こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
先月「Google Cloud認定プロフェッショナル・データエンジニア資格」試験に合格しました。

というわけで、これからもGoogle Cloud Platformのビッグデータ製品を使ったTipsをこのブログでドシドシ紹介して行きます。
さて、今回は
“Google Analytics Stadard (無料版)を使っているが、このデータをBigQueryで分析したい。そして有料版のAnalytics 360を使う予定はない。”
というケースに効くワザです。
もちろん無料版のStandardでは、BigQueryエクスポート機能が使えないので工夫が必要です。
1.Google Analytics Standard でヒット毎にユニークなヒットIDを計測する
Gooogle Analytics Standardだと長いので、以下「GA」と略します。
GAでヒットIDを計測するためには、タイムスタンプ+ClientIDのデータをカスタムディメンションで計測します。
そうすると、訪問者別のタイムスタンプが記録されるので、これがヒットを識別するためのユニークなIDになります。
前回のブログでGTMでClientIDを取得する方法を書きましたが、今回もそれを応用してCustomTaskを使います。
では、下記のJavascriptを使って、カスタムディメンションに「タイムスタンプ+クライアントID」によるヒットIDをセットします。
この例ではdimension3番に入れてます。
名前: hit_id
中身:
function() {
return function(model) {
var cid = model.get('clientId');
var timestamp = new Date().getTime();
model.set('dimension3', timestamp + '_' + cid);
}
}
このhit_idを、GAタグのcustomTaskの値にセットします。
※customTaskフィールドの設定方法は前回のブログに書いたとおりです
2.Reporting APIでヒットIDx各ディメンション別のクロス集計データを抽出する
Reporting APIを使うためには、
・Google Cloud Platformのプロジェクトの作成
・Reporting API の有効化
・サービスアカウントの作成 → GAユーザーとしてGAに登録
この3つが必要です。
セットアップツールが用意されてるので、まだ上記のセットアップが済んでない場合は実施します。
ReportingAPIを実行するためのサービスアカウントを作成したら、JSON形式の認証キーをダウンロードしておいてください。
のちほど使います。
さらに、このサービスアカウントに対してGAレポートの閲覧権限が必要なので、
GAのユーザー設定から、今回作成したサービスアカウントをユーザーとして登録しておきます。
では、いよいよAPIを実装します。
Javascriptが大好きな私はNode.jsで実装しました。これをmain.jsという名前のファイルで保存します。
/*
* main.js
*/
if (process.argv.length < 4) {
console.log('Usage: node main.js dimenstion YYYY-MM-DD YYYY-MM-DD');
process.exit(1);
}
let dname = process.argv[2];
let start = process.argv[3];
let end = process.argv[4];
const {google} = require('googleapis');
const analyticsreporting = google.analyticsreporting({
version: 'v4'
});
let apikey = require('./my-sample-project.json'); //サービスアカウントの認証キーJSONを指定
let client = new google.auth.JWT(apikey.client_email, null, apikey.private_key, ["https://www.googleapis.com/auth/analytics"], null);
let runReport = async() => {
let res = await analyticsreporting.reports.batchGet({
resource: {
reportRequests: [{
"viewId": "123456789", //GAのビューIDを指定
"dateRanges": [{
"startDate": start,
"endDate": end
}],
"dimensions": [{
"name": "ga:dimension3" //ヒットIDが入ってるカスタムディメンション
},{
"name": dname
}],
"metrics": [{
"expression": 'ga:hits'
}]
}]
},
auth: client
});
let d = res.data.reports[0].data.rows
for (let i=0; i<d.length; i++) {
console.log(d[i].dimensions[0] + '\t' + d[i].dimensions[1]);
}
};
client.authorize().then(c => runReport());
この実装では、ヒットID(カスタムディメンション3)と、任意のディメンションをひとつクロス集計した状態で取得出来ます。
これを使って、ページパス、参照元、デバイスカテゴリ、セッション回数、などなど、、、各ディメンション別のデータを取得して行きます。
そして最後にヒットIDをキーにして集約すれば、ヒット毎のローデータ代わりになる、という事です。
さて、使い方はこうです。
$ node main ディメンション名 開始日 終了日 > 出力先ファイル
これを使って、まずは試しにページパス、参照元、デバイスカテゴリ、セッション回数を取得します。
$ node main ga:pagePath 2018-05-01 2018-05-30 > page.txt $ node main ga:fullReferrer 2018-05-01 2018-05-30 > referrer.txt $ node main ga:deviceCategory 2018-05-01 2018-05-30 > device.txt $ node main ga:sessionCount 2018-05-01 2018-05-30 > session.txt
出来上がったファイルを、BigQueryに別々のテーブルにロードして行きます。
例えば、page.txtをmy-sample-project:mydataset.pageにロードするなら
$ bq load --source_format=CSV --field_delimiter="\t" my-sample-project:mydataset.page page.txt hit_id:string,page:string
というコマンドでロード出来ます。
3.ヒットIDをキーにして各データを結合する
さて、それぞれ個別のテーブルにロードしたあとは、hit_idをキーにして結合して一つのテーブルを作ります。
#standardSQL select p.hitid as hitid, p.page as page, r.referrer as referrer, d.device as device, s.session as session from `mydataset.page` as p left join `mydateset.referrer` as r on p.hitid = r.hitid left join `mydateset.device` as d on p.hitid = d.hitid left join `mydateset.session` as s on p.hitid = s.hitid;
このクエリをテーブルとして保存すると、こういう結果になりました。
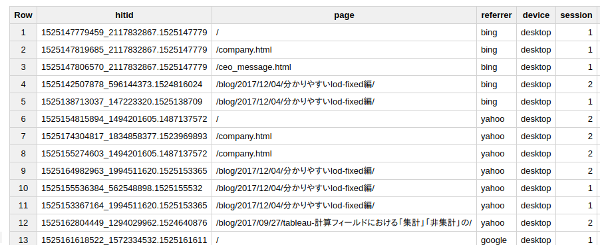
hit_id列がキーとなり、そのヒットで閲覧されたページパス、参照元、デバイスカテゴリ、セッション回数というヒットデータになっている事が分かります。
今回はヒットIDの他に4つのディメンションだけ使いましたが、同じ要領でその他のディメンションも取り出していけば、さらに詳細なヒット事のローデータを再現出来るようになります。
Reporting APIには制限があり、例えば一度に取得可能なレコードは最大10,000行までです。(デフォルトは1,000行)
そのため、10,000行以上のデータを取り出す場合は、レスポンスに含まれるnextPageTokenパラメータを取得して次のリクエストにセットする必要があります。
詳細はAPIのリファレンスに書いてあります。
今回はGoogle Analytics Standard(無料版) でヒットIDがを計測して、ヒット事のデータをReporting APIで抽出してBigQueryにロードする方法についてでした。
弊社はGoogle Cloud認定データエンジニア資格を持つエンジニア達がGoogle AnalyticsやAdobe Analyticsのデータを分析するための分析基盤構築の支援を行っております。
お問い合わせはこちらからどうぞ。
ブログへの記事リクエストはこちらまで