
こんにちは、喜田です。
この記事では、複雑なSnowflakeのデータクリーンルーム(Data Clean Room:DCR)をしっかり理解することを目指して、極力親切に、DCRに期待される機能や構築に必要なパーツを紐解いて解説していきます。
ここまで、DCR構築に必要な要素として行アクセスポリシー(Row Access Policy:RAP)を中心に必要な知識を細かくお伝えしてきました。
今回はいよいよ実践編。検証用アカウントを用意するところから!サンプルデータを用意するところから!全部手順をお見せします。
構築の前提条件、注意事項
- 検証用アカウントをこれから用意する場合、ORGADMINが必要です。
もしくは、社内のORGADMINにまっさらな検証用アカウントを2つ用意してもらって、両アカウントでACCOUNTADMINをもらってください。 - 別の記事にする予定ですが、今回作るDCRは要素技術を理解する目的であって、実用性でいうとQuickStartのスクリプトが勝ります。(とは言えそちらも権限管理など考慮することはあるのですが。)あくまでも検証用、動作の勉強用としてお使いください。
構築する全体像
パーティーAはプロバイダーとして、件数が多く独自に顧客属性を付与したテーブルを持っています。パーティーBはコンシューマとしてAからデータを購入します。これにより、自社だけでは分かりえなかった自社顧客の属性を理解し、より効果的な商品開発やマーケ活動に活かすことを期待しています。
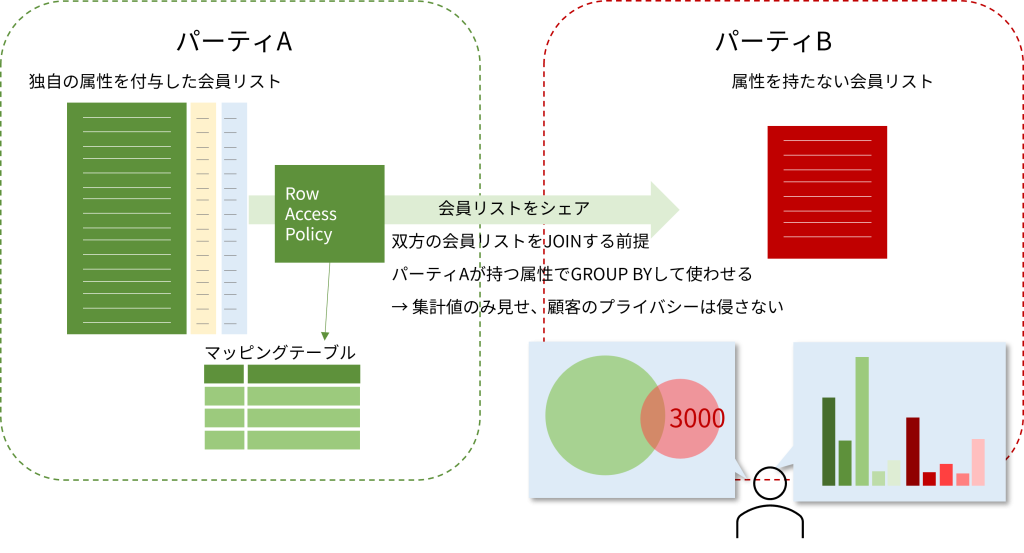
検証の全体像を示します。
【手順1】アカウント発行
【手順2】アカウントレベルの初期設定
【手順3】検証用データの準備
【手順4】プロバイダーでデータ提供を開始
【手順5】コンシューマでシェアを受領してクエリ
【手順1】アカウント発行
検証用に2つのアカウントを発行します。ある程度Snowflakeを触った経験があって諸々切り分けができる方はどこかのアカウントに相乗りでもかまいません。
USE ROLE orgadmin;
/* プロバイダーアカウントを用意 */
CREATE ACCOUNT DCR_PROVIDER
ADMIN_NAME = myname
ADMIN_PASSWORD = 'mypasswrod'
FIRST_NAME = myfirstname
LAST_NAME = mylastname
EMAIL = 'name@mail.jp'
MUST_CHANGE_PASSWORD = FALSE
EDITION = ENTERPRISE
;
/* コンシューマーアカウントを用意 */
CREATE ACCOUNT DCR_CONSUMER
ADMIN_NAME = myname
ADMIN_PASSWORD = 'mypasswrod'
FIRST_NAME = myfirstname
LAST_NAME = mylastname
EMAIL = 'name@mail.jp'
MUST_CHANGE_PASSWORD = FALSE
EDITION = ENTERPRISE
;【手順2】アカウントレベルの初期設定
プロバイダー、コンシューマーの両アカウントで実施
新規アカウントで当然使うレベルの環境を整えます。考慮しているのは、自社データについての権限を持つdata_adminロールを置いているぐらいです。
ここではaccountadminを持っている前提で、適宜ロールを切り替えています。accountadminを持っていない場合は適宜社内担当者に依頼するなどしてください。
/* ロール・ユーザの用意 */
USE ROLE useradmin;
-- データ保有ロール
CREATE ROLE data_admin;
GRANT ROLE data_admin TO ROLE sysadmin;
-- 個人ユーザー
CREATE USER IF NOT EXISTS Kosuke_Kida PASSWORD = 'mypasswrod'・・・;
GRANT ROLE data_admin TO USER Kosuke_Kida;
/* クエリ実行環境の用意 */
USE ROLE sysadmin;
CREATE WAREHOUSE my_wh
WITH WAREHOUSE_SIZE = 'XSMALL'
INITIALLY_SUSPENDED = TRUE
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
MIN_CLUSTER_COUNT = 1
MAX_CLUSTER_COUNT = 1;
GRANT usage,monitor,modify,operate ON WAREHOUSE my_wh TO ROLE data_admin;
Snowflakeがトレーニング用に公開しているTPC-Hベンチマーク用のサンプルテーブルを各アカウントで参照できるようにしておきます。
/* サンプルデータベースのロード */
USE ROLE accountadmin;
CREATE DATABASE SNOWFLAKE_SAMPLE_DATA FROM SHARE SFC_SAMPLES.SAMPLE_DATA;
GRANT IMPORTED PRIVILEGES ON DATABASE SNOWFLAKE_SAMPLE_DATA TO ROLE PUBLIC;また、両アカウントのアカウントIDを取得しておきましょう。
SELECT current_account();当検証環境では以下でした。後でアカウントIDは使用しますのですぐに見つけられるように。
| プロバイダー | AA12345 |
| コンシューマー | BB98765 |
プロバイダーアカウントで実施
後でどのみち作るということで、accountadminを使えるうちにシェアを一つ用意しておきます。
/* データベースの作成 */
USE ROLE sysadmin;
CREATE DATABASE dcr_provider;
GRANT create schema,usage,monitor ON DATABASE dcr_provider TO ROLE data_admin;
-- スキーマ以下のオブジェクトはdata_adminで作成できる状態
/* シェアの準備 */
USE ROLE accountadmin;
GRANT create share ON ACCOUNT TO ROLE data_admin;
USE ROLE data_admin;
CREATE SHARE cleanroom;
SHOW SHARES;コンシューマーアカウントで実施
コンシューマ側はデータベースを用意する程度です。
USE ROLE sysadmin;
CREATE DATABASE my_db;
GRANT create schema,usage,monitor ON DATABASE my_db TO ROLE data_admin;【手順3】検証用データの準備
プロバイダーアカウントで用意するデータ
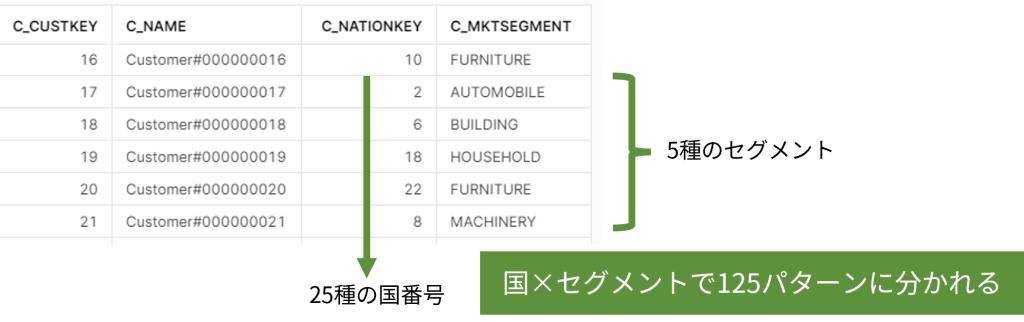
Snowflakeのサンプルデータのうち、customerテーブルを使います。
プロバイダー側企業が保有している会員リストのイメージです。
/* コンテキストの設定 */
USE ROLE data_admin;
USE WAREHOUSE my_wh;
USE DATABASE dcr_provider;
/* サンプルデータの投入 */
CREATE SCHEMA tpch;
USE SCHEMA tpch;
CREATE TABLE customer AS SELECT * FROM snowflake_sample_data.tpch_sf1.customer;データが用意できたら、中身を少し見てみましょう
SELECT * FROM tpch.customer LIMIT 10;
SELECT count(*) FROM tpch.customer; -- 全部で15万件
SELECT c_custkey,c_name,c_nationkey,c_mktsegment FROM tpch.customer LIMIT 10;
SELECT count(distinct c_mktsegment) FROM tpch.customer;
SELECT count(distinct c_nationkey) FROM tpch.customer;
SELECT c_nationkey,c_mktsegment,count(*) FROM tpch.customer GROUP BY c_nationkey,c_mktsegment;プロバイダー側では、この会員リストの出身国やマーケットセグメントといったデータを持っています。今回のDCRでは、ユーザ名(c_name)だけを持った相手に、出身国やマーケットセグメントのサマリだけを見せることを考えます。
SELECT count(distinct c_nationkey,c_mktsegment) FROM tpch.customer;
SELECT c_nationkey,c_mktsegment,count(*) FROM tpch.customer GROUP BY 1,2;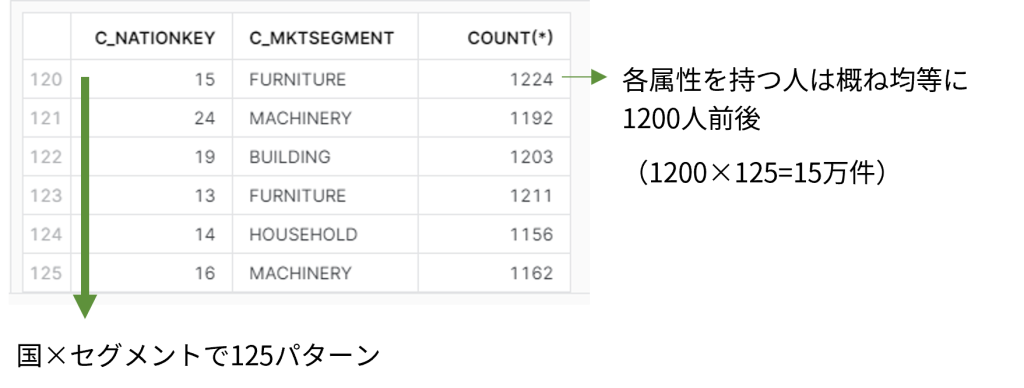
コンシューマアカウントで用意するデータ
同じTPC-Hのデータセットを用いますが、ちょっと加工して偏りのある分布にします。
USE ROLE data_admin;
USE WAREHOUSE my_wh;
USE DATABASE my_db;
CREATE SCHEMA tpch;
USE SCHEMA tpch;
CREATE TABLE customer AS SELECT c_custkey,c_name FROM snowflake_sample_data.tpch_sf1.customer
WHERE c_custkey IS NULL; -- テーブル定義のみ、c_custkey,c_name列のみ
INSERT INTO customer SELECT c_custkey,c_name
FROM snowflake_sample_data.tpch_sf1.customer
WHERE c_nationkey <> 12 ORDER BY c_address LIMIT 1000;
-- nationkey=12は'JAPAN'です
-- ここではJAPAN以外のデータを順序をバラバラにして1000件
INSERT INTO customer SELECT c_custkey,c_name
FROM snowflake_sample_data.tpch_sf1.customer
WHERE c_nationkey = 12 LIMIT 1000;
-- ここではJAPANのデータを1000件
INSERT INTO customer SELECT c_custkey+200000,c_name
FROM snowflake_sample_data.tpch_sf1.customer LIMIT 1000;
-- 元データは15万件なので20万以降のIDを振ったちょっと意図が見えづらいかもですが、コンシューマ側に用意したデータは属性が何もついていない単なる名前リスト3000件、ただしその内訳は1000件が日本人、残りの2000件が各国均等に入っています。さらに1000件はプロバイダー側には存在しないIDとしました。

「日本人が圧倒的多数を占める」という事実を、自社の顧客リストであるにもかかわらずコンシューマ企業は把握できていません。これを、個人に紐づく属性データを保有しているプロバイダー企業とのDCRで明らかにしていきます!!!
【手順4】プロバイダーでデータ提供を開始
プロバイダーでやることは、
- 行アクセスポリシーを定義してcustomerテーブルに仕掛ける
- customerテーブルをシェアに追加して相手アカウントに見せる
- 相手に実行させるクエリをRAPマッピングテーブルに登録
です。ここまでじっくり触ってきたRAPの定義ですね!
①行アクセスポリシーを定義してcustomerテーブルに仕掛ける
/* マッピングテーブルの作成 */
USE ROLE data_admin;
CREATE SCHEMA security;
USE SCHEMA security;
CREATE TABLE rap_mapping_table (account_id varchar,allowed_query varchar);
/* ポリシーの作成 */
CREATE OR REPLACE ROW ACCESS POLICY security.dcr_rap_for_customer
AS (filter_value integer) RETURNS BOOLEAN ->
'AA12345' = current_account() -- 自アカウントはRAPをバイパス
OR
EXISTS ( -- アカウントIDとクエリが登録されていれば結果を返す
SELECT 1 FROM security.rap_mapping_table
WHERE account_id = current_account()
AND allowed_query = sha2(current_statement())
)
;
/* customerテーブルにアタッチ */
ALTER TABLE tpch.customer ADD ROW ACCESS POLICY security.dcr_rap_for_customer
ON (c_custkey); -- 対象列はダミーなのでどこでも良い
②customerテーブルをシェアに追加して相手アカウントに見せる
-- 事前にcleanroomという名前でシェアを作成済み
USE ROLE data_admin;
GRANT usage ON DATABASE dcr_provider TO SHARE cleanroom;
GRANT usage ON SCHEMA tpch TO SHARE cleanroom;
GRANT select ON TABLE tpch.customer TO SHARE cleanroom;③相手に実行させるクエリをRAPマッピングテーブルに登録
ここだけ少し考えないといけないのですが、実行させるクエリそのもの、一言一句違わぬ形で許可済みにしておかないといけないので、相手が持っているスキーマ名、テーブル名、JOINのための列名などをお伺いして作ることになります。
サンプルデータとして用意したのは以下でした。
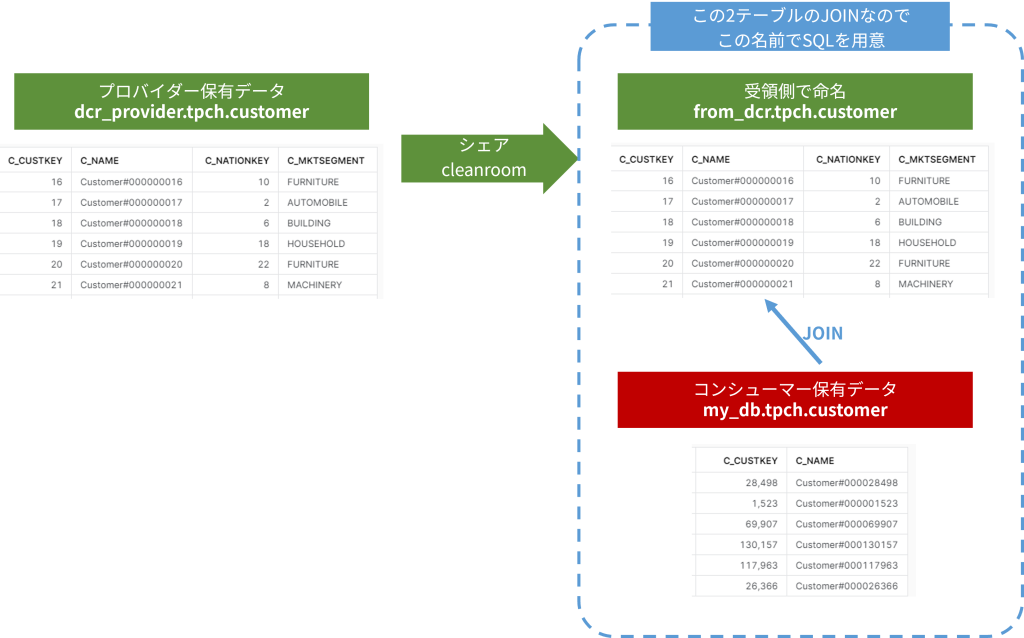
クエリA
/* 単に互いの会員テーブルをJOINしてマッチ率(件数の重なり)を調べる */
SELECT count(*)
FROM from_dcr.tpch.customer AS remote
JOIN my_db.tpch.customer AS local
ON local.c_custkey = remote.c_custkey
;
/* マッピングテーブルにクエリを登録 */
SELECT sha2($$SELECT count(*)
FROM from_dcr.tpch.customer AS remote
JOIN my_db.tpch.customer AS local
ON local.c_custkey = remote.c_custkey
;$$);
/* 結果はこんな感じ
SHA2($$SELECT COUNT(*) FROM FROM_DCR.TPCH.・・・・
----------------------------------------------------------------
d4dce26dfc5263802964d32b930c5a7d637fada96af27c99e6f2dcfa02b5a3fe
*/
-- マッピングテーブルにINSERT
INSERT INTO rap_mapping_table VALUES
('BB98765','d4dce26dfc5263802964d32b930c5a7d637fada96af27c99e6f2dcfa02b5a3fe');今回はプロバイダーと同じデータから抽出した2000件+IDを加工した1000件、計3000件をコンシューマ側に持たせましたので、コンシューマとプロバイダーのデータがマッチする2000件がカウントされるはずです。(マッチ率66%)
クエリB
/* 国×マーケットセグメントで集計して、会員の傾向を調べる */
SELECT remote.c_nationkey,remote.c_mktsegment,count(*) AS cnt
FROM from_dcr.tpch.customer AS remote
JOIN my_db.tpch.customer AS local
ON local.c_custkey = remote.c_custkey
GROUP BY remote.c_nationkey,remote.c_mktsegment
ORDER BY cnt DESC
;
/* マッピングテーブルにクエリを登録 */
SELECT sha2($$SELECT remote.c_nationkey,remote.c_mktsegment,count(*) AS cnt
FROM from_dcr.tpch.customer AS remote
JOIN my_db.tpch.customer AS local
ON local.c_custkey = remote.c_custkey
GROUP BY remote.c_nationkey,remote.c_mktsegment
ORDER BY cnt DESC
;$$);
/* 結果はこんな感じ
SHA2($$SELECT REMOTE.C_NATIONKEY,REMOTE.C_MKTSEGMENT,COUNT(*) ・・・
----------------------------------------------------------------
51613a55edb646f513108197938fd5d508c8af795f696d379bffef3e05fe66a6
*/
-- マッピングテーブルにINSERT
INSERT INTO rap_mapping_table VALUES
('BB98765','51613a55edb646f513108197938fd5d508c8af795f696d379bffef3e05fe66a6');(ちなみに・・・本クエリは改行位置含め実行するクエリと完全に一致していないといけません。ブラウザの表示幅の問題などで改行されていたとしたら気を付けて登録ください。)
ここで、「え!日本市場めちゃ熱いんじゃないの?!?!マニュアルの和訳がんばったろ!日本向けの広告費もじゃぶじゃぶつぎ込んじゃお!!!」という結果が取れるわけですね。
プロバイダーの操作は以上です。
【手順5】コンシューマでシェアを受領してクエリ
コンシューマで実施することは
- シェアの受領
- 分析クエリの実行
こ れ だ け です!!!
①シェアの受領
USE ROLE accountadmin;
CREATE OR REPLACE DATABASE from_dcr FROM SHARE AA12345.cleanroom;
GRANT IMPORTED PRIVILEGES ON DATABASE from_dcr TO ROLE PUBLIC;シェアで受領したオブジェクトは以下のように「FROM_DCR」データベース以下、スキーマ名、テーブル名はプロバイダー側の階層そのまま見えています。列定義や総件数もメタデータとしては見えていますが・・・
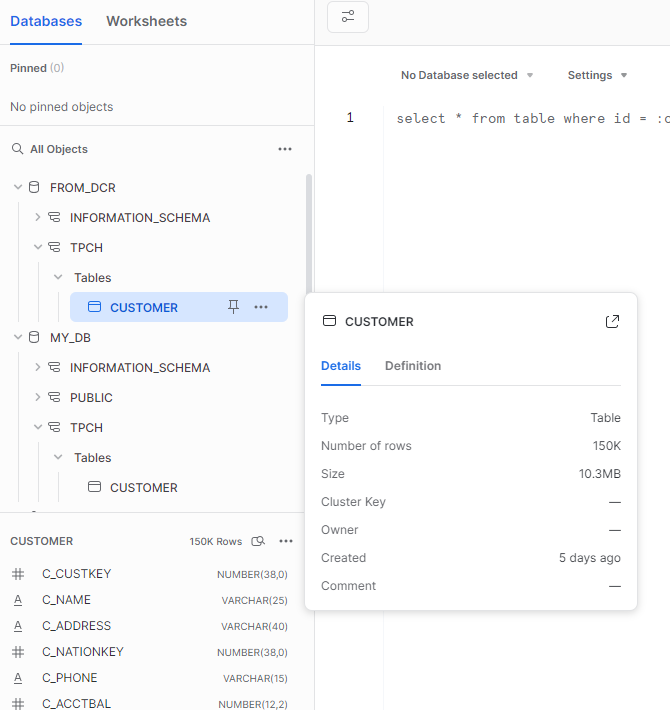
ごくシンプルなクエリを実行してみても、許可されていない操作はできません。
/* 許可されていないクエリは結果なし(countはゼロ件) */
USE ROLE data_admin;
SELECT * FROM from_dcr.tpch.customer;
SELECT count(*) FROM from_dcr.tpch.customer;
②分析クエリの実行
ではいよいよ、分析クエリを実行してみましょう!
クエリA
/* 単に互いの会員テーブルをJOINしてマッチ率(件数の重なり)を調べる */
SELECT count(*)
FROM from_dcr.tpch.customer AS remote
JOIN my_db.tpch.customer AS local
ON local.c_custkey = remote.c_custkey
;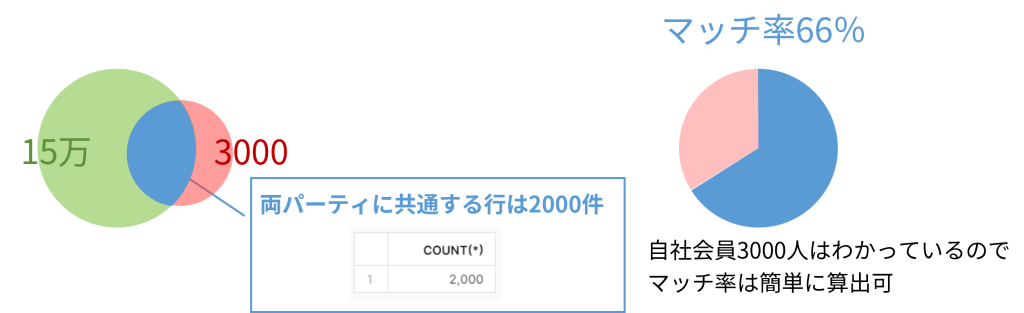
単純なSQLなので言うまでもないことかもですが、15万件のプロバイダー側会員データに対して3000件の自社会員データをあて、その件数の重なりが2000件、マッチ率を計算すれば66%であったことがわかります。
クエリB
/* 国×マーケットセグメントで集計して、会員の傾向を調べる */
SELECT remote.c_nationkey,remote.c_mktsegment,count(*) AS cnt
FROM from_dcr.tpch.customer AS remote
JOIN my_db.tpch.cutomer AS local
ON local.c_custkey = remote.c_custkey
GROUP BY remote.c_nationkey,remote.c_mktsegment
ORDER BY cnt DESC
;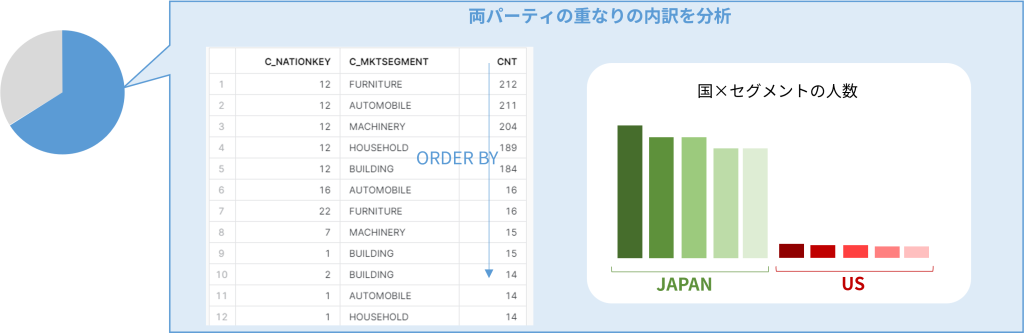
クエリBでは重なった2000人に対する内訳を分析しているSQLで、自社会員データ(会員番号と名前のみ)だけでは知りえなかった自社顧客の特性を理解することができました。
DCRへの期待を改めて考える
最後のSQLの結果を見ると、「自社の顧客の多くが日本人だった」という集団の傾向を得ることができました。プロバイダー企業にとっては、せっかく多数のデータをもっていても15万人は各国の人が均等に存在するデータであって、それを自社だけで「母数の多いレポートだよ」といって販売したとしても今回のような分析にはまったく役に立たず、相手のテーブルとJOINしたことで価値のある分析結果を提供することができました。
そしてこのSQLの結果から「自社顧客のうち誰が日本人か」をコンシューマ企業では知ることはできません。個人個人がどうかを知らずとも、全体として日本人がこんなにも多いのだから、「日本向けマーケティングを強化しよう」という次の施策を立てられるのです。
これこそがDCRに期待してきたプライバシーを守るパーティー間の分析であり、そのためにはアカウントをまたいだJOINのSQL実行が必須だったし、GROUP BYを強制して個人個人を隠した集団の傾向をつかむことを目的に据えました。
これで、一連のデータクリーンルーム構築の基礎は終了です。
え、じゃあ応用があるの?
DCR構築の難所である「RAPマッピングテーブルに許可済みクエリを登録する」をいかにクリアするか?そのための工夫がSnowflake公式であったり、開発中として発表されている機能だったり、サードパーティ製品だったりで提供されていて、より簡単にDCRに取り組めるようになっています。もう少しこのシリーズを続けて、各方式について考察などしていきたいと思います。










この記事へのコメントはありません。