こんにちは、喜田です。
本投稿は PostgreSQL Advent Calendar 2023 の13日目の記事です。
象さんと戯れる日々からデータ界隈に転生し、Snowflake や BigQueryと戯れて早一年が経とうとしています。同じデータベースのテクノロジーで、SQLが書けて、まぁDWH周りのタスクでは困らないかなというところはイメージを持っていたのですが、そんな中で業界のギャップを痛感したことが一つありました。それはSnowflakeの「データシェアリング」という考え方に触れたことです。
超簡単に言うと「企業・組織をまたいでデータを流通させ、自組織では持ちえなかったデータを使って知見を得る」という考え方です。パブリックデータなど公開されたデータセットを取り込んで使うという考えは業務DBの世界でもありましたが、企業間で自社の営業ノウハウ・技術ノウハウの塊ともいえるデータを他者に使わせるという視点がまずショックだったし、それを実現するためのアーキテクチャもまたクラウド・SaaSの時代ゆえにできることで、数年前まで(どころか自分にとってはつい昨日であっても)思いもよらなかったな、、、と衝撃を受けました。
Snowflakeのデータシェアリングとデータクリーンルーム
データシェアリング
簡単にSnowflakeのデータシェアリングについて触れておくと、SnowflakeはSaaS型のDWHであり、アーキテクチャ的には超巨大なマルチテナントです。利用者(社)は契約して自社のデータをSnowflakeにロードすると、そのファイルの実体はSnowflake社が管理するAWSやGCPやAzureのオブジェクトストレージ(S3とか)に配置されます。
マルチテナントのサービスでよくある、データは運営側でひとまとめに保管され、そうはいっても権限管理されてますから他社さんから見えることはありませんよ、と。この権限管理を特定テーブルのみ、特定の相手に向けてオープンにしてしまおうというのがデータシェアリングです。これもマルチテナントゆえ、Snowflake内での公開設定ひとつで自社のデータファイルをそのまま相手に見せることができてしまうのです。
生のデータファイルなので、常に最新だし、他所に連携するために一度ファイルにエクスポートしてデータ量が大きければ吐く時間、保管場所、転送方法、ロード方法・・・と悩みが尽きないことは皆さん想像つくと思いますが、そういうものを一切排除しています。そう、Snowflake同士ならね!
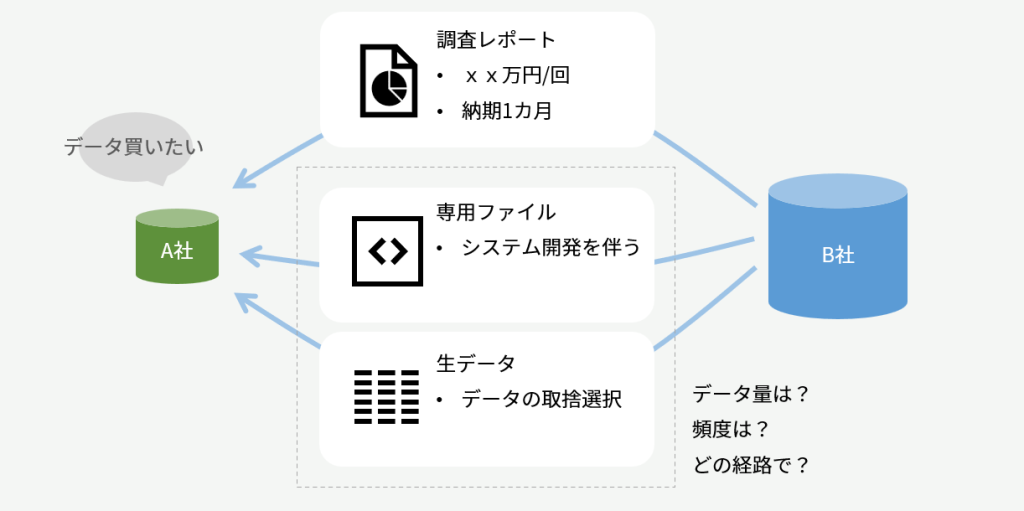
データクリーンルーム
データクリーンルームは製品によらない概念で、二つの組織がそれぞれデータを持っていて、プライバシーや機密情報を含んでいる場合に、お互い非公開とするデータは見せず、でも両者をJOINした結果を出力する「魔法の計算空間」のことを言います。
上述のデータシェアリングによって公開したテーブルは、通常は提供を受けた側が好きに検索したり、自社のテーブルとJOINして利用できますが、この時に公開テーブルに制限を設けることで自由な検索はさせない、あらかじめ許可した分析クエリだけ許す、という実装でデータクリーンルーム機能を実現しています。
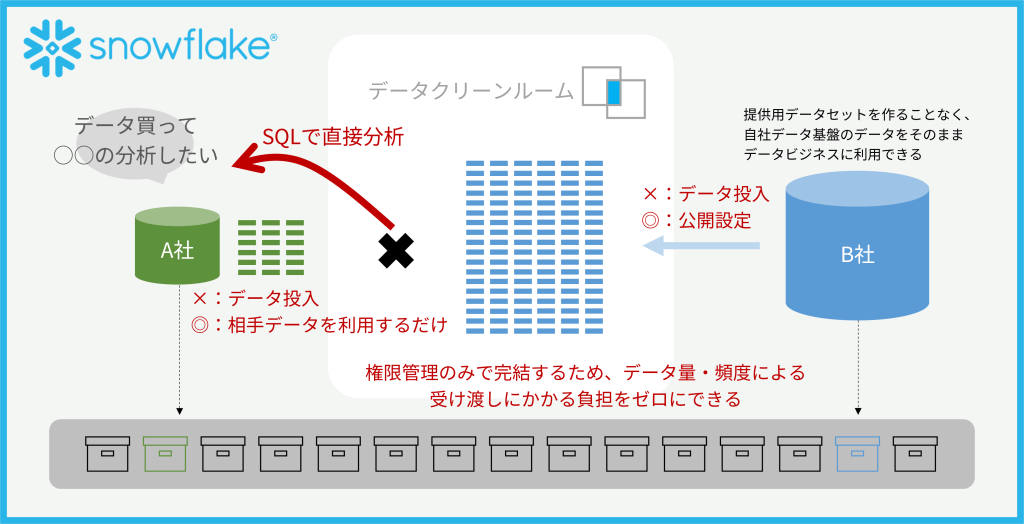
この図のように、マルチテナントゆえに裏側の物理ファイルは権限管理のみで相手に公開した状態、でも緑×青のデータはJOINを強制(OUTER JOINすると青の全行が見えちゃうけどそれは許さないとか)したり、集計した結果(GROUP BY してSUMをとるとか)しか出さないといった制限をかける機能です。
さて!
今日の本題は、そういう概念を知ってしまったからには、PostgreSQLでできることってあるだろうか?という「PostgreSQLでデータクリーンルーム」にトライしてみる好奇心に駆られて、時間を溶かしてしまった、というお話です。
PostgreSQLでクリーンルームのデザイン
外部データラッパによるシェアリングの可能性は?
PostgreSQLにはネットワーク越しの他のデータベースに対してリモートクエリを実行する外部データラッパ(Foreign Data Wrapper:FDW)が用意されています。
互いに権限設定、ネットワーク経路が確立されさえすれば、相手の組織が持っているデータを自分のデータベース内でみることができます。クエリした際に都度相手に聞きに行くビューのようなもので、データの実体が利用側に残るわけではありません。
ある意味、データシェアリングで実現されている「データの移動なく、リアルタイムな結果をとれる」は実現できていると言えます。
他社とネットワーク的につなぐというのは大変な事態だけど、RDS PostgreSQL同士とかならパブリックなエンドポイントがすでにあって、セキュリティグループ次第でワンチャンありかも。
CREATE EXTENSION postgres_fdw;
GRANT usage ON FOREIGN DATA WRAPPER postgres_fdw TO data_admin;
CREATE SERVER remote_server
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host 'db1-aaabbbccc.ap-southeast-2.rds.amazonaws.com', port '5432', dbname 'provider');
-- デフォルトでは名前解決できず、rds.custom_dns_resolution = 1にする必要があった。
CREATE USER MAPPING FOR data_admin
SERVER remote_server
OPTIONS (user 'data_consuemr', password 'password');
CREATE FOREIGN TABLE from_provider_users
(mail text,area text)
SERVER remote_server
OPTIONS (schema_name 'data_admin', table_name 'users_area');
データ利用側のこれだけの設定で相手DBに到達できるので、ネットワーク面で相手と話がつけば簡単にできてしまいます。AWSであればセキュリティグループの設定一つでパブリックアクセスさせられます。
データクリーンルームの可能性は?
シェアはするけど、実行させるクエリに制限をかけることで、相手に見せるものは狙った結果のみに絞るのがデータクリーンルームの要件です。具体的には、
| JOINを強制する | 両者がもつ共通のキーを使ったINNER JOINを強制。 OUTER JOINさせないことで全件の流出を防ぐ。 |
| GROUP BYを強制する | 共通のキーはメアドなど個人情報で、流出は許されないでしょう。 この列を結果として返さないような、行をサマリして返す集計値のみ 返すように制限をかける。 集計の結果、件数がn件以下もまた返さないように制限をかける。 |
| 特定列を返さない | 元テーブルはメアドのほかに氏名を持っているが、JOINのキーとして メアドを使うのであれば不要な氏名は参照させないようにする。 |
GROUP BY強制や列を絞るのは、セキュリティ目的のビューにありがちな観点です。ビューにするならJOINを含むビューだって良いわけで。じゃあ、なんかやってみたらできるんじゃない?と思っていた時期が私にもありました。。。
壁
冷静に考えれば上記の穴はすぐに見つかりました。
両者が互いの個人情報を相手に見せないのだから、FDWでテーブルをクエリさせる時点で制限がかかっていなければいけません。実際にSnowflakeのデータクリーンルームは、シェアするオブジェクトに対して行アクセスポリシーを仕掛け、「許可済みクエリでないと見せない」という制御を行ごとに行っています。受け取り側でクエリするときには、そのクエリが許可済みかどうか判定されるので、許可されていない行が相手に見えることはありません。
対してPostgreSQLのFDW案はここで限界を迎えます。
双方のデータをJOINするためには、どちらかのデータを他方に持ってきてJOINする必要があります。FDWではJOINのPush Downが効くのだから、許可済みJOINのSQLであることを示せれば、取得するデータはJOINした結果だけになるかなと思ってやってみたところ、FDWで相手に伝わるクエリはJOINの構文が分解されて、PL/SQLの無名ブロック的なものに置き換わっていました。
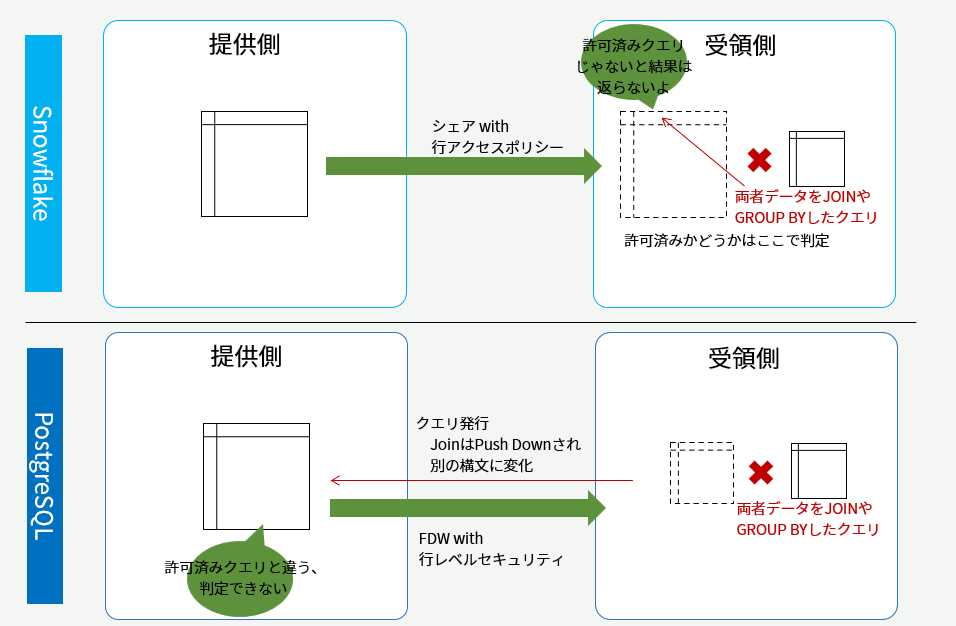
許可済みJOIN構文であることを示すために、Snowflakeの方法をヒントに、PostgreSQLの行レベルセキュリティで、current_query()が事前定義したものと一致するか?を評価することも考えましたが、このPush Downの仕様により断念。
2023-12-13 08:59:21 (12870):data_consumer@provider:[513]:LOG: statement: START TRANSACTION ISOLATION LEVEL REPEATABLE READ
2023-12-13 08:59:21 (12870):data_consumer@provider:[513]:LOG: execute <unnamed>: DECLARE c1 CURSOR FOR
SELECT mail, area, flag FROM data_admin.customer
2023-12-13 08:59:21 (12870):data_consumer@provider:[513]:LOG: statement: FETCH 100 FROM c1
2023-12-13 08:59:21 (12870):data_consumer@provider:[513]:LOG: statement: CLOSE c1
2023-12-13 08:59:21 (12870):data_consumer@provider:[513]:LOG: statement: COMMIT TRANSACTION
↑ リモートサーバで実行されたSQLをログ出力したもの。発行したクエリは data_admin.customer と自ノードのテーブルをJOINするシンプルなクエリでしたが、JOINのPush Downのために単一の表に対するSELECTの形にばらされ、さらに無名ブロックとして該当行かどうか判定しながら取得するという動きになっています。
制限つきパーティ間集計の実装
一方、プライバシー保護の観点では、実はシステム的な課題の部分と法的な課題の部分があります。ここまでの話はシステム的な部分で、プライバシー部分は絶対に流出させない!ためのやり方を考えました。
法的な課題とは、個人情報保護法などによって定められたプライバシー情報の取得時に利用範囲を明示し、同意を消費者から得ている必要があるということです。逆に同意を得ていれば目的に沿った使い方はOKになります。
一般に、データ提供者側、100万件のメールアドレスを握っている側が「ウチのデータ外部公開することにしたから、同意ヨロ!」といっても、ユーザ感情的にも100万人の同意を揃えて得ることはかなり大変です。
反対に、データ利用側、何らかの商品販売や、サービスを提供している企業だとして、その利用者(=ファン)に対してより良いサービスを提供するための外部機関を使った分析を目的としていれば、外部機関にデータ提供もやむなしと同意してくれる可能性は高いでしょう。
多段かつリモートのビューを使って集計値のみを返す
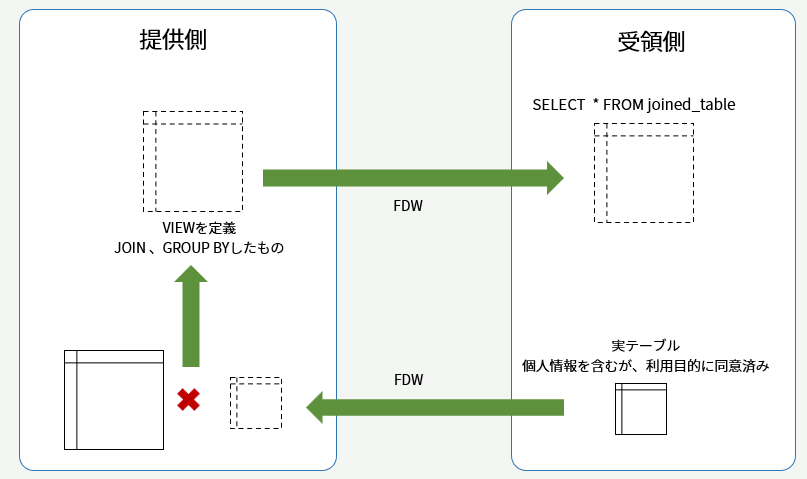
外部データラッパは、相手データベース内にあるテーブル、ビュー、マテリアライズドビューを問わず、SELECTしたその時点の結果を取得してきます。つまりこれ自体が毎回リモートに聞きに行くビューのような性質を持っています。
いままでそんなシーンに巡り合わなかったので検証もしたことがなかったのですが、実はこれを多段に作れます。
動きとしては、受領側では以下のクエリを叩くだけで、
SELECT * FROM joined_table;
内部的には、joined_tableはFDWを経由して提供側で定義した両者のテーブルをJOINするビューに対するクエリになります。これはJOIN済みだしGROUP BYした結果だし、不要な列はすでに絞っておくといった対応を提供側でできます。ビュー定義のイメージは以下のようなもです。
CREATE VIEW joined_view AS (
SELECT area,flag,market,count(*)
FROM local.cusotmer AS local
JOIN remote.customer AS remote ON local.mail = remote.mail
);
結果として、関東在住、商品購入フラグつき、マーケ属性Aという人が10人いるよ、みたいなことが取れます。
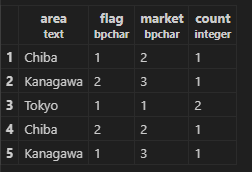
ここで、JOINするもとになったlocal.customerには100万人のメアドと居住地、remote.customerは提供側データベースに定義したFDWで取得しており、1万人分のメアドと商品購入実績ありフラグや、マーケ属性分け(例えば年収xx以上でプライマルな商品でも手に取ってくれる人はAランク)みたいなものが格納されています。これは利用側が顧客同意を得たうえで一時的に提供側データベースで見られることをヨシとしたデータということになります。
このテーブルに対する権限設定として、リモートクエリ実行用ユーザにしかSELECTさせない、かつ、リモートクエリ実行用ユーザは特定のIPアドレスからしかDB接続できない、といったことをGRANT/REVOKEやpg_hba.confで絞ることで、提供側企業の1メンバーがさらっと見れてしまう可能性は激減し、まあまあ実用の可能性はなくはないかもしれない。なくなくなくなくない????(わからん)
superuserになれる人からは一発で見られてしまうので、その点は監査ログとってますよ~を周知することで予防しましょう。
最後に
PostgreSQLのエントリのフリをしてSnowflakeのことをたくさん書いてしまいましたが、データクリーンルームは8月のGoogle Cloud Next、11月のAWS re:Invent でもそれぞれ新機能として発表されており、まさにこのデータ流通の世界を実現する核となる注目技術です。
PostgreSQL界隈でもこのような概念を知っていただき、ふとどこかで組織間のデータ連携といった話になった際は、ここまではFDWで、ここから先は別製品で、といった勘所を持っていただければと思います。