こんにちは、インターン生の大石です。
データ活用基盤を構築する上で、さまざまなデータソースを統合することは重要です。
さらに、正確なデータ分析を行うためには、データソースに加えられた変更を速やかに同期する必要があります。
そこで本記事では、そんな機能を提供してくれるサービスとしてFivetranをご紹介します。
後半では、スプレッドシートからBigQueryへの接続方法も解説します。
目次
概要
Fiveranは、クラウドベースのデータ統合プラットフォームです。
さまざまなデータソース(データベース、クラウドサービスなど)からデータを自動で抽出し、データウェアハウスや分析基盤にロードすることができます。
また、定期的な同期やカラムの追加/削除の検知により、最新のデータソースが反映された状態を保つことが可能です。
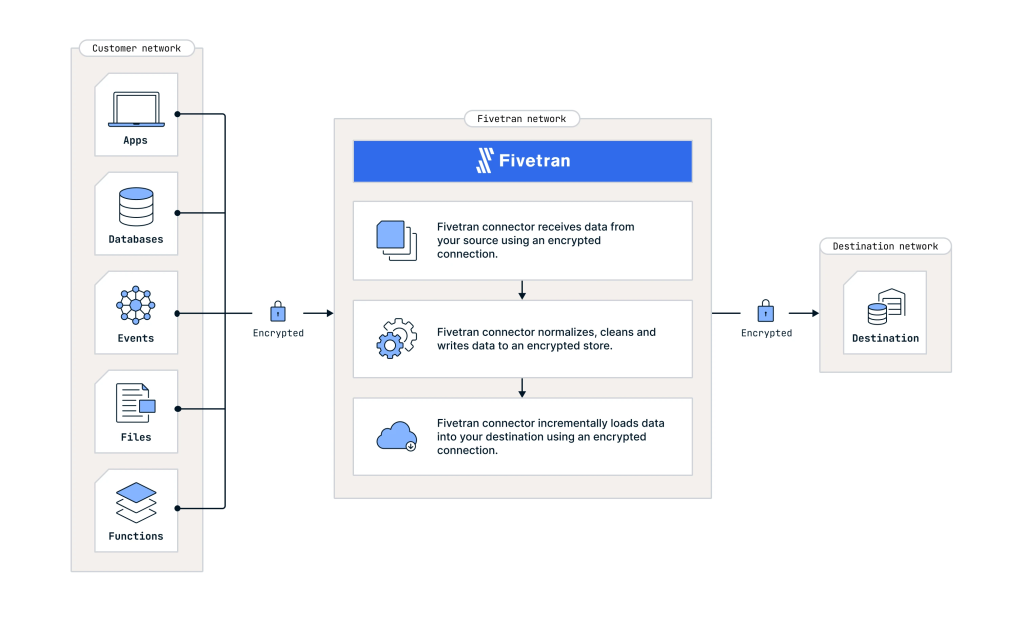
Fivetranドキュメントより:https://fivetran.com/docs/deployment-models/saas-deployment
主な特徴
– 豊富なコネクタ
Fivetranは700以上のデータソースに対応しており、主要なクラウドサービスを幅広くサポートしています。
・カスタムコネクタを作成すれば、非対応のDBや社内独自のシステムからも抽出が可能
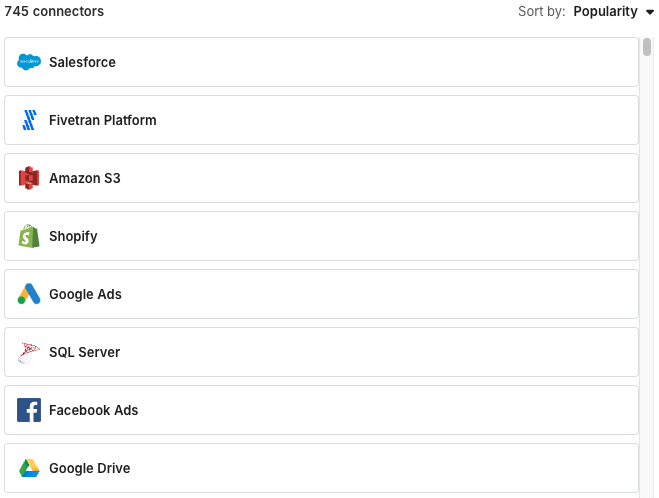
– 定期的な同期実行
自動でデータソースとの同期を行うため、手動での作業が不要になります。
・同期間隔は、日次から1分ごとまで可能(プランによって変動)
– 自動スキーマ管理
ソースデータの列追加やデータ型変更にも自動で対応します。
・手動で設定を変更する手間が不要
・データの整合性を維持しながら最新情報を反映
価格体系
Fivetranは 使用量ベース(従量課金制) の料金モデルを採用しています。
必要な分だけ支払う仕組みのため、スモールスタートにも大規模運用にも柔軟に対応できます。
– 料金の計算指標は2つ
Fivetranでは、次の 2 つの指標によって料金が決まります。
- Monthly Active Rows(MAR)
月間で実際に「挿入 / 更新された行数」 を指します。
同期の際、前回から追加された行 / データが更新された行だけがカウントされます。
初回の全件ロードや、変化がなかった行は課金対象外となるため、大規模なデータソースでも効率的なコスト管理が可能です。
- Monthly Model Runs(MMR)
変換ジョブ(dbt Core 連携など)の成功実行回数に基づく料金指標です。
Fivetranのデータ変換機能を利用した回数に応じて課金されます。
– プラン別の料金と特徴
Fivetranには4つの料金プランが提供されています。
利用規模やセキュリティ要件に応じて選ぶことができます。
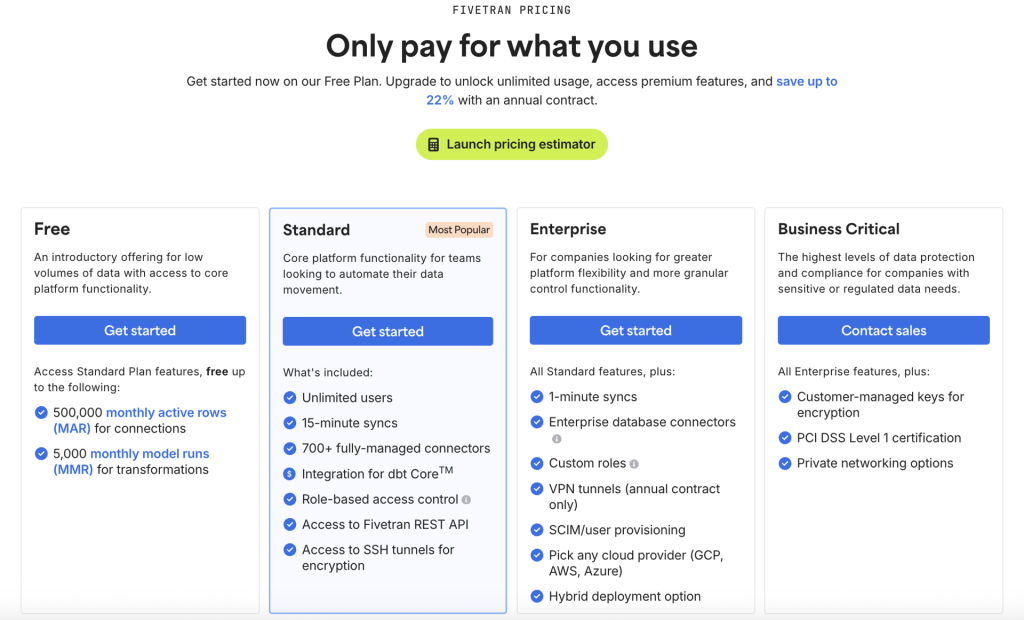
FivetranHPより:https://www.fivetran.com/pricing
🟦 Free プラン
・MAR:50万行(500,000 MAR)まで無料
小規模プロジェクトや PoC(検証用途)に最適
🟩 Standard プラン
・MAR:Million MAR あたり $500/月 から
(MARが増えるほど単価が下がる段階的ディスカウント)
・機能:無制限ユーザ、15分単位の同期、700+のコネクタ利用、REST API 利用、dbt連携、など
データパイプラインを自動化したいチーム向け

FivetranHPより:https://www.fivetran.com/pricing
🟧 Enterprise プラン
・MAR:Million MAR あたり $667/月 から
(Standard プランと同様に段階的ディスカウントが適用)
・機能:1分単位の同期、任意のクラウドプロバイダの選択、など
高データ量、大規模導入、厳しいガバナンス/セキュリティ要件を持つ企業向け
🟥 Business Critical プラン
・MAR:Million MAR あたり $1,067/月 から
(Standard プランと同様に段階的ディスカウントが適用)
最も厳格なセキュリティ/コンプライアンス要件を持つ企業向け
MMRは、どのプランでも単価が変わらず、毎月最大5,000回のモデル実行が無料で利用できます。
5,000回を超過すると、以下の価格表に基づいて従量課金の対象となります。

FivetranHPより:https://www.fivetran.com/pricing
接続してみる
ここまでの内容で、Fivetranがどのようなサービスかある程度理解していただけたかと思います。
ここからは、実際にスプレッドシートからBigQueryに接続するコネクタを作成して、データをロードしてみましょう。
コネクタの作成には、データソースを指定する「Connection」と、ロード先を指定する「Destination」を設定する必要があります。
Connectionから順番に設定していきましょう。
– Connection
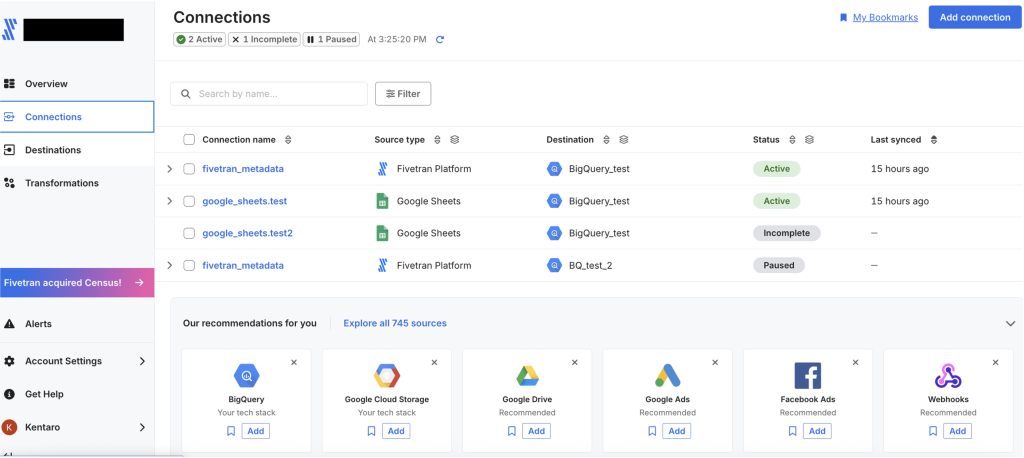
右上のAdd connectionから、対応したソースを選択します。今回はGoogle Sheetsを選択。
すでにDestinationが複数存在している場合、どこを宛先にするかを選択します。
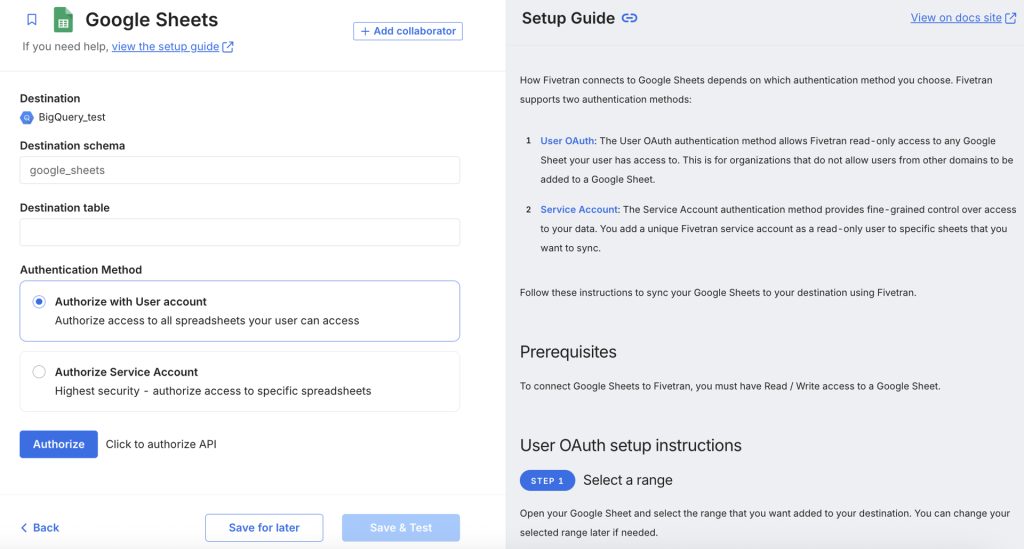
設定画面では、右側にドキュメントが表示されるので、それに従って入力していきます。
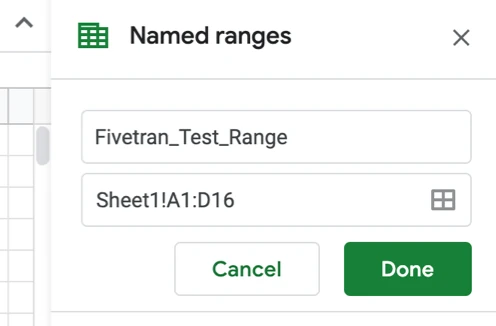
スプレッドシートをデータソースにする場合、抽出したいシート/セルを名前付き範囲として定義しておく必要があります。
Save & Testを押すと、接続テストが実行されます。成功すれば設定完了です。
– Destination
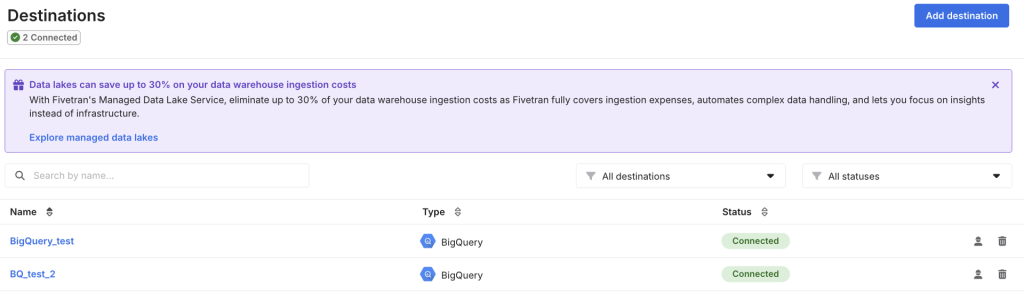
右上のAdd destinationから、ロード先を選択します。今回はBigQueryを選択。
BigQueryにロードする場合、GCP側でサービスアカウントの設定が必要です。
今回は、fivetranが管理するSAに対してロールを付与する方法で進めます。
Connection Testが成功すれば設定完了です。
– Sync
ConnectionとDestinationを作成すると、まず初回同期(histrical sync)が実行されます。
初回同期では、データソースからすべてのデータがロードされます。
Connectionの一覧から詳細を開くと、同期のログが確認できます。
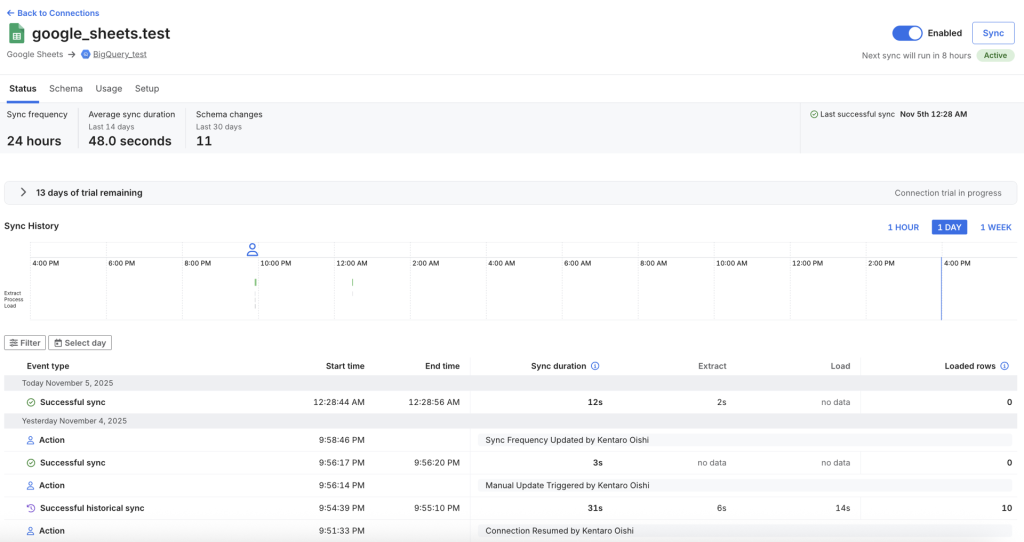
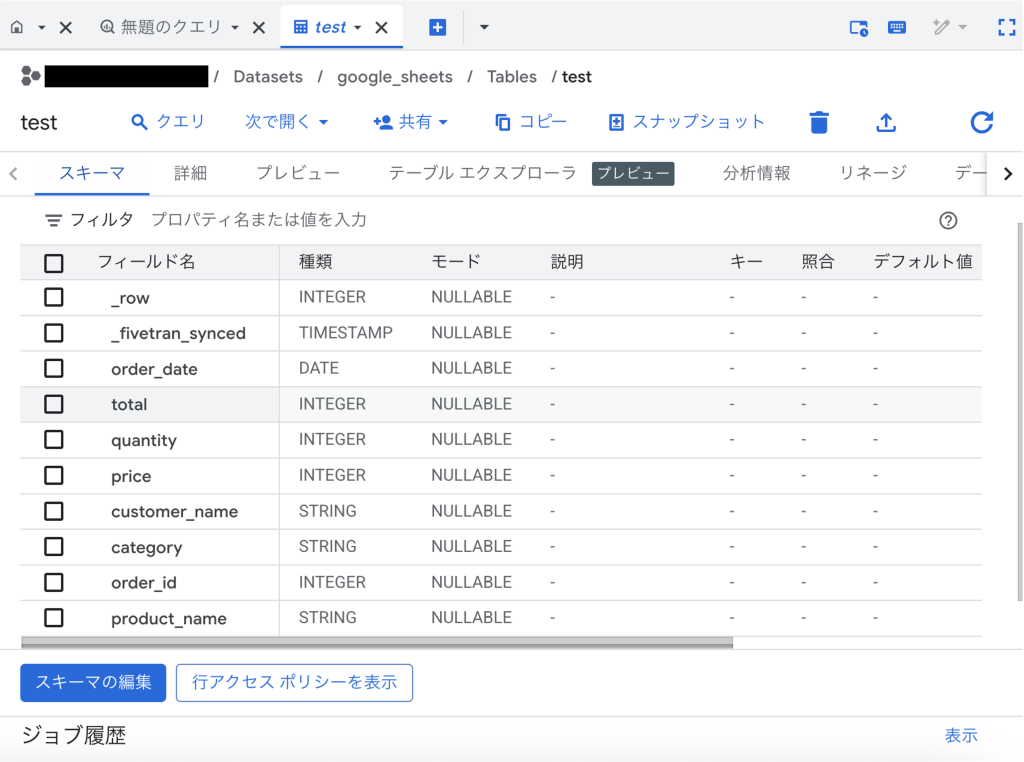
BigQueryのテーブルを見ると、スプレッドシートのデータがロードされているのが確認できました。
また、データ型がFivetranにより自動で定義されています。
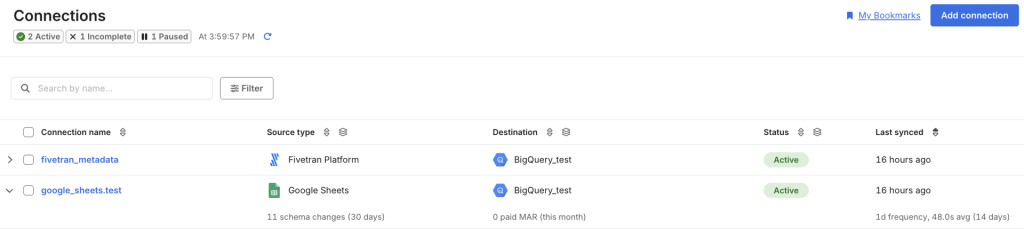
自動でfivetran_metadataというコネクタが作成され、BigQueryにもテーブルとしてロードされていました。
これはFivetranが自動で作成・管理する メタデータ用のコネクタで、
Fivetran自身の運用状況や同期状態、スキーマ構成などを宛先に自動的にロードしています。
まとめ
今回はFivetranについてご紹介し、スプレッドシートからBigQueryへの接続を設定してみました。
設定がGUIで完結しており、簡単に接続できるのもFivetranの特徴ですね。
Fivetranには、dbtと連携してデータ変換を行う機能もあるので、次回はそちらをご紹介します!