Open Interpreter+VScode+Dockerで生成AIによるコード開発環境構築(Windows)

はじめに
こんにちは、エクスチュアの石原です。
皆さん、Open Interpreterをご存知でしょうか?
2023年9月にGithubにて公開され、2024年6月現在で約5万スターが付いている生成AI関連でかなりの注目を集めているリポジトリになります。すでに多くの方がブログなどアップされており、流行に遅れたN番煎じの記事にはなりますが、自分自身の勉強を兼ねてご紹介していきますので、どうぞよろしくお願いいたします。
今回の記事ではOpen Interpreterを使用した生成AI活用開発環境の構築を実施していきたいと思います。なぜ環境構築を行うかというと、Open Interpreterはローカル環境のリソースを自動で更新してしまったり、最悪の場合データを削除してしまうという危険性を持っているためです。
そのため、環境構築の際にはVSCodeのRemoteContainer拡張機能を使用して、安全な仮想環境を用意したいと思います。そして、環境構築後にはOpen Interpreterどんなことができるか実験して確認してみましょう。
まずは今回使用するそれぞれのツールについてご紹介します。
Open Interpreter
Open Interpreterは、大規模言語モデル(LLM)に自然言語で指示することで、コード(Python、Javascript、Shell など)を作成、さらに、ローカル環境でそのコードを実行までしてくれます。
試すだけならインストール後、interpreterを実行するとターミナル経由で、Chat形式のインターフェースでOpen Interpreterとチャットができます。Open Interpreterはあなたがパソコンを操作するように一般的なコードを実行できます。これにより、自然言語でパソコンのを操作することができます。
例えばOpen InterpreterのREADMEでは以下のような操作ができると記載されています。これだけの操作をチャット形式でできるのですから非常に便利なのは言うまでもありません。
- 写真、動画、PDF などの作成や編集
- Chrome ブラウザの制御とリサーチ作業
- 大規模なデータセットのプロット、クリーニング、分析
GitHubのリポジトリ:https://github.com/OpenInterpreter/open-interpreter
Open Interpreterの使用上の注意点
大きく分けて2つの注意点があります。
- 自動処理によるリスク
- AGPLライセンスのリスク
1つ目のリスクはOpen Interpreterによってファイルが削除されてしまったり、機密情報のファイルをLLMに勝手に送信されてしまったりするという問題です。
特に、Open Interpreterの持つコマンドの実行処理の確認をオフにしてしまっている場合、コードの処理を止めることが出来ずに実行されてしまったということが起き得ます。ファイルの削除などは実施の指示出しをしなければ基本的に実行されないはずですが、セキュリティキーなどをLLMに送信したりすることには注意が必要ですね。
2つ目はOpen Interpreter自体をアプリケーションをアプリケーションに組み込む場合、アプリケーションにもAGPLライセンスを付与しなければならないという点です。AGPLライセンスとはオープンソースソフトウェアにおいて、ソースコードの秘匿を禁止しているライセンスです。
このライセンスは複製・改編・再配布・販売など自由に行うことが出来ますが、このライセンスを組み込んで開発した場合、ソースコードを一緒に配布する必要があるというものです。AGPLの派生元ライセンスとしてGPL(GNU General Public License)がありますが、AGPLライセンスではSaaSやWebサービスといった形でもソフトウェアを提供し、利用するだけでもライセンスの効力が発生するという違いがあります。Open Interpreter自体をソフトウェアに組み込む場合はこのライセンスを適応する必要があるということを把握しておきましょう。
RemoteContainer
Visual Studio Code(VS Code)の強力な拡張機能の1つで、開発者がDockerコンテナ内に完全に隔離された開発環境を構築し、その利用も効率化できます。以下のような特徴があります。
- 開発環境の隔離
- コンテナ技術を使用して、プロジェクト固有の依存関係と設定を含む環境を作成します。これにより、環境が他のプロジェクトやローカルシステムの設定に影響を受けることがありません。
- 環境の再現性
- コンテナ化された環境は他の開発者と簡単に共有でき、どのマシンでも同じ設定でプロジェクトを実行できるため、”動かない理由が分からない”という問題を減少させます。基本的にコピペだけで動かすことができます。
- クロスプラットフォーム対応
- Windows, macOS, Linuxなど、異なるオペレーティングシステムにおいても、同様の開発環境を提供します。
- 今回、自分はWindows上で開発環境の構築を行っていますが他のOS上でも動作するはずです
- 柔軟な開発スタイルのサポート
- リモートサーバ(SSH)、コンテナ(Docker)、さらには仮惠机の環境(WSL等)といった複数のリモート環境に対応しています。
さらに、普段からVS Codeを使用している開発者であれば、すべてがコンテナー内で分離されているにも関わらず、すべてがマシン上でローカルに実行されているかのようにVS Codeを操作することが出来ます。
環境構築
環境構築の準備
今回の環境構築に必要なものは以下の3つです。
- VS Code
- VS Codeのダウンロードはこちら
- Docker
- Dockerのダウンロードはこちら(Windows)、Macの方はこちら(Mac)
- OpenAI API Key
- API Keyの取得はこちらから(サインアップ及び支払方法の登録が必要です)
Dockerfile, devcontainer.jsonの構築
まずは、任意のフォルダ内(今回はinterpreterフォルダとします)に.devcontainerフォルダを作成します。
次に, .devcontainer内にDockerfileを準備します。(interpreter/,devcontainer/Dockerfile)Dockerfileには拡張子は不要です。
Dockerコンテナの立ち上げ時にPython3.11とopen-interpreterのインストールを行います。
FROM python:3.11
ENV PYTHONUNBUFFERED 1
RUN pip install open-interpreter
次にdevcontainer.jsonファイルを作成します。OPEN_API_KEYのxxxxxxxxxxxxxxxxxxxxxx部分にAPI Keyをコピーしてください。
name部分がVS Code上でのコンテナの表示名になります。また、拡張機能として、Python関連の機能をインストールしておきます。remoteEnvで環境変数を設定し、Open Interpreterの実行時にChatGPT4が読み込まれるように設定しています。
{
"name": "OpenInterpreterContainer",
"dockerFile": "Dockerfile",
"extensions": [
"ms-python.python"
],
"remoteEnv": {
"OPENAI_API_KEY": "xxxxxxxxxxxxxxxxxxxxxx"
]
}
これで設定は完了です。
VS Codeのサイドバーの拡張機能のアイコン  よりDev Containersで検索し、インストールしましょう。
よりDev Containersで検索し、インストールしましょう。
VS Codeの左下の緑のアイコンを選択すると表示されるメニューよりOpen Folder in Container(日本語化している場合はコンテナーでフォルダを開く)を選択してください。
これでDockerコンテナ環境が立ち上がります。
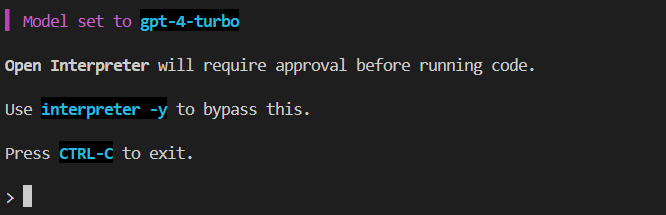
Open Interpreter確認
実行を確認してみましょう。
ターミナルを立ち上げ(Ctrl+Shift+`)て以下を入力してください。
interpreter
Open Interpreterが立ち上がれば成功です。(-yオプションを付けて起動するとコード実行時の確認が省略されます。)
環境構築にあたってこちらの記事を参考にさせて頂きました。
アヤメの分類ができるか試してみる
interpreter -y
アヤメの分類の機械学習の問題をSVMを使用して解いてみてください
実行すると、まず実行計画を立ててどのように作業を進めていくかというのを計画しています。
今回は1.データセットのロード、2.訓練とテストセットの分割、3.モデルのトレーニング、4.モデルの評価、5.結果の出力と5段階の流れで進めていくようです。
まず、データセットのロードではsklearnのデータセットの使用を試みました。が、ModuleNotFoundErrorエラーが発生してしまいました。そこで、自動的にsklearnのインストールを実施、再度ロード処理まで実行してくれました。
次にデータセットの分類とモデルのトレーニング、モデルの評価、結果の出力までは一つのステップで実施し、sklearnを使用したデータセット分割と訓練の実施を行いました。最終的には学習した結果からテストデータの分類結果を表示し応答が終了しました。
SVMモデルを使用したアヤメ(Iris)データセットの分類が非常に成功しました。モデルはすべてのクラスのデータに対して1%の精度(precision)、再現率(recall)、およびF1スコアを達成しています。\n\nこれでアヤメの分類問題は完了です。
ここまで先ほどの1行の指示のみで動いており、1度エラーが発生したのにも関わらず処理を続けてくれるというのが優秀です。理論的にはデータセットさえ準備してしまえば機械学習を自動で進めてくれるということです。(データセットの準備もスクレイピング等でうまくやってくれるかもしれませんが)
OpenInterpreterの使用方法について
使用するモデルを変更する
OpenInterpreterで使用するモデルを変更する場合、起動時にモデルパラメータを使用できます。使用できるモデルはこちらから検索できます。
interpreter --model gpt-3.5-turbo
デバッグモードの有効化
デバッグモードを有効化すると通常時では分かりにくい「アシスタントの出力」と「コンピュータからの応答」などをroleを持った形で出力してくれます。
interpreter --verbose
また、会話の応答待ち中に以下のコマンドを実行することでもデバッグモードを有効化できます。
%verbose true
その他にもOpenInterpreterにはいくつかのコマンドが設定されているのでご紹介します。
対話モードでのコマンド
%verbose [true/false]- デバッグモードに切り替えます。引数なしでもデバッグモードに入ります。
falseでデバッグモードを終了します。
- デバッグモードに切り替えます。引数なしでもデバッグモードに入ります。
%reset- 現在のセッションの会話状況を消去します。
%undo- 履歴から一つ前のユーザーメッセージと それに対するAI の応答を削除します。
%save_message [path]- メッセージを指定したパスに保存します。パスが指定されていない場合、デフォルトは
messages.jsonになります。xxxと指定するとxxx.jsonというファイル名で保存されます。
- メッセージを指定したパスに保存します。パスが指定されていない場合、デフォルトは
%load_message [path]- 指定した JSON パスからメッセージを読み込みます。パスが指定されていない場合、デフォルトは
messages.jsonになります。
- 指定した JSON パスからメッセージを読み込みます。パスが指定されていない場合、デフォルトは
%help- ヘルプメッセージを表示します
%tokens [prompt]- 実験的な機能として次のプロンプトで使用されるトークンを計算し、そのコストを計算してくれます。
まとめ
今回の記事では、OpenInterpreterを使用するための仮想環境をVSCodeのRemoteContainerを使用して準備してみました。また、実装した環境を用いて機械学習の分類問題を解いたり、OpenInterpreterの使用法についてご紹介させていただきました。
エクスチュアはマーケティングテクノロジーを実践的に利用することで企業のマーケティング活動を支援しています。
ツールの活用にお困りの方はお気軽にお問い合わせください。