こんにちは、エクスチュアの黒岩と申します。
前回の記事では、Google Cloud Platform(GCP)のサービスであるCloud Workflowsについて、基本的な機能や利点・使用方法など、サービスの概要について紹介しました。
本記事では実践編ということで、実務で想定されるデータパイプラインの実装を行い、Workflowsの理解を深めていくことをゴールに書き進めていこうと思います。
是非最後までお付き合いください!
この記事で実装するデータパイプラインの確認
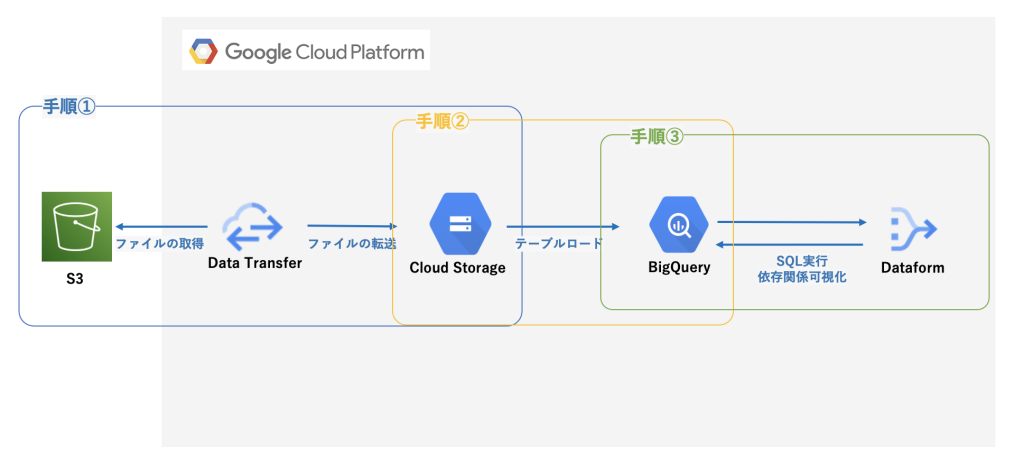
まず最初に、今回実装を進めていくデータパイプラインを確認していきましょう。
大きく以下3つの手順の処理を、Cloud Workflowsで実装していきます。
- AWS S3に存在するファイルをGCSへ転送
- 転送したファイルをBigQueryにロード
- dataformを使用してSQLを実行
※前提として、Data transferやDataform等各種サービスの実装は完了しているものとします
データパイプラインの実装
1. AWS S3に存在するファイルをGCSへ転送
S3からGCSへのファイル移動は、GCPのサービスであるData Transfer (Storage Transfer Service)を使用しています。
※test-transfer-1, test-transfer-2という名前のジョブが作成済みであることを仮定
◎完成版コード (run-datatransfer)
main:
steps:
- assign_val:
assign:
- project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- workflow_location: ${sys.get_env("GOOGLE_CLOUD_LOCATION")}
- transferjob_names:
- transferJobs/test-transfer-1
- transferJobs/test-transfer-2
- workflow_name: run-gcs-to-bq
- call_execute_transfer_job:
call: execute_transfer_job
args:
project_id: ${project_id}
transferjob_names: ${transferjob_names}
- call_fetch_next_workflow:
call: fetch_next_workflow
args:
project_id: ${project_id}
workflow_location: ${workflow_location}
workflow_name: ${workflow_name}
execute_transfer_job:
params: [project_id, transferjob_names]
steps:
- execute_parallel:
parallel:
for:
value: transferjob_name
in: ${transferjob_names}
steps:
- start_log:
call: sys.log
args:
text: ${transferjob_name + "の転送を開始します"}
severity: INFO
- transfer_job:
try:
call: googleapis.storagetransfer.v1.transferJobs.run
args:
jobName: ${transferjob_name}
body:
projectId: ${project_id}
result: transfer_result
except:
as: e
steps:
- output_transfer_error_log:
switch:
- condition: ${e.code == 404}
call: sys.log
args:
text: ${transferjob_name + "は存在しません。"}
severity: ERROR
- finish_transfer_job:
raise: ${e}
- end_log:
call: sys.log
args:
text: ${transferjob_name + "の転送が正常に終了しました。"}
severity: INFO
fetch_next_workflow:
params: [project_id, workflow_location, workflow_name]
steps:
- fetch_run-gcs-to-bq:
call: http.post
args:
url: ${"https://workflowexecutions.googleapis.com/v1/projects/" + project_id + "/locations/" + workflow_location + "/workflows/" + workflow_name + "/executions"}
auth:
type: OAuth2
◎解説
mainというワークフローとは別に、2つのサブワークフローを定義する構成としました。
pythonでmain関数とは別に各処理の関数を定義し、main関数で引数を与えて呼び出すことと同じ状態ですね。サブワークフローを順に見てみましょう。
execute_transfer_job
ポイントは2つです。
1. for を使用し、引数に与えられた transferjob_names の値をループさせ、APIの引数に渡して実行している点
2. parallel を使用し、API呼び出しを並列実行している点
転送ジョブ自体に依存関係がない場合、このように並列実行をさせることも可能です。
fetch_next_workflow
ここでは次に実行したいワークフロージョブをAPI経由で実行する処理を行なっています。
認証にはGoogleの認証機能であるOAuth2を指定することが可能です。
2. 転送したファイルをBigQueryにロード
run-datatransferジョブのコード終盤に、 run-gcs-to-bq という名前のワークフロージョブを呼び出すよう記述されていたと思います。run-gcs-to-bq の中身を見てみましょう。
◎完成版コード (run-gcs-to-bq)
main:
steps:
- assign_val:
assign:
- project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- dataset_id: "exture_dataset"
- table_name: "exture_table"
- schema: [
{"name": "id", "type": "INTEGER"},
{"name": "name", "type": "STRING"},
{"name": "register_date", "type": "DATE"}
]
- bucket_name: "source_bucket"
- yesterday: ${text.split(time.format(sys.now() - 86400), "T")[0]}
- target_file_date: ${text.replace_all(yesterday, "-", "")}
- object_name: ${"employee/result_" + target_file_date + ".csv"}
- skipLeadingRows: 1
- workflow_location: ${sys.get_env("GOOGLE_CLOUD_LOCATION")}
- workflow_name: run-dataform
- call_table_check:
call: check_table_status
args:
project_id: ${project_id}
dataset_id: ${dataset_id}
table_name: ${table_name}
schema: ${schema}
- call_common_load_csv_to_bigquery:
call: common_load_csv_to_bigquery
args:
bucket_name: ${bucket_name}
object_name: ${object_name}
skipLeadingRows: ${skipLeadingRows}
project_id: ${project_id}
dataset_id: ${dataset_id}
table_name: ${table_name}
schema: ${schema}
- call_fetch_next_workflow:
call: fetch_next_workflow
args:
project_id: ${project_id}
workflow_location: ${workflow_location}
workflow_name: ${workflow_name}
result: fetch_result
check_table_status:
params: [project_id, dataset_id, table_name, schema]
steps:
#テーブルが存在していなければ作成する
- get_table_status:
try:
call: googleapis.bigquery.v2.tables.get
args:
projectId: ${project_id}
datasetId: ${dataset_id}
tableId: ${table_name}
result: get_table_result
except:
steps:
- create_table:
call: googleapis.bigquery.v2.tables.insert
args:
projectId: ${project_id}
datasetId: ${dataset_id}
body:
tableReference:
projectId: ${project_id}
datasetId: ${dataset_id}
tableId: ${table_name}
schema:
fields: ${schema}
result: create_table_result
- output_create_table_result:
call: sys.log
args:
text: ${table_name + "を作成しました。"}
common_load_csv_to_bigquery:
params: [bucket_name, object_name, skipLeadingRows, project_id, dataset_id, table_name, schema]
steps:
#変数宣言
- assign_val:
assign:
- gcs_source_file: ${"gs://" + bucket_name + "/" + object_name}
#引数で渡されたオブジェクト名を、APIが読み取れるようエンコードする
- url_encode:
call: text.url_encode
args:
source: ${object_name}
result: encoded_object_name
#処理開始のログ出力
- start_log:
call: sys.log
args:
text: ${table_name + "の更新処理を開始します"}
severity: INFO
#読み込む対象のcsvファイルが存在しているか判別し、ファイルが存在しない場合は終了
- get_csv_file:
try:
call: googleapis.storage.v1.objects.get
args:
bucket: ${bucket_name}
object: ${encoded_object_name}
result: csv_result
except:
as: e
steps:
- output_object_error_log:
switch:
- condition: ${e.code == 404}
call: sys.log
args:
text: ${object_name + "ファイルが存在しません。"}
severity: ERROR
- finish_get_csv_job:
raise: ${e}
#csvファイルの情報を出力
- output_csv_result:
call: sys.log
args:
text: ${csv_result}
severity: INFO
#GCSに配置されたファイルをBQにロードする処理
- load_csv_to_bigquery:
try:
call: googleapis.bigquery.v2.jobs.insert
args:
projectId: ${project_id}
body:
configuration:
load:
skipLeadingRows: ${skipLeadingRows}
fieldDelimiter: ","
allowQuotedNewlines: true
encoding: UTF-8
writeDisposition: WRITE_TRUNCATE
sourceFormat: CSV
sourceUris: ${gcs_source_file}
destinationTable:
projectId: ${project_id}
datasetId: ${dataset_id}
tableId: ${table_name}
schema:
fields: ${schema}
result: bq_load_result
except:
as: e
steps:
- output_insert_error_log:
call: sys.log
args:
text: ${table_name + "の更新ができませんでした"}
severity: ERROR
- finish_insert_job:
raise: ${e}
#BigQueryへのロード結果を出力
- output_bq_load_result:
call: sys.log
args:
text: ${bq_load_result}
severity: INFO
#処理終了のログ出力
- end_log:
call: sys.log
args:
text: ${table_name + "の更新が正常に終了しました"}
severity: INFO
fetch_next_workflow:
params: [project_id, workflow_location, workflow_name]
steps:
- fetch_run-dataform:
call: http.post
args:
url: ${"https://workflowexecutions.googleapis.com/v1/projects/" + project_id + "/locations/" + workflow_location + "/workflows/" + workflow_name + "/executions"}
auth:
type: OAuth2
◎解説
このワークフロージョブも同様に、mainからサブワークフロージョブを呼び出す構成です。
各サブワークフローの詳細は割愛しますが、基本的には用意されたテーブル作成やロード処理を行うためのAPIを実行しているジョブとなります。text.url_encodeというワークフロー側で用意された関数も使用していることがお分かりいただけると思います。
※上記コードは1つのテーブルのみのロードを想定していますが、複数テーブル共通して使用できるようジョブの共通化も可能です。ご質問等お気軽にお問い合わせください。
3. dataformを使用してSQLを実行
最後に、run-gcs-to-bq によって呼び出されるrun-dataform ジョブを見ていきましょう。
◎完成版コード (run-dataform)
main:
steps:
- assign_val:
assign:
- project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- repository_location: ${sys.get_env("GOOGLE_CLOUD_LOCATION")}
- repository_id: exture_repo
- repository: ${"projects/" + project_id + "/locations/" + repository_location + "/repositories/" + repository_id}
- createCompilationResult:
call: http.post
args:
url: ${"https://dataform.googleapis.com/v1beta1/" + repository + "/compilationResults"}
auth:
type: OAuth2
body:
gitCommitish: main
result: compilationResult
- invocation_log:
call: sys.log
args:
text: "dataformを実行します"
severity: INFO
- createWorkflowInvocation:
call: http.post
args:
url: ${"https://dataform.googleapis.com/v1beta1/" + repository + "/workflowInvocations"}
auth:
type: OAuth2
body:
compilationResult: ${compilationResult.body.name}
result: workflowInvocation
- complete:
return: ${workflowInvocation.body.name}
◎解説
こちらのジョブは今までのジョブとは異なり、サブワークフローを定義せずmain関数内に全て処理を記述する構成です。(dataformを実行するためのAPIを呼び出すという単一の処理であるため)
createCompilationResult
dataformでは、実際にBigQuery上でクエリが実行できるかどうかを検証するためのコンパイルという機能があります。このコンパイルは、gitCommitish というキーで指定しているmainという値の通り、接続されたgitのmainブランチで行われるようになっています。
createWorkflowInvocation
dataformをAPI経由で実行するステップです。リポジトリ名を指定することで実行が可能です。
以上で簡単なデータパイプラインの実装が完了です、お疲れ様でした!
今回はワークフロー間で引数の受け渡しをするような実装は行いませんでしたが、JSON形式で渡して後続ジョブがその値を使用して処理を実行するといったこともワークフローは可能です。
例:target_dateというパラメーターを持たせ、処理対象の日付を柔軟に指定する
終わりに
本記事では、実務で想定されるデータパイプラインの実装を行い、実例とともにWorkflowsの理解を深めていくことに焦点をあてて書いてみました!前編の概要編と合わせて読んでくださった方、いかがでしたでしょうか?何より読んでくださったことに感謝申し上げます🙏
今後もCloud Workflowsはもちろん、様々なGCPサービスを使用することで活用しやすいデータ基盤を構築していきます。またの記事を楽しみにお待ちいただけると嬉しいです!
エクスチュアはGoogle Cloud Platformのサービスパートナーです。
Cloud WorkflowsやGA4を含むGoogle Cloud Platform、Adobe Experience Cloud、Tableau、Lookerなどに精通したスタッフによるデータ活用サポート、各マーケティングツールの導入実装・活用支援のコンサルティングサービスや、GCP/AWSなどのパブリッククラウドを使ったデータ分析基盤構築コンサルティングサービスを提供しております。