
こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
今回はBigQueryのtime_partitioning_fieldオプションを使った分割テーブルの作成についてです。
2018年4月4日現在、まだベータ機能ですが、 Column based time partitioned table の記事に詳細が載ってます。
従来、Adobe AnalyticsのデータフィードをBigQueryにロードするとしたら日付別にテーブルを作成するか、または_PARTITIONTIME擬似列を使って日別パーティションを作成する方法が主な手法でした。
しかしtime_partitioning_fieldを使えば、データはそのままで、既存のTIMESTAMP型もしくはDATE型のカラムを指定するだけで日付情報を元にしたパーティションを作成出来るという事です。
Column-based Time-partitioned Tableを作成する
まずはテーブルを作成します。
time_partitioning_field オプションを使って、hit_time_gmtカラムをパーティショニングカラムに指定します。
スキーマは長いの省略。
$ bq mk --table --schema 'accept_language:string,...(中略)' --time_partitioning_field hit_time_gmt myproject:mydataset.hit_data
なお、アプリのオフライン計測でTimestamped Hitを使ってる場合は、hit_time_gmtカラムの代わりにcust_hit_time_gmtを使う必要があります。
date_timeカラムを使えばいいんじゃないの?とも思いますが、date_timeカラムはGMTじゃなくてレポートスイートのタイムゾーン設定に依存してるため、「GMT+9」になるので使いませんでした。
さて、作成したテーブルの詳細を確認します。
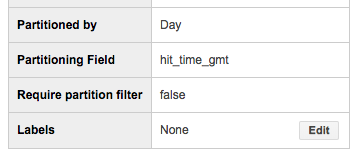
Partitioning Fieldにhit_time_gmtカラムが指定されている事が分かります。
Column-based Time-partitioned Tableにデータをロードする
これはいつもどおりのbq loadコマンドでOKです。
$ bq load --field_delimiter='\t' myproject:mydataset.hit_data hit_data.tsv
hit_data.tsvのデータがBigQueryにロードされました。
期間をWHERE句で絞り込んでクエリ
さて、では期間を絞ってクエリを投げてみます。
time_partitioning_fieldを使っているテーブルでは、レガシーSQLが使えません。
標準SQLを使います。
例えば2017/4/1の全体のPV、訪問回数、訪問者数を抽出します。
SELECT COUNT(post_pagename) AS pageview, COUNT(DISTINCT CONCAT(post_visid_high,post_visid_low, CAST(visit_num AS STRING))) AS visits, COUNT(DISTINCT CONCAT(post_visid_high, post_visid_low)) AS visitors FROM `myproject.mydataset.hit_data` WHERE DATETIME(hit_time_gmt, 'Asia/Tokyo') >= '2017-04-01' AND DATETIME(hit_time_gmt, 'Asia/Tokyo') < '2017-05-01' AND hit_source = 1 AND exclude_hit = 0 ORDER BY pageview DESC;
結果はこうなります。
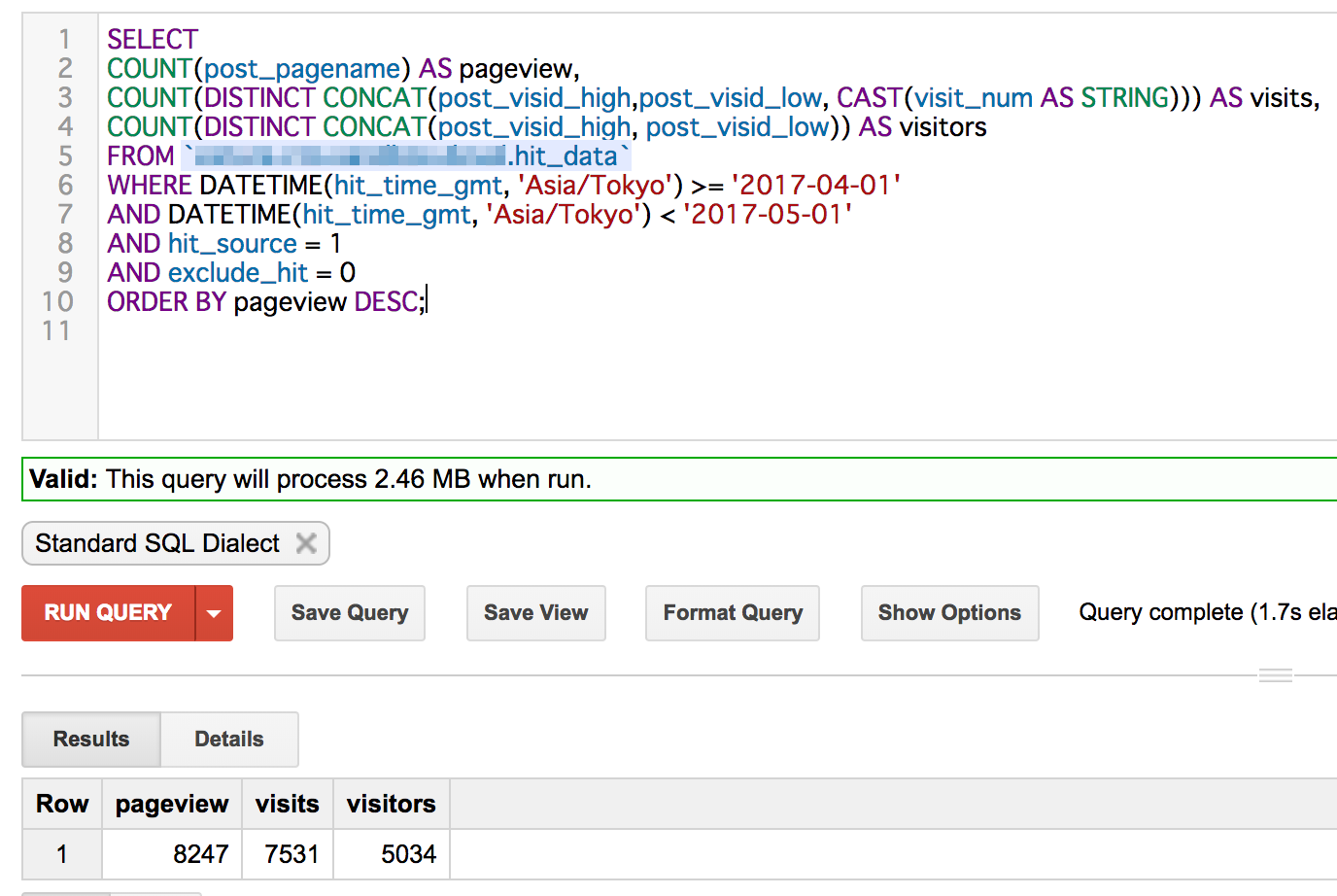
これだけ見ても分からないですねw
hit_time_gmtカラムの値で日別パーティショニングされているので、テーブルの行全体に対するクエリではなく、あくまでも対象期間だけのクエリです。
その結果、BigQueryのクエリコストを抑えられます。
これで日付別に個別テーブルを作る縛りからも開放されるし、_PARTITIONTIME擬似列を使う必要もない。
運用が少し楽になったらいいなー、てところです。
今回は、AdobeのデータフィードをBigQueryのtime_partitioning_fieldを使ったテーブルにロードする方法についてでした。
弊社ではAdobe Analyticsの過去データをGoogle Cloud Platformなどのクラウド上で可視化・分析するための分析基盤構築のお手伝いなどをしております。
お問合わせはこちらからどうぞ。
ブログへの記事リクエストはこちらまで











