BigQuery: Adobe Datafeed: event_listカラムの手軽な扱い方

こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
今回は、AdobeAnalyticsのDatafeedをBigQueryに入れた時にevent_list(主にpost_event_list)をどう扱うかというTipsです。
※ヒットに含まれるs.events変数はevent_listが無加工のオリジナルで、post_event_listがProcessing RulesとVISTAなどの処理を経た最終的なインプットです。
event_listカラムの扱いがメンドクサイなと思う事はありませんか?
なければそれで結構なんですがw、私が見聞きした中ですと・・・
- そのままカンマ区切りで格納
- event_listをカンマでsplitしてか各event毎に別カラムに格納(横方向に広げる)
- event_listをカンマでsplitして、別の行に分けて格納(縦方向に伸ばす)
というケースに別れました。
私は「そのまま派」です。
理由は単純で、
カラムを増やして横方向に伸ばすとクエリするカラムが増えて管理が煩雑なのと、
縦方向に行を増やすとデータ量が増えてしまうためです。
では、実際にクエリする時にどうしてるのかというと、「event_listの前後にカンマを付けて検索する」です。
event_listの前後にカンマを付けて検索する
例えば以下のようなevent_listが格納されている場合:
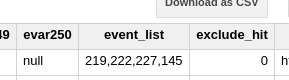
同じヒットの中にevent20(219), event23(222), event28(227), eVar46インスタンス(145)が同時に含まれてます。
ここで、「2017/11/1にevent20が発生した訪問者数を集計したい」という場合は、こんなクエリで抽出してます。
※post_event_listを対象としています。
#standardSQL
select
format_timestamp('%Y-%m-%d', timestamp_seconds(hit_time_gmt), 'Asia/Tokyo') as hitdate,
count(distinct concat(post_visid_high, '-', post_visid_low)) as visitors
from
hoge.datafeed
where
-- post_event_listの前後にカンマをつけて「%,219,%」を検索
concat(',', post_event_list, ',') like '%,219,%'
and hit_source = 1
and exclude_hit = 0
and format_timestamp('%Y-%m-%d', timestamp_seconds(hit_time_gmt), 'Asia/Tokyo') = '2017-11-01'
group by
hitdate
結果はこうなります。

11/1にevent20が発生した訪問者の数は 1,879人 でした。
まとめ
前後にカンマをつけることによって、
- event20が単独で発生している場合 ・・・ 219 -> ,219, に変換
- event20よりも前のeventと同時発生している場合 ・・・ 218,219 -> ,218,219, に変換
- event20よりも後のeventと同時発生している場合 ・・・ 219,220 -> ,219,220, に変換
という文字列に変わるため、 %,219,% の検索がマッチするようになります。
つまり、イチイチ正規表現でカンマの存在を考慮したり、splitして1個ずつ判定していかなくてもOKです。
通常のRDBでこんなSQL書いてると激重で怒られそうですが、ここは流石のBigQueryです。全く問題になりません。
なお、event1〜event100は 200〜299 という範囲の番号が付与されてますが、
event101〜event1000は 20100〜20999 という番号になっているのでご注意ください。
あと、purchaseIDとevent serializationを考慮すると、若干クエリの内容も変わりますが、だいたいこんな感じです。
弊社はAdobe AnalyticsのDatafeedとBiqQueryを活用したビッグデータ分析支援などを行なっております。
お問い合わせはこちからどうぞ。
ブログへの記事リクエストはこちらまで