Snowflake Summit 2025 参加レポート【Day2】

こんにちは、エクスチュアの黒岩です。
昨日投稿したSnowflake Summit Day1の投稿に続き、本日はDay2のレポートを書いていこうと思います!
Day1のレポートはこちら↓
Day1の記事ではイベント全体の様子を中心にお届けしましたが、今回は少し趣向を変えて、私が実際に参加したハンズオンセッション私が実際に参加したハンズオンセッション「Build a Real-Time Streaming Generative AI Application with AWS and Snowflake」についてご紹介していきたいと思います💪
このセッションではAmazon Bedrockと連携し、Snowflake内に取り込まれた映画レビューに対して、タイトル情報をもとにCortex AIがあらすじ要約やOscarノミネート判定を自動生成する処理が実装されていました。ユーザーがSQLを通じてLLMの出力を制御する形で、生成AIをデータ強化に活用する構成となっています。
セッション概要

| 項目 | 内容 |
| タイトル | Build a Real-Time Streaming Generative AI Application with AWS and Snowflake |
| 登壇者 | James Sun(Sr. Partner Solution Engineer, Snowflake) Nithyashree Alwarsamy(Principal Solutions Architect, AWS) |
| セッション説明 | Organizations have various streaming use cases where they need to ingest unstructured data — such as customer reviews or social media comments in text or JSON format — into a lakehouse. Before storing this data in database tables, they often want to process it in real time using generative AI capabilities, such as fraud analysis, sentiment analysis and summarization. This hands-on lab provides step-by-step guidance on building an end-to-end data pipeline using Amazon Bedrock, Amazon Managed Service for Apache Flink, Amazon Data Firehose and Snowflake. |
アジェンダ

使用する主な技術スタック
以下のアーキテクチャで構成される状態を目指すイメージで進めていきます、という流れで始まりました。(※今回のハンズオンで全て使用しているわけではありません)
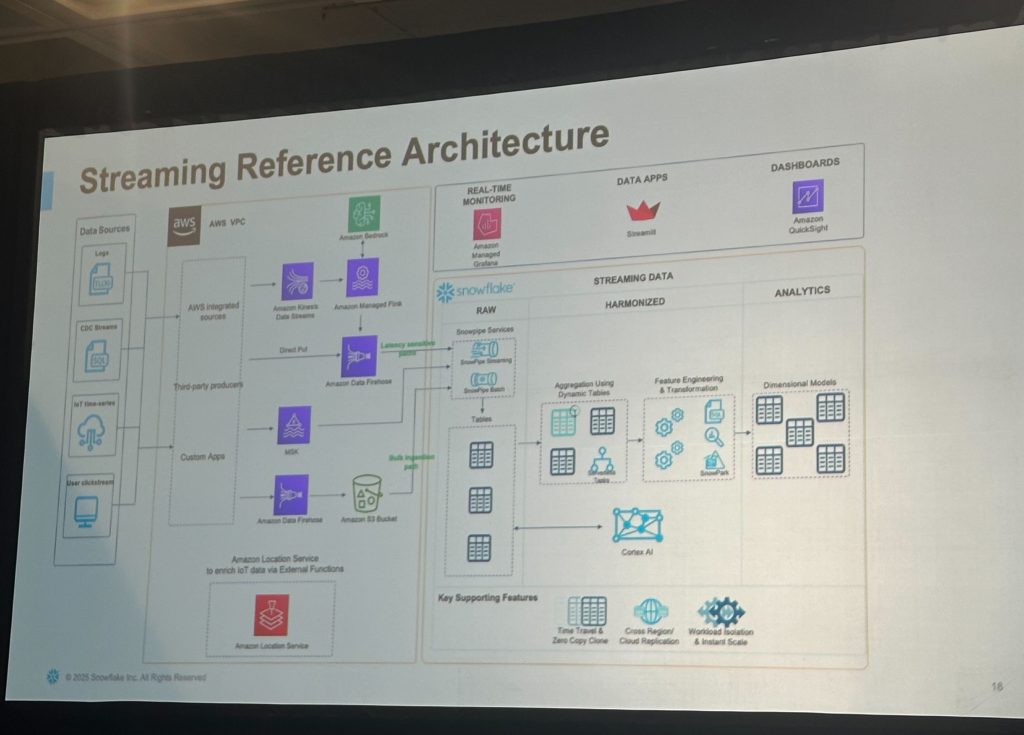
Amazon Data Firehose
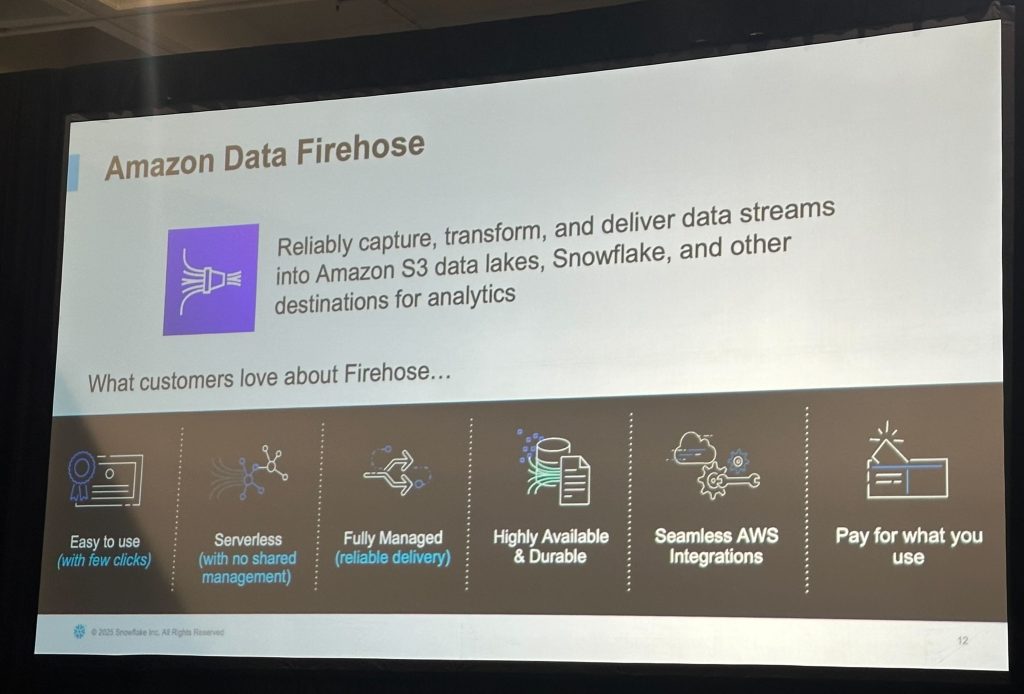
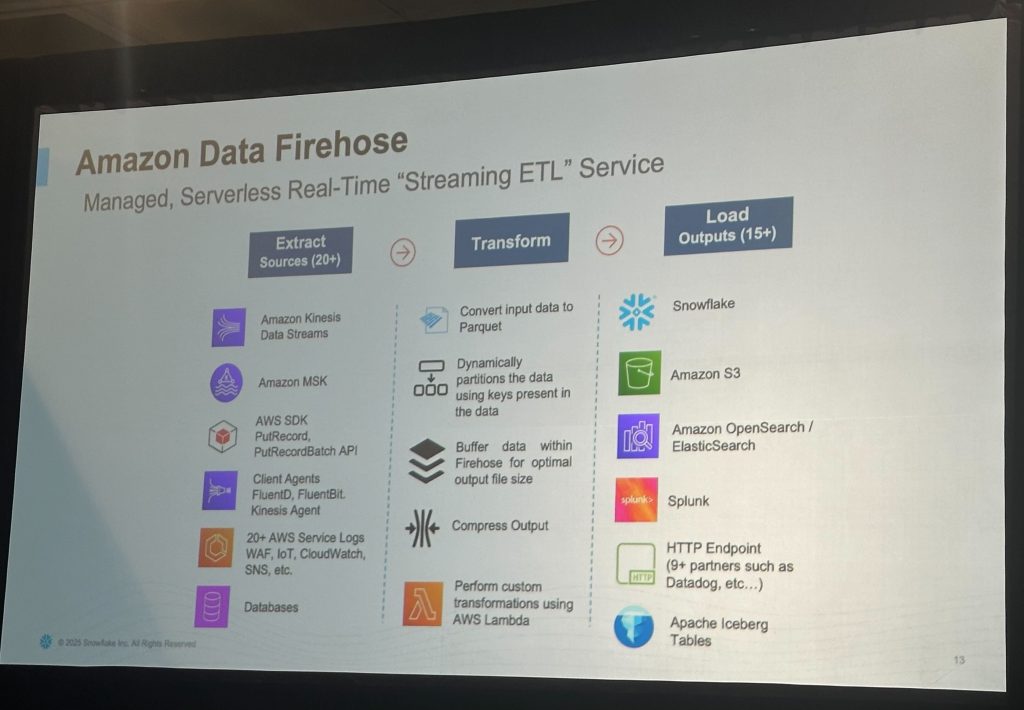
Firehoseは、Amazonが提供するストリーミングデータの収集・変換・配信サービスで、SnowflakeやAmazon S3など、さまざまなデータレイク/分析基盤に直接データを届けることができます。
このセッションでは、生成AIアプリケーションに必要なストリーミングデータ(例:レビューやSNSコメント)を処理基盤へ送り届ける役割を担っていました。
Snowpipe Streaming
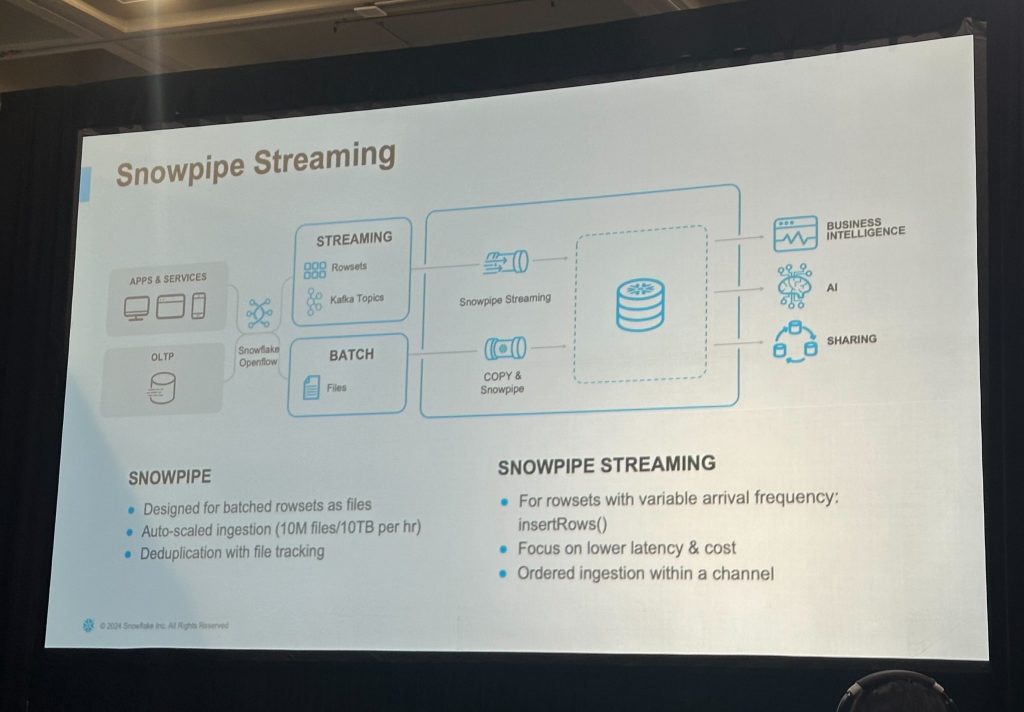
Snowpipe Streamingは、Snowflakeが提供するリアルタイムのデータ取り込み機能で、Kafkaなどのストリーミングソースから到着頻度の異なるrowset(行セット)をinsertRows() APIを通じて即時にテーブルへ反映させることができます。
このハンズオンでは、Amazon Data Firehoseから出力されたデータを、Snowflakeに高速かつ順序保証付きで取り込むために、Snowpipe Streamingが活用されていました。
Snowflake Cortex AI

Cortex AIは、Snowflakeが提供する生成AI統合フレームワークで、Snowflake上のデータに対してAIエージェントや大規模言語モデル(LLM)を組み合わせた高度な処理・検索・自動化を実現するための基盤です。
このセッションでは、Bedrockと組み合わせて、ユーザーからの自然言語的な問い合わせに対して要約・感情分析・意思決定補助を行うAIアプリケーションの一部として、Cortex AIが実装されていました。
Amazon Bedrock


Amazon Bedrockは、生成AIアプリケーションの構築・デプロイ・スケーリングに必要なすべてを提供するフルマネージドサービスです。OpenAIのような単一モデル提供ではなく、複数ベンダーによる多様なモデルを統一APIで扱える点が大きな特徴です。
このハンズオンでは、Bedrockを通じてレビューやSNSコメントに対して「要約」「感情分析」などを即時に行う処理を組み込み、Snowflake側へリアルタイムで取り込む一連の流れを体験しました。
作業手順
今回のハンズオンは1.5時間のセッションであり、操作手順自体は細かく分岐もありました。そのため本記事では、主要なステップと要点のみを抜粋し、どんな流れで構築を行ったかの概要を紹介します。
①Firehose送信用のEC2インスタンスを作成・接続する
このステップでは、後続のハンズオンで Amazon Data Firehose にデータを送信する役割を担う仮想サーバ(EC2インスタンス)を作成し、接続できる状態にしました。
事前に用意された CloudFormation テンプレートを実行し、EC2インスタンスや関連リソースを自動作成。作成された EC2 に対し、セッションマネージャを使って簡易的に接続という流れで進みました。
このインスタンスは、後のステップでPythonスクリプトを使ってデータをFirehoseへストリーミングする際の実行環境として使用しました。

②Snowflakeへの接続準備(認証設定)
このステップでは、FirehoseがSnowflakeへセキュアにデータを送信できるよう、以下の作業を行いました。
実施内容(概要):
- EC2上でSnowflake認証用の鍵ペア(公開鍵・秘密鍵)を生成
- 生成した認証情報をAWS Secrets Managerに登録
- 公開鍵をSnowflakeユーザーに関連付け
- 後工程で使用するためにAmazon Bedrockのモデルアクセスも有効化
これにより、FirehoseとSnowflake間で安全な鍵ベース認証による接続ができる状態になります。
③生成AIアプリケーションのデプロイ
このステップでは、Firehose経由で流れてくるデータを処理し、生成AIと連携してSnowflakeに保存するストリーミングアプリケーションのデプロイを可能にするため、以下の作業を行いました。
実施内容(概要):
- Snowflake接続設定ファイル(cdk.context.json)を作成
Secrets Managerで登録した情報やアカウントURLなどを指定 - Apache Flinkアプリケーションをビルド
JavaコードをMavenでビルドして.jarファイルを生成 - AWS CDKでインフラを一括デプロイ
CDKを使って、以下のリソース群を一括構築- Kinesis Data Stream
- Firehose
- Flinkアプリ
- 必要なIAMやネットワーク構成
cdk bootstrap
cdk deploy

このステップの完了により、ストリーミングされたデータがAmazon Bedrockを通じて生成AIで処理され、Snowflakeに取り込まれるパイプラインが動き始める基盤が整いました。すべてコードベースで管理できる点が、運用面でも非常に魅力的です。
④データのストリーミングと変換処理の実行
このステップでは、準備したパイプラインに実際のデータを流し込み、Snowflake上での変換処理を確認するため以下の作業を行いました。
実施内容(概要):
- EC2上にある映画レビューのデータセットを確認し、PythonスクリプトにてKinesisストリームへ送信開始
- 送られたデータが Snowflake に連携されていることを確認
- 補足データ(映画の詳細情報)をCSVでSnowflakeにアップロード
- レビューと映画情報を結合する Dynamic Table(動的テーブル) を作成し、1分ごとに自動更新される仕組みを体験
-- Example SQL query for Dynamic Tables
CREATE or replace DYNAMIC TABLE movie_review_dt
TARGET_LAG = '1 min'
WAREHOUSE = DEFAULT_WH
REFRESH_MODE = auto
INITIALIZE = on_create
AS (
SELECT *
FROM reviews m
LEFT JOIN movie_info_tbl f
ON m.movietitle = f.title
);
SELECT * FROM movie_review_dt;
これにより、リアルタイムにデータが取り込まれ、Snowflake上でAIによる要約・感情分析が行われ、さらにマスターデータと結合されていく流れが一通り動作する様子を確認できました。生成AI×ストリーム×データ基盤の融合を実感できる工程でした。
⑤Cortex AIでレビュー情報を自動拡張する
最後のステップでは、Snowflakeが提供する生成AI機能 Cortex AI を使って、映画レビューのデータをさらにリッチに拡張するために以下の作業を行いました。
実施内容(概要):
- Dynamic Tableで作成されたレビュー情報に、新たに「あらすじ(storyline)」と「アカデミー賞ノミネート情報(oscar_nominated)」の列を追加
- それぞれの映画タイトルに対して、Claude 3 Sonnetモデルを使って自動で内容を生成
- AIの補完によって、元の数値データやテキストだけでは得られないインサイト(文脈、評価、受賞歴など)を補強
UPDATE review_ai_enriched_tbl AS tgt
SET
storyline = SNOWFLAKE.CORTEX.COMPLETE(
'claude-3-5-sonnet',
'give me a one paragraph storyline for the movie "' || tgt.title || '"'
),
oscar_nominated = SNOWFLAKE.CORTEX.COMPLETE(
'claude-3-5-sonnet',
'Was this movie "' || tgt.title || '" Oscar nominated?'
)
FROM (
SELECT *
FROM (
SELECT *
FROM review_ai_enriched_tbl
WHERE storyline IS NULL
)
SAMPLE (5 ROWS)
) AS src
WHERE tgt.title = src.title;

このステップにより、リアルタイムで蓄積されるデータに対し、AIが意味を加える形でのデータ強化が実現され、分析やレコメンデーションにも応用可能な形へと進化しました。
おわりに
今回のハンズオンではSnowflakeとAWSを組み合わせることで、生成AIを組み込んだリアルタイムなデータパイプラインをどのように構築できるのかを一通り体験することができました。単にデータを流すだけでなく、その途中で変換処理やAIによる意味づけを挟みながら、Snowflakeに蓄積・活用していく一連の流れを手を動かして確認できたことは非常に有意義でした。
特に印象に残ったのは、SnowflakeのDynamic TableやCortex AIといった機能の手軽さと実用性です。Dynamic Tableを使えばSQLだけで定期的に更新される変換ロジックを構築でき、従来のETLツールのような煩雑なスケジューリングや運用設計を省略できます。また、Cortex AIでは生成AIをSQLから直接呼び出してレビューの要約や映画の受賞判定といった“意味のあるデータ”を生成することができ、単なるストレージやDWHの枠を超えたデータ活用の可能性を感じました。
生成AIの活用においては「どう使えば業務価値に直結するのか」が重要ですが、今回のハンズオンはまさにそのヒントを実感として得ることができる体験でした。SnowflakeやAWSの環境がすでにある方、あるいはこれからデータ活用に取り組もうとしている方にとっても、非常に学びの多い内容だと感じます。明日以降も、気になるハンズオンがあれば積極的に参加して知見を集めていきましょう!




