SnowflakeのData Clean Roomを基礎から一番詳しく解説(1回目)

こんにちは、喜田です。
この記事では、複雑なSnowflakeのデータクリーンルーム(Data Clean Room:DCR)をしっかり理解することを目指して、極力親切に、DCRに期待される機能や構築に必要なパーツを紐解いて解説していきます。
ボリュームが大きくなりそうなので全数回にわけて、誰でも理解できる、検証できる形で順を追って扱います。
本質的な機能や動作原理の理解を本記事のゴールとし、
✓ これからSnowflake DCRに取り組む方は始めの一歩として
✓ Quickstartに沿って構築はできたけど本質的な理解を深めたい方
にオススメです。
Snowflake社のQuickStartで扱うようなそのまま使える便利なスクリプトや実践的なところは扱いません。硬派に一個一個手作りしてみましょう!笑
2回目以降の記事も公開中です。(順次更新します)
各回だけでも完結する+全体通してご覧いただくともっと理解できると思いますので、興味のあるところからご覧ください。
Vol1. DCRに求められる機能とは(本記事)
Vol2. 行アクセスポリシーのサンプルを作って仕組みを理解する
Vol3. DCRに絶対必要な「許可済みクエリのみ」実行させる機能
Vol4. いよいよ手作りDCRを作る!
Vol5. Snowflake公式のDCR Ver5.5とVer.6(仮)について
DCRに求められる機能
そもそもデータクリーンルームとは
データの新たな価値創出、つまり、データそのものに値付けし売買するビジネスや、データ相互利用による企業間コラボレーションの推進が注目されています。それを非テック企業同士でやる、これまで独自に長年蓄積してきたノウハウはその領域におけるお宝に育ち、そうしたデータが流通することで社会をよりよく変える力があると考えています。データクリーンルームはこのようなデータの流通のため、プライバシーに配慮しながら活用しやすい形でデータを扱う新たな方法・機能の一つの形です。
クリーンルームは日本語に訳すと「無菌室」であり、外部と隔絶された部屋でウイルスの研究をしている…あと謎に白い空間……私にとっては医療ミステリーやSF映画のイメージです。笑
外部と隔絶された環境で互いのデータを突合する、入室するには決められた手続きを踏んで、許可された操作だけを実行できる「データのクリーンルーム」といったところですね。それにはどんな機能が必要でしょうか。
DCRに求められる機能
2つのパーティ間(会社間)で互いにデータを持ち寄ってSQLでJOINして分析することを考えます。
・大型ショッピングモールへの出店を考えているA社
・出店先の候補である大型ショッピングモールB社
というストーリーで考えましょう。
A社にとってはモールの来場者を取り込め、またモール側で把握している顧客属性(性別・年代など)を使って店舗運営の参考にしたり、B社にとっても新店舗の開店に合わせたキャンペーンなどで新たな人を呼び込むといった双方のメリットがありそうですが、両者がもっている既存会員リストの重なりが重要です。
例えばモールの会員10万人は「20代女性が多い」が、他の年代・性別も満遍なく存在します。
A社の会員リストは1万人ですが、男女比・年代といった分類ができていないとします。
A社の1万をB社の10万のリストにあてたとき、4500人の重なりがありその内訳のほとんどが「30代男女」でした。
A社は会員の2人に1人はモール利用経験があることを知り、モールへの出店は親和性が高いと考えます。10万人中にまだまだ存在するであろう「30代男女」はそのままA社の見込み客です。B社はモールに入っている他店舗も巻き込んだ30代男女向けのキャンペーンを実施し新たな客層を得ることに成功します。
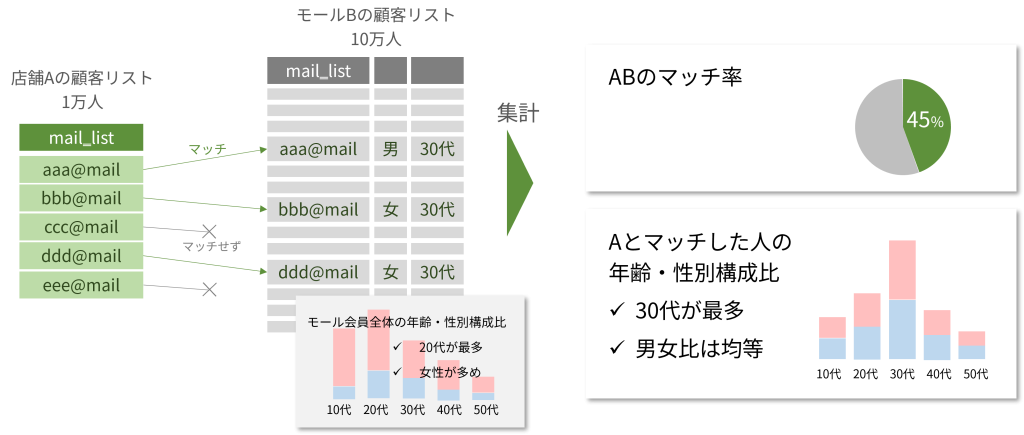
単にモール側の客層を集計したレポートでは「20代女性に強い」ということしかわからず、そもそもA社は出店を見送っていたかもしれません。モール側がもっていた顧客属性を使って、A社の顧客リストの解像度を高めたことで実現したデータドリブンな施策と言えます。
この分析を行ううえでのシステム的なポイントはどこにあるでしょうか。
両者のデータが同じデータベース内にあれば、2つのテーブルを結合(JOIN)して集計(GROUP BY)することで右図のような集計レポートを作成できます。問題はデータの受け渡しの部分です。
「2社以外の外部にデータが漏れないように」という要件であれば、モール側が用意したセキュアなドライブ(ファイル置き場)にA社のアクセス権を与え、A社顧客リストをアップロードしてもらえればよいような気もしますが、通常これではプライバシーへの対応が不十分です。
A社は自社の持つデータを預ける立場、B社は相手のデータを預かる立場で、B社がSQLで分析する際は預かったデータが丸見えになってしまいます。
「外部には漏れない、さらに互いのデータが相手にも見えないように」が満たすべき要件であり、
かつ「両データを突合して集計した結果レポートは欲しい」なのです。相手のデータは見えないけどJOINした結果には反映してほしい。
なんじゃそりゃ?という感じですが、それを実現するのがDCRです。
SnowflakeによるDCRの実現方式
データシェアリングがDCRの核
Snowflakeは独自のデータシェアリング機能を持っています。指定したテーブルやテーブル群をまとめて
「許可した相手に見せる」ことができる機能です。
無関係の他社には当然漏れない、データ受け渡しのためのパイプライン構築の工数をゼロにできるといった利点があります。外部に漏れないデータ受け渡しだけを実現するならデータシェアリングがそのまま使えます。
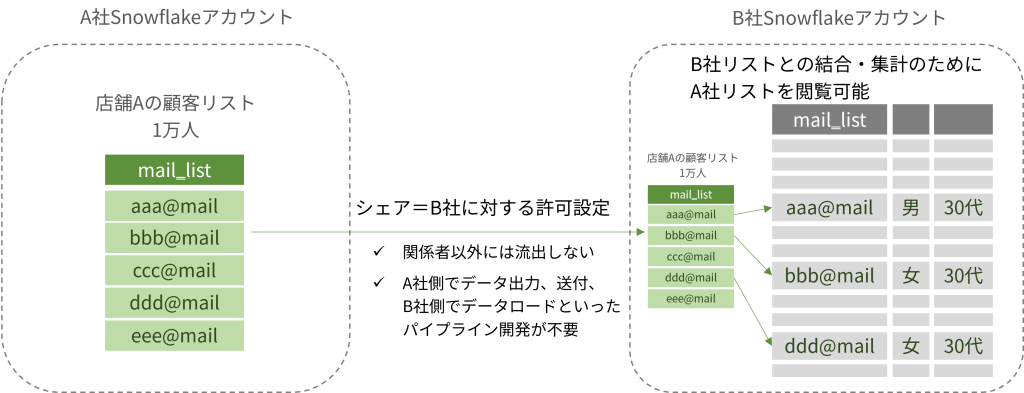
しかし、このままではシェアしたテーブルを丸ごと相手が使えてしまいますので、「互いのデータが相手にも見えないように、両データを突合して集計した結果レポートは欲しい」にはもうひと工夫必要です。
シェアだけでは実現できない部分の工夫、行アクセスポリシー
Snowflakeのデータクリーンルームでは、これを「許可済みのクエリでのみ、シェアしたテーブルに対する検索を可能にする」ことで実現しています。
許可済みのクエリとは一言一句事前に登録したSQL文と完全に一致でなければなりません。相手が持つ決まったテーブルとのJOINやGROUP BY を含む文を事前合意しておき、そのSQLでのみ結果を返す特別な形でのデータシェアリングを行うのです。
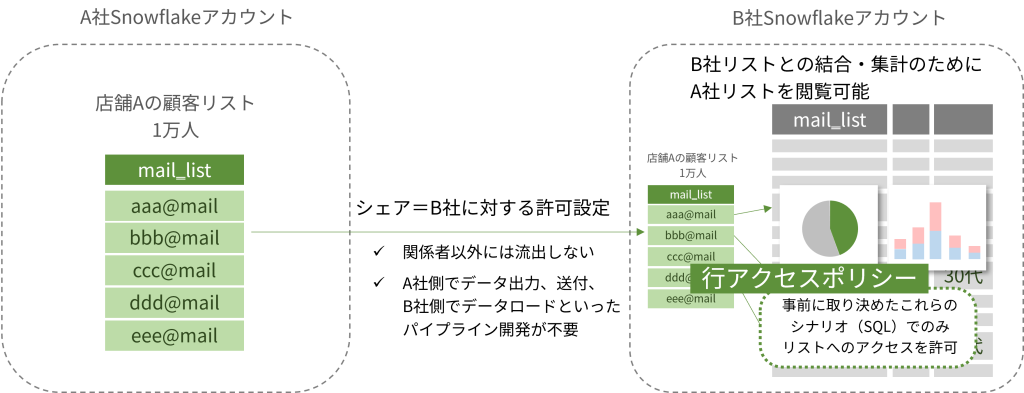
ココで登場する意外な機能が「行アクセスポリシー(Row Access Policy :RAP)」です。
実行者の権限やコンテキストを読み取って、権限にマッチする行だけを見せるWHERE条件を強制的に付与する機能で、テーブルにアタッチして使います。
つまり、RAPがアタッチされたテーブルは一見して普通にSELECTできているように見えていても、実は実行者の権限にあった適切な行だけが絞られて返されるというものです。当然、他のユーザーから見たら同じクエリで聞いてもその人の権限にあわせて違う結果が返るようになります。
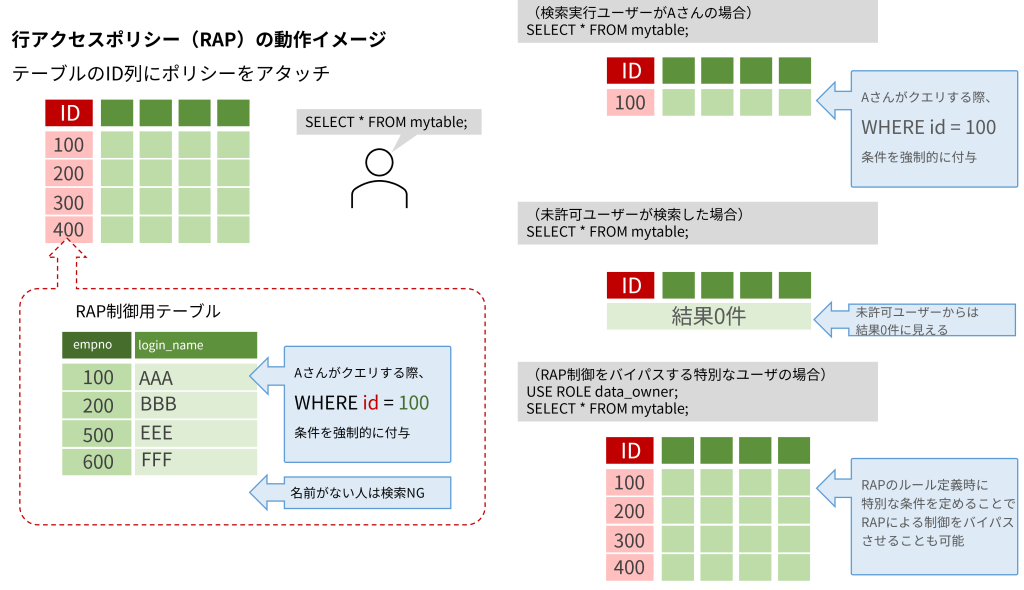
第2回、第3回で詳しく記載しますが、このRAPに「いま実行しようとしてるこのクエリは許可済みだから結果を返してOK」を判定させることができます。「許可済みクエリ」によってのみアクセスを許すことで、生のデータをすべて見せるのではなく、分析に使える集計値のみを返すことができます。
まとめ
この記事ではデータクリーンルームの目的や求められる機能、そしてSnowflakeのDCR機能の超概要を説明しました。データシェアリングと行アクセスポリシーを理解することがSnowflake DCRの理解につながります。まだまだ抽象的に感じるかもしれませんが、次回以降、具体的なサンプルを操作しながらDCRの動作を理解していきましょう!