こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
今回はDatabricksで使われているScalaというプログラミング言語について説明します。
Scalaとは、Sparkで使われているオブジェクト指向の関数型言語です。
DatabricksはフルマネージドのSparkコラボレーション環境なので、そのベーステクノロジーとなるScala言語を覚えるとDatabricksも使いこなせるようになれます。
というわけでScalaを覚えましょう!
Databricksで空白のノートブックを開いてから下記のコードを実際に入力してから結果を試して行きます。
プログラミングといえばまずは変数の宣言から。
不変なval
変数宣言の前にvalを付けることで、不変な変数を定義出来ます。
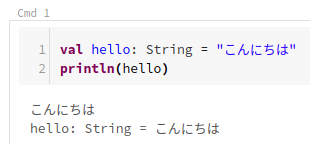
val hello: String = "こんにちは" println(hello)
この例では、不変な変数「hello」をString型で宣言して、そしてprintlnで表示させる例です。
実行すると、「こんにちは」と表示されます。
valは不変
valで宣言した変数にあとから値を入れ直そうとすると、エラーになります。
error: reassignment to val
可変なvar
varをつけると、再代入可能な可変な変数になります。
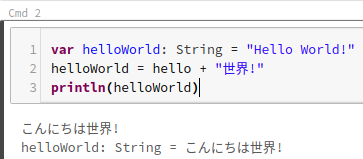
var helloWorld: String = "Hello World!" helloWorld = hello + "世界" println(helloWorld)
この例では、可変な変数「helloWorld」をString型で宣言してます。
初期値は「Hello World!」ですが、そのあとにhello + 「世界!」という値で上書きしたので
結果は、「こんにちは世界!」になります。
varは可変
if-else
条件分岐のifとelseの書き方。
val chk1: Int = 3
val chk2: Int = 5
if (chk1 > chk2) {
println("それはない。")
} else {
println("そのとおり!")
}
これは説明不要ですね。
chk1とchk2というInt型の変数の大きさを比較して、結果を表示する例です。

if-elseで分岐
forループ
繰り返し処理のforの書き方。
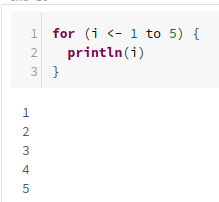
for (i <- 1 to 5) {
println(i)
}
1から5まで表示をループさせる例です。
普段Javascriptをよく書いてるので、Scalaのこの書き方はスッキリしてます。
for文でループ
関数
関数はdefで宣言します。
引数の型と戻り値の方も定義します。
def calc(i: Int, j: Int) : Int = {
i + j
}
val res = calc(2, 5)
println(res)
2つの整数を引数で受け取って、足した結果を整数で返す関数の例です。
Javascriptみたいにreturnしなくても良い。

defで関数を宣言
Tuple
タプルは異なる型の変数を持てる配列です。
Scalaでもよく使われます。
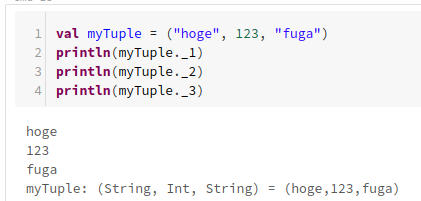
val myTuple = ("hoge", 123, "fuga")
println(myTuple._1)
println(myTuple._2)
println(myTuple._3)
_1, _2, ..というインデックス番号を使ってタプルの中身にアクセス出来ます。
異なる型を持てる配列:タプル
List
一方、リストは同じ型の変数のコレクションです。
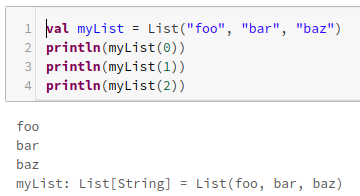
val myList = List("foo", "bar", "baz")
println(myList(0))
println(myList(1))
println(myList(2))
0から始まるインデックス番号でリストの中身にアクセス出来ます。
Listは可変な配列
タプルにはない機能があるのもリストの特徴です。
配列の中身をループで展開するならこういう書き方が出来ます。
for (item <- myList) {
println(item)
}
これもスッキリしてますね。

配列のループ
リストに組み込まれてる変数がいくつかあります。
例えばreduceで、配列の中身を順番に演算してくれます。
val numList = List(1, 2, 3) val total = numList.reduce( (x: Int, y: Int) => x + y) println(total)
これで1+2+3の結果6になります。

reduceで配列内を演算
Map
Mapはkey-value型の値の配列です。
val myMap = Map("name" -> "Exture", "tel" -> "0344445555", "city" -> "Tokyo")
println(myMap("name"))
Map内の「name」というキーに一致する値を表示する例です。

Mapはkey-value型の配列
まとめ
Scala言語はDatabricksでSparkを扱うために覚えておくべきプログラミング言語です。
勉強するための環境はDatabricksのノートブックだけではなく、ローカルPCにJava8, Spark, Scalaをインストールすればすぐに構築出来るので、ぜひScalaを始めましょう。
弊社はデジタルマーケティングからビッグデータ分析まで幅広くこなすデータ分析のプロ集団です。
お問合わせはこちらからどうぞ。
ブログへの記事リクエストはこちらまでどうぞ。