こんにちは、石原と申します。
自然言語処理(NLP)は近年のAI活用の中でビジネスユーザーとコンピュータをつなぐ重要な技術となっています。NLPはコンピュータが人間の言語を理解し、処理するための技術です。その中でも特にテキストエンベディングという手法は大規模なデータをLLMに学習させ、セマンティック検索やテキスト分類を実現するために重要になっています。本記事ではテキストエンベディングについて解説し、近傍ベクトル検索を実装してみます。
テキストエンベディングとは
通常、テキストデータは文章あるいは単語の形になっており、コンピュータにそのままの形で扱わせることは困難です。ここで必要となるのがテキストの数値化です。テキストエンベディングは簡単に説明すると、テキストデータを数値ベクトルに変換する手法です。この数値ベクトルは、コンピュータが理解しやすい形式で表現されます。
また、テキストエンベディングの効力は数値変換にとどまらず、その文章や単語の持つ意味を捉えることが可能になっています。ベクトルとなったテキストは多次元空間上のデータ点として扱うことが可能ですが、類似した意味を持つテキストは空間上で近い位置に配置されます。これにより分類問題や検索タスクにおいて重要であるテキストの類似性を空間上の2点間の位置によって処理することができるようになります。
Embeddings for Text
Vertex AI Embeddings for TextはGoogleによって2023年5月10日に発表されたAPIサービスです。
このAPIではテキストデータ入力として受け取り、768次元の数値ベクトルを出力します。
エンべディング API と LLM を組み合わせることで、以下の様々なテキスト処理タスクが実現できます。
- セマンティック検索:検索ワードの持つ意味や類似概念をテキストエンベディングから取得することができるため、これまでにない曖昧なワードによる意味検索を簡単な手順で行うことができる
- テキスト分類:テキストエンベディングを用いることで、これまでのテキスト分類手法と異なり、学習やファインチューニングを必要とせず(ゼロショット学習)に高精度のテキスト分類を行うことが可能になる
- レコメンデーション:テキストエンべディングは、レコメンデーションにおいて有効な特徴量として使用でき、類似概念の理解が可能なことから製品とテキストの関係を学習させることに用いることができる
以下ではテキスト分類のタスクを実施していきます。
費用
Vertex AIの費用についてはVertex AI の料金を確認ください。
テキストエンベディングについては1000文字あたり$0.0001が必要になります。
実装の手順
今回の実装ではGoogle公式のJupyterノートブック「Use Vector Search and Vertex AI embeddings for text for StackOverflow questions」を参考に実装していきます。
今回使用するサービスはVertex AI Embeddings for Textです。
使用するためにはGCPプロジェクトでの「Vertex AI API」の有効化が必要になります。有効化されていない方はこちらから有効化してください。
データセットは公式ノートブックと同じくStackOverflowのデータを用います。その他のテキストで確認する場合は、必要に応じてテキストデータの取り込み処理を変更してください。本記事ではGoogle colabを使用しています。使用しているコードはこちら。
まずは必要なモジュールのインストールを行います。
以下のモジュールのインストール後はランタイムの再起動が必要になります。
!pip3 install --upgrade google-cloud-aiplatform \
google-cloud-storage \
'google-cloud-bigquery[pandas]'
下記のメッセージが表示されたらランタイムのリスタートを行ってください。

次にプロジェクトのIDとリージョンを環境変数に入力します。
PROJECT_ID = "YOUR-PROJECT-ID"
REGION = "asia-northeast1"
!gcloud config set project {PROJECT_ID}
アカウントの認証情報をcolabに反映させます。
ポップアップでアカウントの選択画面が表示されますのでプロジェクトへの認証情報を持つアカウントを選択してください。
from google.colab import auth
auth.authenticate_user()
今回使用するモデルはtextembedding-gecko-multilingualです。こちらのモデルは英語以外の言語に対応したエンベディングモデルになっています。
また、タスクタイプの選択を行います。今回はカテゴリ分類のタスクなのでCLUSTERINGを選択しました。
import vertexai
from vertexai.language_models import TextEmbeddingInput, TextEmbeddingModel
import pandas as pd
import json
import os
# Set the model name.
MODEL_NAME = "textembedding-gecko-multilingual@latest"
# Set the task_type, text and optional title as the model inputs.
TASK_TYPE = "CLUSTERING"
# Initiate Vertex AI
vertexai.init(project=PROJECT_ID, location=REGION)
テキストデータの準備
import vertexai
from vertexai.language_models import TextEmbeddingInput, TextEmbeddingModel
import pandas as pd
import json
import os
# Set the model name.
MODEL_NAME = "textembedding-gecko-multilingual@latest"
# Set the task_type, text and optional title as the model inputs.
TASK_TYPE = "CLUSTERING"
# Initiate Vertex AI
vertexai.init(project=PROJECT_ID, location=REGION)
それでは、テキストデータの取り込みを行います。参考資料ではBig QueryにアップロードされたStackOverflowのデータをもとに実装を行っています。本記事ではそれに追加してGoogle DriveとGoogle Cloud Storage(GCS)の例も紹介します。
BigQueryにテーブルとして保存されている場合
今回の例ではid,title,bodyという3つのカラムを持つテーブルを対象にしています。
テーブルのカラムとテーブル名によってQUERY_TEMPLATEの値を変更してください。
以下のコードではBigQuery APIを用いてquery_bigquery_chunksというジェネレータ関数を作成しております。これはメモリ上へ大容量のテキストが展開されることを防ぐためのコードになっております。実行の都度、max_rows行読み込むまでrows_per_chunk個ずつレコードを抽出しながらデータを取得していきます。
import math
from typing import Any, Generator
import pandas as pd
from google.cloud import bigquery
client = bigquery.Client(project=PROJECT_ID)
QUERY_TEMPLATE = """
SELECT distinct q.id, q.title, q.body
FROM (SELECT * FROM `bigquery-public-data.stackoverflow.posts_questions` where Score>0 ORDER BY View_Count desc) AS q
LIMIT {limit} OFFSET {offset};
"""
def query_bigquery_chunks(
max_rows: int, rows_per_chunk: int, start_chunk: int = 0
) -> Generator[pd.DataFrame, Any, None]:
for offset in range(start_chunk, max_rows, rows_per_chunk):
query = QUERY_TEMPLATE.format(limit=rows_per_chunk, offset=offset)
query_job = client.query(query)
rows = query_job.result()
df = rows.to_dataframe()
yield df
# 100件のレコードを取得
df = next(query_bigquery_chunks(max_rows=100, rows_per_chunk=100))
Google Driveの場合
Google Driveを使用する場合は以下のコマンドを実行してドライブをマウントしてください。
from google.colab import drive
drive.mount('/content/drive')
lsコマンドでフォルダの中身を確認できます。
!ls /content/drive/MyDrive/
実行後は、/content/drive/MyDrive/以下に自分のGoogleDriveのファイルが配置されているため、そちらからファイルにアクセス出来ます。
file_name = "test.csv"
filepath = f'/content/drive/MyDrive/{file_name}'
df = pd.read_csv(filepath)
Google Cloud Strageの場合
Google Cloud Strageを使用する場合はバケット名とファイル名を指定してください。
BUCKET_NAME = "your-bucket-name"
file_name = "test.csv"
読み込みの際にはファイルを一度byte文字列としてダウンロードします。
byte文字列をデコードすることでファイルとして読み込んでいます。
import io
from google.cloud import storage
# gcsのクライアントを作成
client = storage.Client()
# バケットを取得
bucket = client.bucket(BUCKET_NAME)
# ファイルのblobインスタンスを取得
blob = bucket.blob(file_name)
# byte文字列としてダウンロード
byte_string = blob.download_as_bytes()
# byte文字列をデコード
file = io.BytesIO(byte_string)
df = pd.read_csv(file)
エンベディング処理
データの読み込みが完了したらテキストエンベディングを実装していきます。
import vertexai
from vertexai.language_models import TextEmbeddingInput, TextEmbeddingModel
def text_embedding(
model_name: str, task_type: str, text: str, title: str = "") -> list:
"""Generate text embedding with a Large Language Model."""
model = TextEmbeddingModel.from_pretrained(model_name)
text_embedding_input = TextEmbeddingInput(
task_type=task_type, title=title, text=text)
embeddings = model.get_embeddings([text_embedding_input])
return embeddings[0].values
それではテキストデータを関数に入力していきます。
今回の例ではv.bodyがメインテキストになっていますが、この部分はデータのフォーマットに合わせて変更してください。
embeddings = []
for v in df.itertuples():
TEXT = v.body # メインとなるテキスト
if TASK_TYPE != 'RETRIEVAL_DOCUMENT':
embedding = text_embedding(model_name=MODEL_NAME, task_type=TASK_TYPE, text=TEXT)
else: # RETRIEVAL_DOCUMENTの場合はタイトルの入力が可能
TITLE = v.title # タイトルとなるテキスト
embedding = text_embedding(model_name=MODEL_NAME, task_type=TASK_TYPE, text=TEXT, title=TITLE)
embeddings.append(embedding)
以上で、テキストからのエンベディングが完了しました。
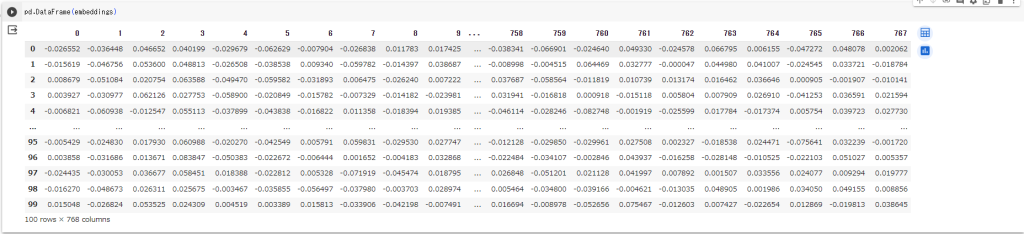
以下のコマンドで内容を確認すると、テキストが768次元の数値 = エンベディング空間上のベクトル値として変換されていることがわかります。
pd.DataFrame(embeddings)
まとめ
今回はVertex AI Embeddings for Textを使用したテキストのベクトル化を行っていきました。
得られた数字を人の目で見ても意味を理解することはできませんが、このベクトル値にはコンピュータがテキストを高精度で理解できるようなエッセンスが含まれています。
この数値を用いることで、2つの文章の類似度を判定したり、キーワードで検索する際に完全一致ではなく意味の類似度で検索することが可能になります。
次回は入力したテキストに対して類似するテキストを検索する仕組みを確認していきます。
エクスチュアはマーケティングテクノロジーを実践的に利用することで企業のマーケティング活動を支援しています。
ツールの活用にお困りの方はお気軽にお問い合わせください。