こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
以前Firebase AnalyticsのBigQueryスキーマをフラットな一行のCSVに変換するための処理をNode.jsで書きました。
Firebase AnalyticsのデータをフラットなCSVに変換するETL処理
しかしこれではあまりGoogle Cloud Platformの素晴らしさが伝わらないので、今回はCloud Dataflowを使って同じことを実装します。
Cloud Dataflowの資料を探すと、とりあえずApache Beamの公式サイトのドキュメント読んどけという答えが多いので、読みながら進めます。
Eclipseの開発環境を用意する
まずはGoogleのクイックスタートのとおりに開発環境を準備します。
このクイックスタートのとおりに進むと、DataflowパイプラインをEclipseから実行出来るようになります。
次は実装のステップに進みます。
パイプラインを実装する
FirebaseAnalyticsのスキーマは、改行で区切られたJSONファイルです。(newline delimited JSON)
Dataflowでは一行ずつインプットを受け取って、それを変換したものをアウトプットに出していくのですが、その変換するプログラムをBeam SDKで実装してDataflowで実行するという流れです。
本家Apache Beamのサイトでそこらへんは詳しく説明してます。
Design Your Pipeline | Apache Beam
で、早速実装したのがこれです。
ブログで晒すには長めのソースコードなので、githubにおいときます。
FirebaseJsonConvert.java
ソースコード解説
まずは基本的なところと設定まわりです。
public interface DflOptions extends PipelineOptions {
String getInput();
void setInput(String value);
String getOutput();
void setOutput(String value);
}
public static void main(String[] args) {
PipelineOptionsFactory.register(DflOptions.class);
DflOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().as(DflOptions.class);
Pipeline p = Pipeline.create(options);
PCollection<String> lines = p.apply("ReadJsonFile", TextIO.read().from(options.getInput()));
PCollection<String> output = lines.apply("FlattenJsonFile", ParDo.of(new FlattenJsonFn()));
output.apply("WriteTsvFile", TextIO.write().to(options.getOutput()).withSuffix(".tsv"));
p.run().waitUntilFinish();
}
Dataflowの基本は、PCollectionオブジェクトにしたインプットを「ゴニョゴニョと変換」してさらに新しいPCollectionオブジェクトを生成して、最後にそれをアウトプットするというものです。
mainメソッドの中で、Pipelineを初期化して、そのパイプラインからインプットファイルを一行ずつ読み込んでPCollectionを作ります。
このPcollectionにはJSONの1行=1レコードが入ってきます。
実行時の引数で input= と output= でそれぞれ入力ファイルと出力ファイル(のprefix)を指定するので、PiplineOptionsを継承したDflOptionsというインターフェースを実装します。
これでgetterとsetterが出来上がるので、引数の値をやり取りする時に使います。
PCollectionに入ってるJSONをフラットなTSVに変換するのがFlattenJsonFnで、これはDoFnのサブクラスとして作ってあります。
このFlattenJsonFnを、ParDoという並列処理に引数として渡して実行します。
そこのソースコードはこうなってます。
private static class FlattenJsonFn extends DoFn<String, String> {
@ProcessElement
public void processElement(ProcessContext c) {
String json = c.element();
StringBuffer cols = new StringBuffer();
try {
JSONParser jsonParser = new JSONParser();
JSONObject jsonObject = (JSONObject) jsonParser.parse(json);
JSONObject data_user= (JSONObject) jsonObject.get("user_dim");
JSONArray data_event= (JSONArray) jsonObject.get("event_dim");
//user_dimの展開
String user_id = "";
String first_open_timestamp_micros = "";
user_id = (String) data_user.get("user_id");
try { first_open_timestamp_micros = (String) data_user.get("first_open_timestamp_micros"); } catch(Exception e) {}
JSONObject device_info = (JSONObject) data_user.get("device_info");
//以下中略
} catch (Exception e) {}
String rows = cols.toString();
c.output(rows);
}
}
json-simpleというパーサーを使って、JSONを展開し、値を取り出してフラットな一行のStringに変換するという事をやってます。
FirebaseAnalyticsのスキーマは、user_dimというセッションデータと、event_dimというヒットデータの2つの要素で構成されてます。
何層にもネストになったJSONなので、都度JSONArrayをforループで展開しながら読み込んでます。
そこらへんはgithubに載ってるソースコードを見れば分かる事でしょう。
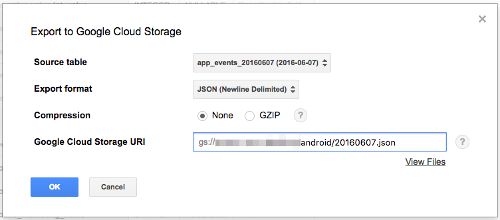
FirebaseAnalyicsのJSONスキーマをCloud Storageに置く
今回はFirebase Demo ProjectのBigQueryデータを使います。
これをCloud StorageにJSON形式でエクスポートします。

20160607のデータを選んでからExport Tableで、Cloud Storageのバケットとファイルパスを指定してエクスポートします。
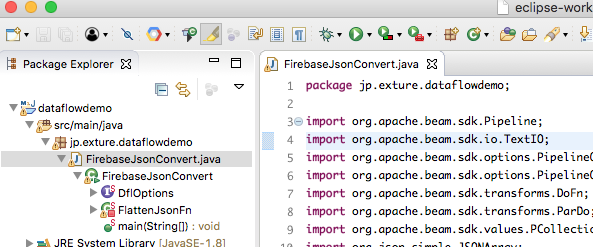
Eclipse上でビルドする
さて、Eclipseを使ってこのソースコードをビルドします。
新規プロジェクト作成で、Google Cloud Dataflow Java Project を作成するか、または先程クイックスタートで作ったWordCountのプロジェクトを再利用してください。

次に、FirebaseJsonConvert.javaをプロジェクトに追加します。
package名は適当に変えるなりしてください。
ビルドするためにはjson-simpleライブラリが必要です。
json-simple
プロジェクトのpom.xmlを開いて、dependencies要素内に、下記を追加します。
<dependency> <groupId>com.googlecode.json-simple</groupId> <artifactId>json-simple</artifactId> <version>1.1.1</version> </dependency>
EclipseからDataflowパイプラインを実行する
ではEclipseからこのパイプライン処理をDatafow上で実行します。
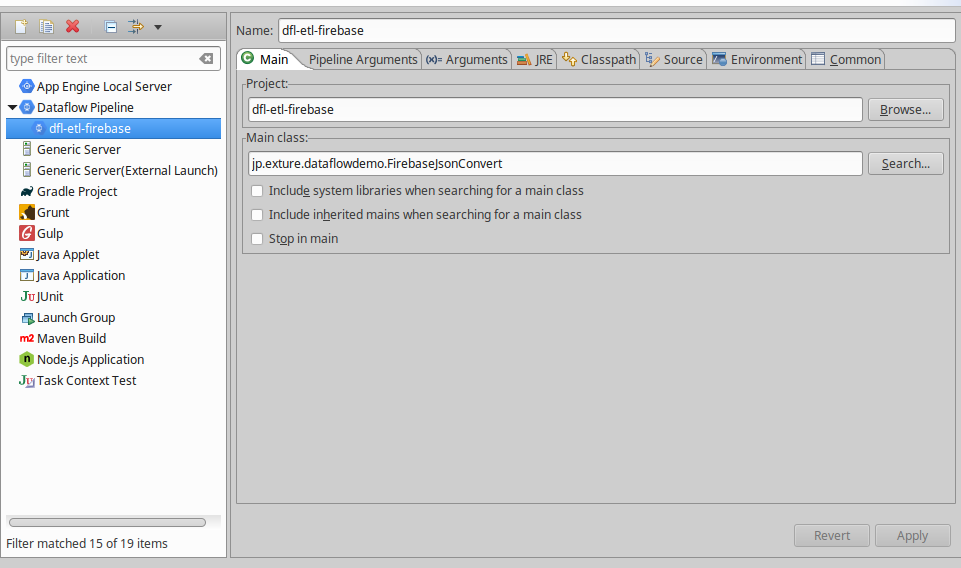
Run -> Run Configurations を開き、左側のペインからDataflow Pipelineを選びます。
1. Mainタブを開き、下記を設定してApplyします。
Name: 適当に名前をつける
Project: このプロジェクトを選ぶ
Main class: jp.exture.dataflowdemo.FirebaseJsonConvert
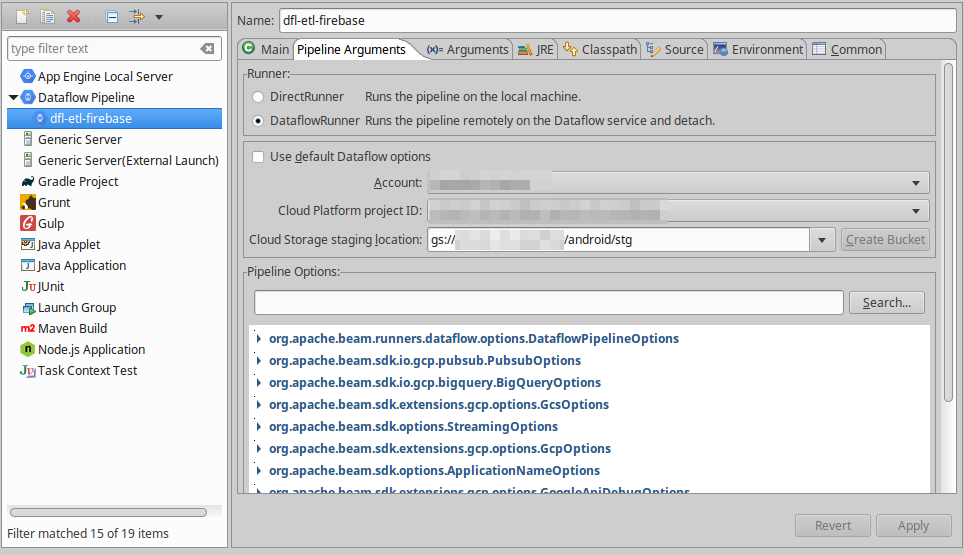
2. Pipline Argumentsタブを開き、下記を設定してApply
Runner: DataflowRunnerを選択
Account: GCPのログインアカウントを選択
Cloud Platform project ID: Dataflowを実行するGCPプロジェクトを選択
Cloud Storage staging location: ステージングファイルを置くCloud Storage上のフォルダを選択。
↑ステージング用フォルダをバケット上に作っておいてください。
3. Argumentsタブを開き、Program Argumentsに下記を入力してApply
--input=gs://<bucket名>/<エクスポートしたファイル名> --output=gs://<bucket名>/アウトプットファイルのprefix
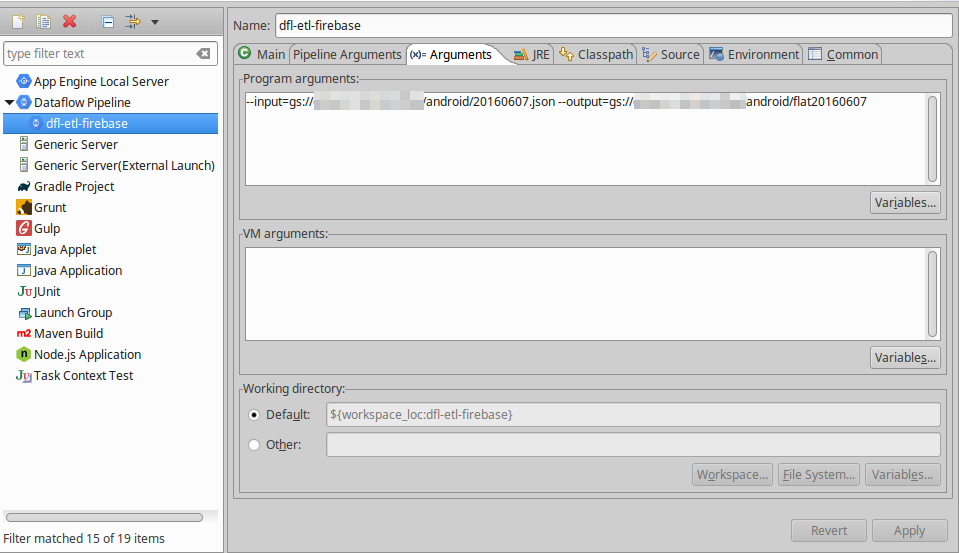
outputは自動的に拡張子.tsvを付与するので、ファイルのprefixだけを指定します。
そしてRunボタンを押すと実行されます。
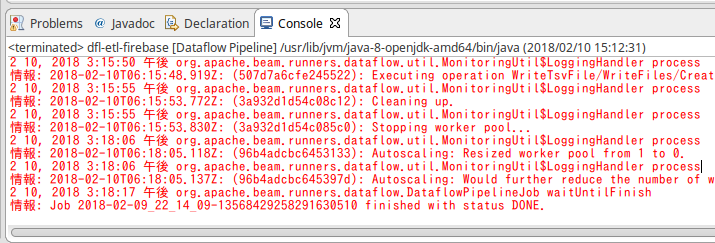
Eclipseのコンソールに、実行中の状況が出力されます。
実行に成功すると、finished with status DONE. というメッセージが出て終了します。
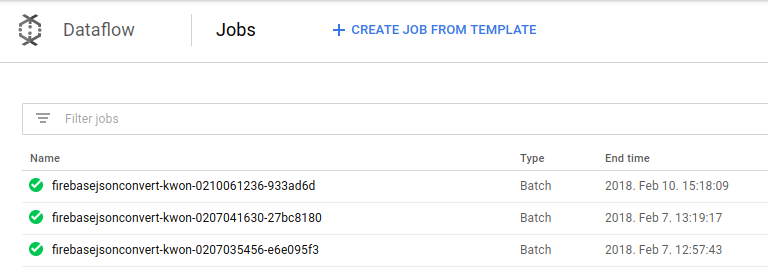
Dataflowコンソールには、実行したJobの一覧が出てきます。
成功したJobには緑のチェックアイコンがついてます。
Cloud Storageを見ると、変換されたTSVファイルが4つ出来ています。

複数のWorkerによって分割処理されるので、このように結果が自動的に分割されて出力されます。
出来上がったTSVファイルを見ると、イベント毎(ヒット毎)に一行のフラットなデータに変換されて出力されている事が確認出来ます。
おまけ:コマンドラインから実行する
Eclipseではなくて、コマンドラインで実行したい場合は、mavenコマンドで実行します。
$ mvn compile exec:java \
-Dexec.mainClass=jp.exture.dataflowdemo.FirebaseJsonConvert \
-Dexec.args="--project=<project名> \
--stagingLocation=gs://<バケット名>/<ステージングフォルダ>/ \
--input=gs://<バケット名>/<入力ファイル> \
--output=gs://<バケット名>/<出力ファイルのprefix> \
--runner=DataflowRunner"
今回はCloud Dataflowパイプラインを使って、FirebaseAnalyticsのBigQueryスキーマをJSON型からフラットなTSVファイルに変換する方法について説明しました。
弊社では、Google Cloud Platformを使って、FirebaseAnalytics, GoogleAnalytics, AdobeAnalyticsなど各デジタル解析ソリューションのデータを分析するための基盤構築支援業務を行っております。
お問い合わせはこちらからどうぞ。
ブログへの記事リクエストはこちらまで