mktsegment -- 居住国とマーケセグメントでGROUP BY
ORDER BY
matched_cnt DESC -- カウントの多い順に並べる
;
c_nationkey c_mktsegment matched_cnt
----------- ------------ -----------
12 FURNITURE 212 -- 居住国「12」が全属性で多い
12 AUTOMOBILE 211
12 MACHINERY 204
12 HOUSEHOLD 189
12 BUILDING 184
<<<<<越えられない壁>>>>>
22 FURNITURE 16
16 AUTOMOBILE 16
7 MACHINERY 15
:
5種のマーケットセグメントすべてにおいて「居住国12」の人がダントツに多いことがわかりました。(ちなみに元データとして使ったTPC-Hの国マスタとJOINすると、12は日本であることがわかります。)
「もはやマーケットセグメントなんて関係ない、日本こそがわが社の激熱な市場じゃないか」
SELECT WITH AGGREGATION_THRESHOLD
c_nationkey,count(*) AS matched_cnt
FROM
dcr_consumer.customer AS local -- 自社の3000人
JOIN
`dcr_from_party1_dcr_for_party2.customer_barriered` AS remote -- 購入した15万人
ON
local.c_custkey = remote.c_custkey -- 共通のキー(例:メールアドレス)でJOIN
GROUP BY
c_nationkey -- 居住国のみでGROUP BY
ORDER BY
matched_cnt DESC
LIMIT 5
;
c_nationkey matched_cnt
----------- -----------
12 1000
1 62
16 58
6 53
2 53
国だけに絞った結果、3000件の自社ユーザのうち、マッチしたのが2000件、さらにそのうち1000件が「12」の居住国であることが判明
※あとで国マスタと突き合せれば「12」が日本であることがわかり、
日本に対する広告費を倍増するといった施策につながる
※2000件中の1000件が日本だったということで、3000件中の1500件と解釈するか、
3000件中の少なくとも1000件と受け止めるかはケースバイケース
※エクスチュアではこういった数値をどう解釈して、どういう施策が効果的かお客様と一緒に
考えていくマーケティングコンサルのご支援もしています!(突然の宣伝)
シナリオまとめ
BigQueryデータクリーンルームを利用して、自社顧客3000人に対する解像度を高めるためのデータを外部から購入しました。購入データは15万件で、マッチしたのは2000件、66%のマッチ率です。
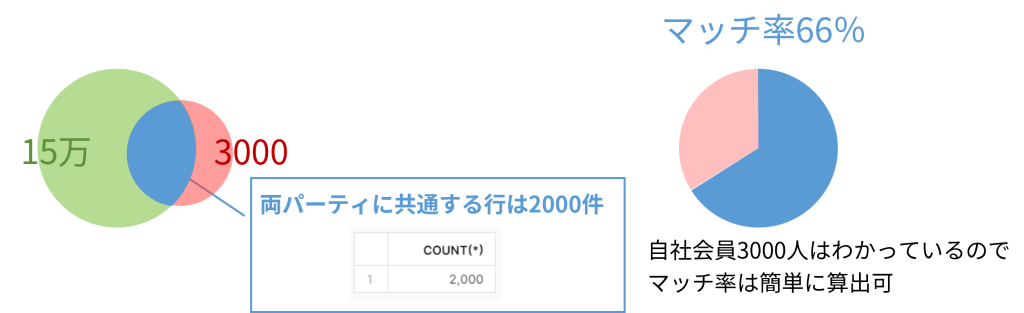
マッチした2000件を対象に購入データに含まれるセグメント情報を調べると、日本在住の方が圧倒的に多く、2000人の集団のうち半数が日本在住であることがわかりました。
BigQuery DCR調査まとめ
- UIがわかりやすく、初見であっても、ものの数分でDCRを構築することができる。
- BigQueryのユーザーベースと、このセットアップのハードルの低さがあればDCR普及の起爆剤になりえる。
- ただし、分析シナリオが双方で合意できていないと、データ公開におけるテーブル(ビュー)側の準備といったハードルはまあまあありそう。
丸ごと公開して自由に分析させる!みたいな使わせ方だと相性がいいかも。
前回までSnowflakeのデータクリーンルームを徹底検証し、今回BigQueryの調査ができました。
例にあげたようなマーケ領域におけるシンプルなシナリオでできることは近しいですが、クエリに対する制限のかけ方など、両者で機能面は大きく違います。次はそのあたりの比較や使いどころの考察をしてみたいと思います!乞うご期待!!!










この記事へのコメントはありません。