
こんにちは、喜田です。
この記事では、複雑なSnowflakeのデータクリーンルーム(Data Clean Room:DCR)をしっかり理解することを目指して、極力親切に、DCRに期待される機能や構築に必要なパーツを紐解いて解説していきます。
前回の記事ではDCRの実装の肝となる行アクセスポリシー(RAP)の作り方を詳しく解説しました。
前回作成したRAPでは一つのSnowflakeアカウント内で、ロールやユーザー別に、あるテーブルに対して権限者は全行見えるが、イチ開発者は絞られた行しか見えない、特定部門のメンバーは自部門の行しか見えない、といったテーブルの振る舞いを制御しました。
DCRではこの仕組みを応用して
- 許可したアカウントにしか見せない
- 許可したクエリでしか見せない
を実現します。
SnowflakeがSQL実行時に内部でもっているコンテキストより「アカウント情報:current_account()」や「実行中のクエリそのもの:current_statement()」を用いて、手作りDCRのために必要な要素を検証していきましょう。
データシェアリング×行アクセスポリシー
すでに予告していますが、RAPを使うことでSQLを実行している「アカウント」別に結果を出し分けることを考えます。あるテーブルが複数アカウントから参照されているということですので、これはデータシェアリングによって他アカウントに対してデータを提供しているケースに他なりません。
シェアを作成する
シェアそのものは手順レベルで多くのノウハウがありそうですので、構築手順の詳細な解説は省きますが、上記のようにデータ提供側で「シェア」を定義します。GRANT文でシェア対象オブジェクトをシェアに含めたら、相手アカウントに対する公開設定を行います。
データ受領側は、受領のための「仮データベース」を作成するだけですぐ提供側の最新のデータをそのまま参照できます。
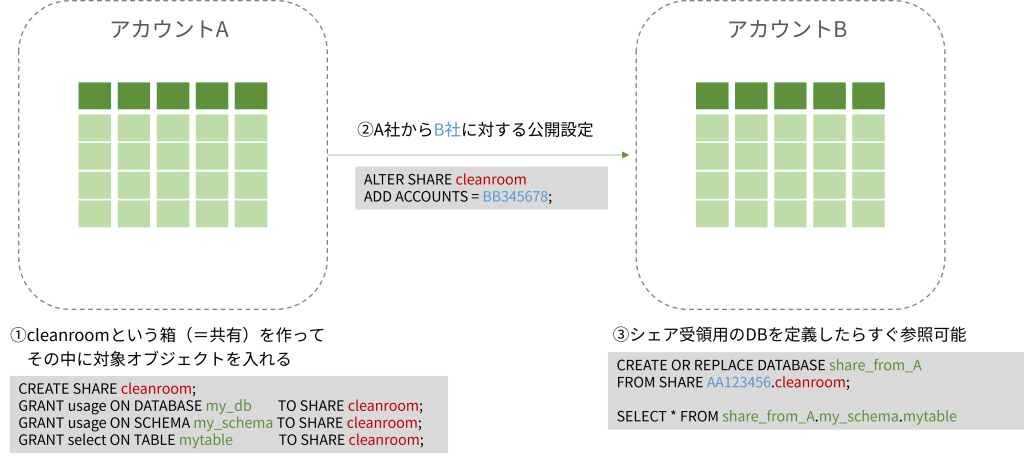
シェア作成時に、ALTER SHARE ... ADD ACOUNTS = account_name しているので、この時点で許可済みアカウントでしか参照できないセキュアな方法ではあるのですが、今回扱うRAPを組み合わせる方法では、相手アカウントによってさらに行を出し分けるということをやります。
アカウント別に結果を制御するRAPの定義
やることは簡単で、前回作成したサンプルで、許可済みユーザーリストをチェックしてデータの出し分けをしたように、RAPの定義内で許可済みアカウントリストにヒットするかどうかをチェックします。
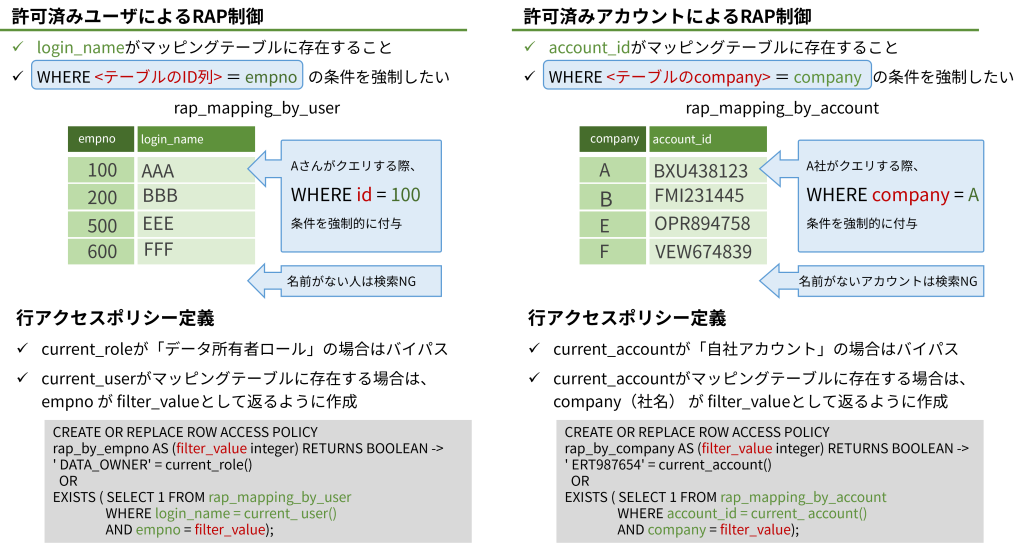
このポリシーを作成し、ローカルの時と全く同じようにシェア対象テーブルにアタッチします。シェアを受領した相手がデータを閲覧するする際に自動的にポリシーが適用され、filter_valueを対象とするWHERE句が強制的にかかることになります。
GROUP BYを強制する
ここまで実装しても、受領側のアカウントでSELECT * FROM mytable; のようにすればWHERE条件はかかるにせよテーブル内の全列を自由にとれてしまい、個人情報を含むテーブルでは個人に紐づく属性がまるわかりになってしまい良くありません。
相手に見せる列を絞る方法
元テーブルに含まれる個人情報列(例えばmail_address列)を公開しないためには、
- Projection(射影、SELECT句に書く列リストのこと)を最低限に絞る
- Aggregation(集約、GROUP BY句による集計)の結果のみを返す(同時に他の列は列リストからも外れる)
- そもそも外部公開するテーブルに個人情報列を含まないVIEWにする
- ダイナミックマスキング機能で個人情報列を難読化する
などがありそうですが、3点目のVIEW、4点目のマスキングについては2つのパーティが所有する会員リストをmail_address同士でJOINするといったことがDCRの主な期待なので、これらの案は除外します。
現状、Snowflakeの機能でSELECTリストの限定やGROUP BY句の使用を強制する機能はありませんので、ここを強制する方法として、実行中のクエリそのものをコンテキストとして扱えるcurrent_statement()を用いたRAPで解決することになります。
RAPでクエリ全文を強制する
かなり図の書き込みが多くなってきましたが、考え方はここまでテストしてきたRAPと全く同じなので、ゆっくりじっくり見てください。(前回や上記の例とテーブル名・列名など変わっていますので、この図はあくまで参考に、そのまま実行しても上手く動きません。。。)
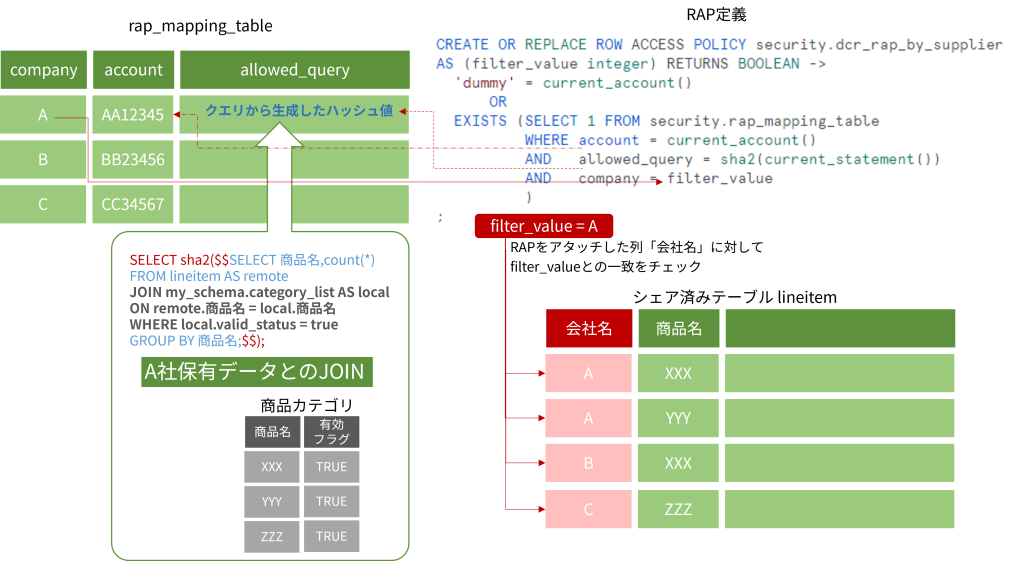
rap_mapping_table
まずはマッピングテーブルに注目ください。
rap_mapping_tableにallowed_query列を追加しました。ここにはDCR越しに相手企業が検索するSQL文を登録しておきます。単純にクエリテキストそのものでもよいのですが、長くなるのでハッシュ化して格納しています。
sha2関数
SQL文を登録するにあたり、sha2関数を使ってクエリテキストをハッシュ化しています。sha2関数はマッピングテーブルにallowed_queryを登録するときと、RAP定義内で実行中クエリをその場でチェックする際に使っています。
Snowflakeでは$$で囲った文字列は、シングルクォーテーションで囲うのと同様の文字列としての扱いになり、エスケープなどを考慮しなくて済む場合が多いのでこのようにしました。
RAP定義
EXISTS句の中にallowed_query行を追加しています。
ここでcurrent_statement()との一致をチェックを行い、「許可済みアカウント」かつ「許可済みクエリ」によってのみこのテーブルに対する検索ができるように作っています。
filter_valueに「A」が入るので、シェアを参照する際に WEHRE 会社名=A がつく(普通のRAPの用法で、相手によって結果を出しわける)ようにしました。
商品カテゴリテーブル(検索実行アカウント側)
検索クエリはallowed_queryに登録したものに限定されますが、逆に言うと登録さえしてしまえば、ここでのSQL機能に制限はありません。
検索実行アカウント側のテーブル(my_schema.category)とのJOINやGROUP BYを含めることができ、そのような作りにしました。自由なクエリに対して許可したうえでそのまま実行させる、他のことをさせないことこそがSnowflake DCRの本質といえます。
もうすこし考察
DCRのための最低限のRAP条件
実はRAPの説明のためにここまでずっと「強制的にWEHRE条件をつける」という話をしてきましたが、DCRの本質を考えると、実行クエリを許可したもののみに限定できれば良いのであって、アカウント別に見せる行を都度変える必要性はありません。
この場合は、関数のインプットとしてfilter_valueは残しますが、条件のほうで使うことはありません。
CREATE OR REPLACE ROW ACCESS POLICY security.dcr_rap_by_supplier
AS (filter_value integer) RETURNS BOOLEAN ->
'dummy' = current_account()
OR
EXISTS (SELECT 1 FROM security.rap_mapping_table
WHERE account = current_account()
AND allowed_query = sha2(current_statement())
-- AND company = filter_value -- この行は条件から除外
)
;一方、このポリシーをテーブルに適用するにはどこかの行を指定しなければなりません。
ALTER TABLE lineitem ADD ROW ACCESS POLICY security.dcr_rap_by_supplier
-- ON ('会社名') -- filter_value = 会社名 条件が不要な場合はどの列でも良い
ON ('商品名')
; 「filter_value」が「company」にマッチする行を探す必要がなくなりましたので、ここではテーブルのいずれかの列を指定すれば正しく動作します。
マルチな相手にマルチなクエリを実行させる
100社に対して100種のクエリパターンを許可する、みたいな極端な例を想像します。(DCRがデータ流通の新しい形になって、このぐらいみんなが使ってる!なんていう世界を目指したいですね。)
実際に性能問題を経験したわけではありませんが、RAP関数は対象テーブルの各行に対して1回実行されそうです。(何らかの内部実装で効率化されている可能性はありますが)
この1実行あたりの負担が大きくなると、巨大なテーブルを検索した時の負荷は相当なものになることが予想されます。1万行のマッピングテーブルを、10億行のDCRテーブルの各行に対して繰り返し舐めるわけですね。Snowflakeはたった数行を取り出す簡単な検索であったとしてもインデックスを持たないアーキテクチャゆえデータを多めに触る必要があり、こういう繰り返し検索の性能面では不得手なのではないかと予想しています。
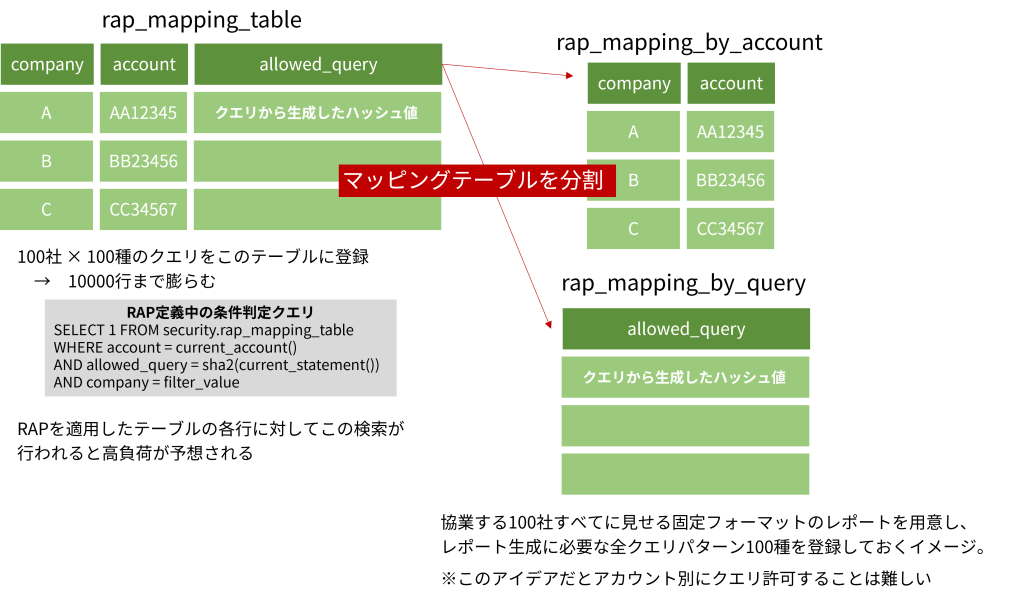
マッピングテーブルの定義が変わったので、RAP関数のほうを見直します。
CREATE OR REPLACE ROW ACCESS POLICY security.dcr_rap_by_account_and_query
AS (filter_value integer) RETURNS BOOLEAN ->
'dummy' = current_account()
OR
(EXISTS (SELECT 1 FROM security.rap_mapping_by_account
WHERE account_id = current_account()
)
AND
EXISTS (SELECT 1 FROM security.rap_mapping_by_query
WHERE query = sha2(current_statement())
)
)
;ネストが増えてちょっと読みづらいですが、(EXISTS 許可済みアカウント AND EXISTS 許可済みクエリ)
という条件になりますので、「許可済みアカウント」かつ「許可済みクエリ」をアカウント×クエリの組み合わせが膨大に増えたとしても低コストで評価できるように書けます。
RAP作成者の権限について
Snowflakeの行アクセスポリシーの解説を見ると、権限について細かく記載があります。
RAP本来の機能である検索ユーザの権限に基づいて行の出しわけをすると考えると、自社データ基盤内でいろいろなチームに属する人がそれぞれ必要なデータを見るケースが考えられ、そこではテーブルのオーナーも様々、見る人の権限種別も様々になります。こういった状況にもれなく対応しなければならないのが、RAPを本格的に使うユースケースといえます。
特権的にそれぞれのオーナーからテーブルにアクセスする権限をもらう必要があるでしょうか?その特権ユーザはあらゆるチームのデータを見れてしまうでしょうか。答えはNOで、他チームのデータは見れないけどポリシー適用については強い権限を持ち、各チームのテーブルのオーナーに渡してあげるという対応が推奨されてます。
データクリーンルームの場合、自社内の様々なチームをまたいだ、様々な検索の要件に応えるのと違って複雑な権限管理は不要と考えます。DCRで相手企業に提供するデータについては他チームをまたぐようなものではなく提供用データとして目的に応じて整えておくべきで、それであれば公開用テーブルのオーナー自身がRAP定義やマッピングテーブルを用意すれば十分です。
まとめ
第三回では、データクリーンルーム実現のために必須となる「許可済みクエリの実行のみ許すRAP」を作成し、その他さまざまなDCR観点での利用方法を考察しました。
もうここまでの知識でDCR機能は実現できるのですが、かなり寄り道してしまいましたので、一本道で作れる手順になっていないですね。次回はここまでのサンプルは一旦置いておいて、手作りDCR環境を通しで作成する!としたいと思います。










この記事へのコメントはありません。