Streamlit in Snowflakeによるダッシュボード作成
こんにちは、エクスチュアの石原です。
前回に引き続き、Streamlit in Snowflakeを使用したシンプルでインタラクティブなダッシュボード作成についてご紹介します。
前回の記事をご覧になってない方はぜひ併せてお読みください。
前回の記事では、SISによるアプリケーションのデプロイ方法を紹介しました。今回は実際にStreamlitを使用したダッシュボード構築の方法についてご紹介します。
Snowsightでのダッシュボード作成
今回はStreamlit in SnowflakeとSnowflake Notebookを使用してダッシュボードを作成したいと思います。
今回使用したデータはhttps://www.kaggle.com/datasets/shivamb/netflix-showsです。
データはCSVでダウンロードして、Snowflake上でテーブル化しました。
今回コード開発にはNotebookを使用します。streamlitの結果をすぐに確認できるので非常に便利です。
データの確認
import streamlit as st
import pandas as pd
from snowflake.snowpark.context import get_active_session
session = get_active_session()
dataframe = session.table('TITLES')
netflix_data = dataframe.to_pandas()
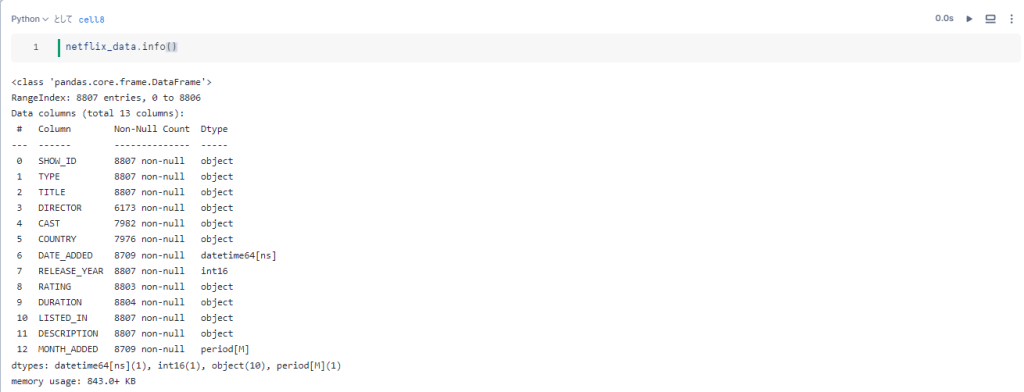

まず、df.info()やdf.head()でデータセットの中身を確認するとカンマ区切りのデータやnull値があることがわかったのでその辺りの処理も踏まえていきます。
データ加工
日付のカラムをdatetime型に変換し、次ごとのカラムを新規追加しました。
netflix_data['DATE_ADDED'] = pd.to_datetime(netflix_data['DATE_ADDED'], errors='coerce')
netflix_data['MONTH_ADDED'] = netflix_data['DATE_ADDED'].dt.to_period('M')
ダッシュボードの内容
ダッシュボードとして可視化する内容は以下のものにします。
- KPI
- リリース月ごとのコンテンツ数の推移
- コンテンツのタイプ別分布
- ジャンル別コンテンツ数の分布
- コンテンツ追加日の傾向
- Rating分布
ダッシュボードの見た目を整えるために、st.cloumnsを使用していきます。
KPI
KPIの作成にはst.metricが使用できます。delta値に前回期間からの差分の数値を入れるとダッシュボードらしい表示が出来ます。
x = 10
y = 3
st.metric('総コンテンツ数',x,delta = x-y)
作成したい項目をdfから取得する方法を生成AIに投げてその結果を張り付けていい感じに調整していきましょう。(Snowflake Copilotが使用できる環境であれば、そちらでのコード生成をぜひお試しください)
個人的にデータの作成と描画処理は分離することでstreamlitでの可視化の際に各コンテンツを動かしやすい構造になるのでおすすめです。
# KPIの計算
# 最新レコードの前月
one_month_ago = netflix_data['MONTH_ADDED'].max() - 1
last_month_data = netflix_data[netflix_data['MONTH_ADDED'] < one_month_ago]
# コンテンツ数
total_contents = netflix_data.shape[0]
delta_total_contents = total_contents-last_month_data.shape[0]
# 映画の上映時間
movies_only = netflix_data[netflix_data['TYPE'] == 'Movie'].copy()
movies_only['DURATION_minutes'] = movies_only['DURATION'].str.replace(' min', '').astype(float)
last_month_movies_only = last_month_data[last_month_data['TYPE'] == 'Movie'].copy()
last_month_movies_only['DURATION_minutes'] = last_month_movies_only['DURATION'].str.replace(' min', '').astype(float)
movie_duration = round(movies_only['DURATION_minutes'].mean(),1)
delta_movie_duration = round(last_month_movies_only['DURATION_minutes'].mean()-movies_only['DURATION_minutes'].mean(),1)
# 最多国
country_counts = netflix_data['COUNTRY'].value_counts()
top_country = country_counts.idxmax()
top_country_count = country_counts.max()
last_month_country_counts = last_month_data['COUNTRY'].value_counts()
last_month_top_country = last_month_data['COUNTRY'].value_counts().idxmax()
last_month_top_country_count = last_month_country_counts.max()
delta_top_country = "off" if top_country == last_month_top_country else "inverse"
# 最多ジャンル
genre_series = netflix_data['LISTED_IN'].str.split(',').explode()
genre_counts = genre_series.value_counts()
top_genre = genre_counts.idxmax()
last_month_genre_series = last_month_data['LISTED_IN'].str.split(',').explode()
last_month_top_genre = genre_series.value_counts().idxmax()
delta_top_genre = "off" if top_genre == last_month_top_genre else "inverse"
# Grouping by 'MONTH_ADDED' and 'TYPE' to count the number of contents added by type each month
content_added_by_month_type = netflix_data.groupby(['MONTH_ADDED', 'TYPE']).size().unstack().fillna(0)
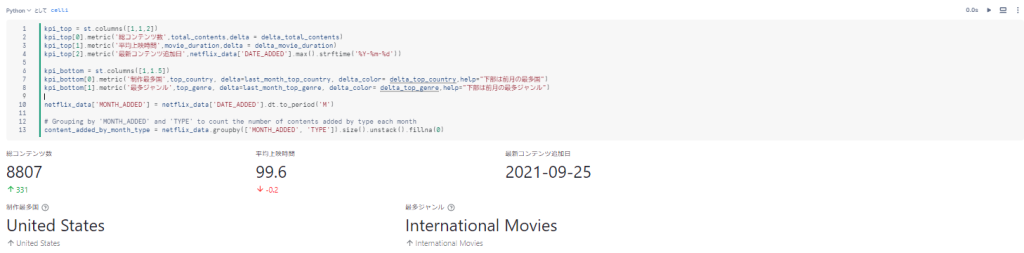
kpi_top = st.columns([1,1,2])
kpi_top[0].metric('総コンテンツ数',total_contents,delta = delta_total_contents)
kpi_top[1].metric('平均上映時間',movie_duration,delta = delta_movie_duration)
kpi_top[2].metric('最新コンテンツ追加日',netflix_data['DATE_ADDED'].max().strftime('%Y-%m-%d'))
kpi_bottom = st.columns([1,1.5])
kpi_bottom[0].metric('制作最多国',top_country, delta=last_month_top_country, delta_color= delta_top_country,help="下部は前月の最多国")
kpi_bottom[1].metric('最多ジャンル',top_genre, delta=last_month_top_genre, delta_color= delta_top_genre,help="下部は前月の最多ジャンル")
netflix_data['MONTH_ADDED'] = netflix_data['DATE_ADDED'].dt.to_period('M')
# Grouping by 'MONTH_ADDED' and 'TYPE' to count the number of contents added by type each month
content_added_by_month_type = netflix_data.groupby(['MONTH_ADDED', 'TYPE']).size().unstack().fillna(0)
ノートブックだと結果の確認が簡単なので、ひとつづつ結果を追加していきましょう。
コンテンツのタイプ別分布
グラフには今回plotlyを使用します。
基本的に集計⇒可視化の流れで一つずつグラフを作成していきます。
content_added_by_month_type = netflix_data.groupby(['MONTH_ADDED', 'TYPE']).size().unstack().fillna(0)
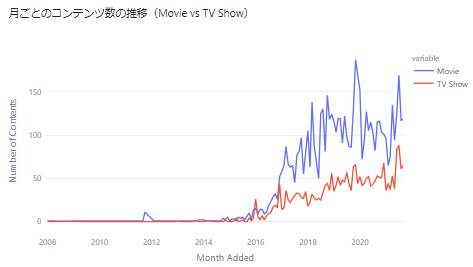
fig_content_addition_by_month_type = px.line(content_added_by_month_type,
x=content_added_by_month_type.index.astype(str),
y=['Movie', 'TV Show'],
labels={'x': 'Month Added', 'value': 'Number of Contents'},
title='月ごとのコンテンツ数の推移(Movie vs TV Show)')
st.plotly_chart(fig_content_addition_by_month_type)
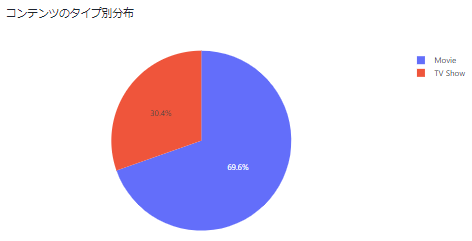
コンテンツのタイプ別分布
fig_type = px.pie(netflix_data,
names='TYPE',
title='コンテンツのタイプ別分布')
st.plotly_chart(fig_type)
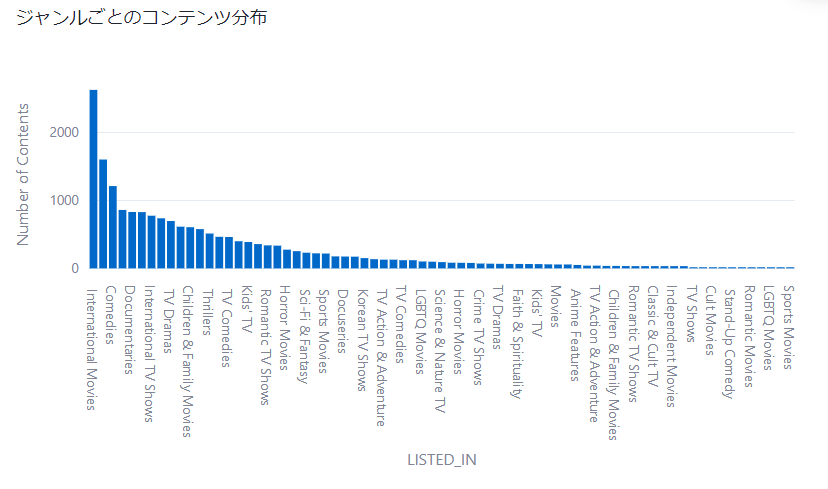
ジャンルごとのコンテンツ分布
fig_genre_distribution = px.bar(genre_counts,
x=genre_counts.index,
y=genre_counts.values,
labels={'x': 'Genre', 'y': 'Number of Contents'},
title='ジャンルごとのコンテンツ分布')
st.plotly_chart(fig_genre_distribution)
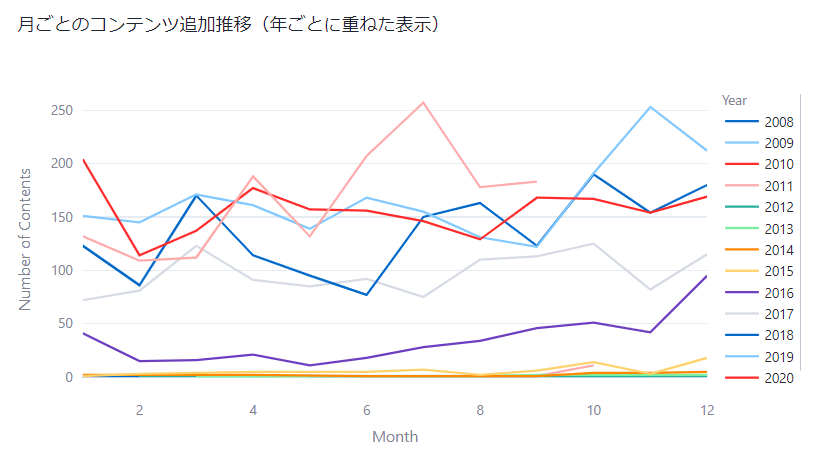
コンテンツ追加日の傾向
# NaNを含む行を削除
netflix_data = netflix_data.dropna(subset=['DATE_ADDED']).copy() # copy()を使用して明示的に新しいコピーを作成
# 'YEAR' と 'MONTH' 列を作成し、YEARを整数型に変換 (loc[]を使用して警告を回避)
netflix_data.loc[:, 'YEAR'] = netflix_data['DATE_ADDED'].dt.year.astype(int)
netflix_data.loc[:, 'MONTH'] = netflix_data['DATE_ADDED'].dt.month
# 'YEAR' と 'MONTH' ごとにコンテンツ追加数を集計
content_added_by_month_year = netflix_data.groupby(['YEAR', 'MONTH']).size().reset_index(name='Number of Contents')
# 年ごとに重ねて表示する月ごとのコンテンツ追加推移をプロット
fig_content_addition_by_month_year = px.line(content_added_by_month_year,
x='MONTH',
y='Number of Contents',
color='YEAR', # 年ごとに色分け
labels={'MONTH': 'Month', 'Number of Contents': 'Number of Contents', 'YEAR': 'Year'},
title='月ごとのコンテンツ追加推移(年ごとに重ねた表示)')
# グラフを表示
st.plotly_chart(fig_content_addition_by_month_year)
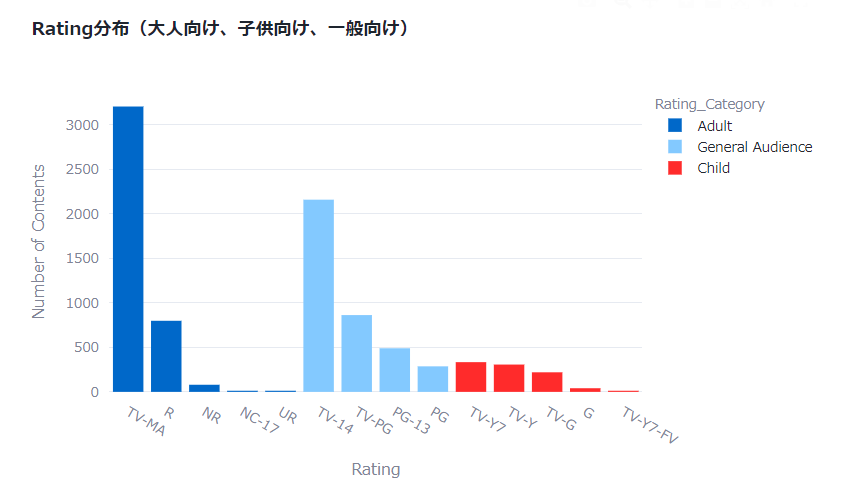
Rating分布
Kaggleのデータセットページに記載されている内容もありますが、Ratingの内容がわからなかったので確認してみます。
import pandas as pd
# Load the dataset
file_path = 'netflix_titles.csv'
netflix_data = pd.read_csv(file_path)
netflix_data['rating'].unique()
['PG-13', 'TV-MA', 'PG', 'TV-14', 'TV-PG', 'TV-Y', 'TV-Y7', 'R', 'TV-G', 'G', 'NC-17', '74 min', '84 min', '66 min', 'NR', nan, 'TV-Y7-FV', 'UR']
時刻が誤って入っているものがありますね。今回は該当のレコードはdurationに修正しておきます。
import numpy as np
netflix_data.loc[netflix_data['show_id'] == 's5542', ['rating', 'duration']] = [np.nan, '74 min'] netflix_data.loc[netflix_data['show_id'] == 's5795', ['rating', 'duration']] = [np.nan, '84 min'] netflix_data.loc[netflix_data['show_id'] == 's5814', ['rating', 'duration']] = [np.nan, '66 min']
この評価は視聴者層の絞りこみに使用されており、大人向けのものから順に以下のようになっています
['NC-17', 'R', 'TV-MA', 'UR', 'NR', nan, 'PG-13', 'TV-14', 'PG', 'TV-PG', 'TV-Y7-FV', 'TV-Y7', 'TV-G', 'G', 'TV-Y']
大人向け、子供向け、一般向けに分けてカテゴリを定義してみます。
# 大人向け、子供向け、一般向け(General Audience)のカテゴリを定義
adult_ratings = ['NC-17', 'R', 'TV-MA', 'UR', 'NR']
child_ratings = ['TV-Y7-FV', 'TV-Y7', 'TV-G', 'G', 'TV-Y']
general_audience_ratings = ['PG-13', 'TV-14', 'PG', 'TV-PG']
# 評価をカテゴリに分ける関数
def categorize_rating(rating):
if rating in adult_ratings:
return 'Adult'
elif rating in child_ratings:
return 'Child'
elif rating in general_audience_ratings:
return 'General Audience'
else:
return 'Unknown'
# カテゴリを適用して新しい列を作成
netflix_data['Rating_Category'] = netflix_data['RATING'].apply(categorize_rating)
# 各評価ごとにコンテンツ数を集計
rating_distribution = netflix_data['RATING'].value_counts().reset_index()
rating_distribution.columns = ['Rating', 'Number of Contents']
# カテゴリを追加
rating_distribution['Rating_Category'] = rating_distribution['Rating'].apply(categorize_rating)
# 大人向け、子供向け、一般向けで色分けした棒グラフを作成
fig_rating_distribution = px.bar(rating_distribution,
x='Rating',
y='Number of Contents',
color='Rating_Category',
labels={'Rating': 'Rating', 'Number of Contents': 'Number of Contents'},
title='Rating分布(大人向け、子供向け、一般向け)')
# グラフを表示
st.plotly_chart(fig_rating_distribution)
スライダーを追加
# Streamlitで日付範囲を選択するウィジェットを作成
min_date = netflix_data['DATE_ADDED'].min().date() # .date()で日付のみを取得
max_date = netflix_data['DATE_ADDED'].max().date()
# スライダーではなく日付範囲選択を使用
selected_date_range = st.date_input("Select Date Range", (min_date, max_date), min_date, max_date, format="YYYY-MM-DD")
# フィルタリング条件
if isinstance(selected_date_range, tuple) and len(selected_date_range) == 2:
# 2つの日付がある場合は範囲でフィルタリング
start_date, end_date = selected_date_range
elif isinstance(selected_date_range, pd.Timestamp) or selected_date_range:
# 単一の日付がある場合はその日付でフィルタリング
start_date = end_date = selected_date_range
else:
# Noneまたは範囲外の場合、全データを使用
start_date, end_date = min_date, max_date
# ユーザーが選択した日付範囲でデータをフィルタリング
netflix_data = netflix_data[(netflix_data['DATE_ADDED'] >= pd.Timestamp(start_date)) &
(netflix_data['DATE_ADDED'] <= pd.Timestamp(end_date))]
期間が狭い場合にKPIのlast_month_top_countryでエラーになるので修正
try:
last_month_top_country = last_month_data['COUNTRY'].value_counts().idxmax()
except ValueError:
last_month_top_country = None
また、冒頭に画面全体の幅を変更するコード、タイトル、メッセージを追加することでダッシュボードとしての体裁を整えます。
st.set_page_config(layout="wide")
st.title("Netflix Movies and TV Shows")
st.write(
"""
このデータセットについて
Netflixは、最も人気のあるメディアとビデオ・ストリーミング・プラットフォームの一つである。
Netflixのプラットフォームでは8000以上の映画やテレビ番組が視聴可能で、2021年半ば現在、全世界で2億人以上の加入者がいる。
この表形式のデータセットは、Netflixで視聴可能なすべての映画やテレビ番組のリストと、キャスト、監督、視聴率、公開年、上映時間などの詳細から構成されている。
""")
st.markdown("---")
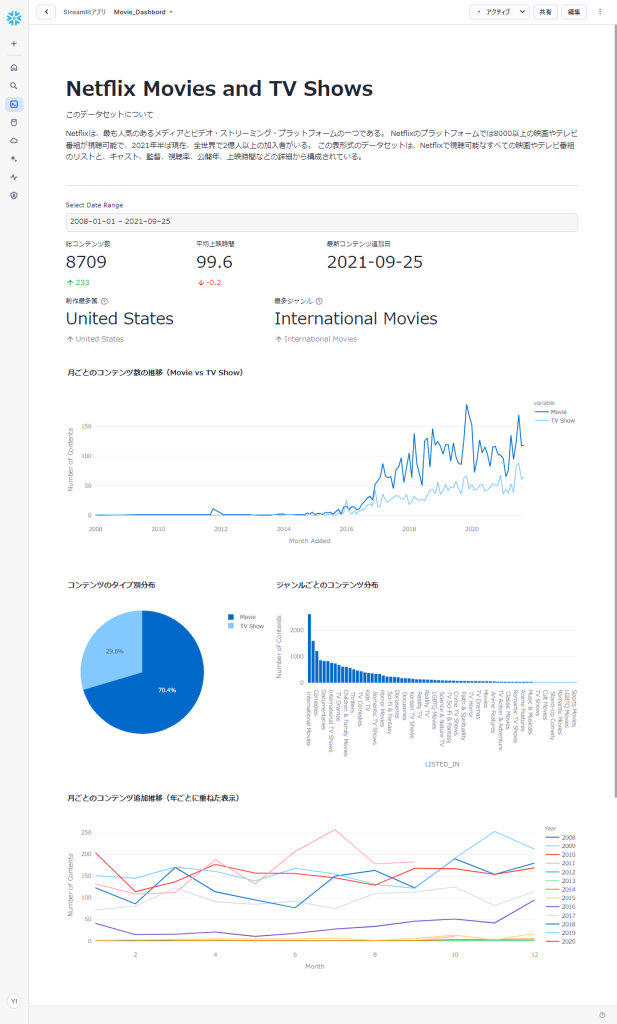
完成
こちらが完成したダッシュボードです。
いかがでしょうか? なかなか見栄えの良い仕上がりになっていると思います。
まとめ
今回の記事では、Streamlit in Snowflakeを使ったダッシュボード作成の方法についてご紹介しました。BIツールを使用しないでも、このぐらいの可視化であれば簡単に実施することが出来ます。
皆さんもぜひ、SISを使ってダッシュボード作成に挑戦してみてください!
エクスチュアはマーケティングテクノロジーを実践的に利用することで企業のマーケティング活動を支援しています。
ツールの活用にお困りの方はお気軽にお問い合わせください。