
こんにちは、喜田です。本投稿は Snowflake Advent Calendar 2023 の8日目の記事です。
私が所属するエクスチュア株式会社では、今年お取引のあったお客様、パートナー様への感謝を込めて12/7にイヤーエンドパーティを開催させていただきました。私も多くのお客様に良くしていただき、支えられながら、日々精進させていただきました。
この投稿で扱うSnowflakeもデータクリーンルーム(DCR)も、お客様たってのご希望があり、そして社の先人たちが築いてきた信頼があったからこそ、新しい製品でのチャレンジをお任せいただけたということで、私の1年間も本当に感謝とご縁にあふれていたなとしみじみ思います。
Snowflakeで作る「DCRごっこ」
さて、そんな年末の一大イベントを彩るお楽しみ企画として、ITジョーク的な、テッキーな面白さを取り入れたことをやりたいね~という会話があり、ここ1カ月ほどゲームの検討や実装をやってきました。簡単に言うと、会社の忘年会や結婚式2次会でありがちな「チーム対抗クイズ大会」ではあるのですが、そこに技術要素を思いつく限りいれてみました。
名付けて Let’s pretend to be DCR ! (DCRごっこしようよ!)
※Let’s pretend to be a Shopperなら「お店屋さんごっこ」、Prinsessなら「お姫様ごっこ」
子供のごっこ遊びをこういうらしいです。3歳♀2歳♀のパパは日々学んでおります。
ゲームデザイン
クイズ大会といえば、バーンと優勝者を発表して景品をお渡ししたりしますよね。

このクイズ優勝者の発表、もしかしたらお忍びでいらっしゃっている有名人かもしれないし、競合他社に関係性がバレるといけないお客様かもしれないし、プライバシー重視が叫ばれる昨今、お名前を出す必要ないのでは?(大袈裟)
という趣旨のもと、
- チーム対抗とする
- 優勝チームを決めてチームを表彰する
- チーム分けや採点のロジックを明確に、プライバシー配慮された形にする
といったおふざけ企画を社長に提案したところ、「ククク、面白そうじゃん」と言ってもらえたので割と本気の開発がスタートしました。
回答~格納のデータの流れ
ポイントはSnowflakeのデータクリーンルームを使うこと、せっかくなので現実にありえそうな機密情報を持ち合うイメージで3つのパーティーが登場するシナリオを考えました。
Snowflakeのデータクリーンルームについては本ブログでも何度か記載しています。Snowflake独自のデータシェアリングの応用として、テーブル全体を無条件に公開するのではなく、許可した相手にのみ、集計や結合によって得られる結果だけを返す機能です。言葉だけだと少し難しいですが、集計関数や特定テーブル同士を結合するSQLを強制し、それ以外のSQL実行を許さないと言い換えることもできます。
今回は参加者の回答をSnowflakeに格納しますが、シナリオに沿って回答データを分割して保管します。それぞれのパーティが機密扱いとするデータを作り、でも、それらをJOINするとチーム単位での得点がわかり、優勝チームを決めることができるというものにしました。
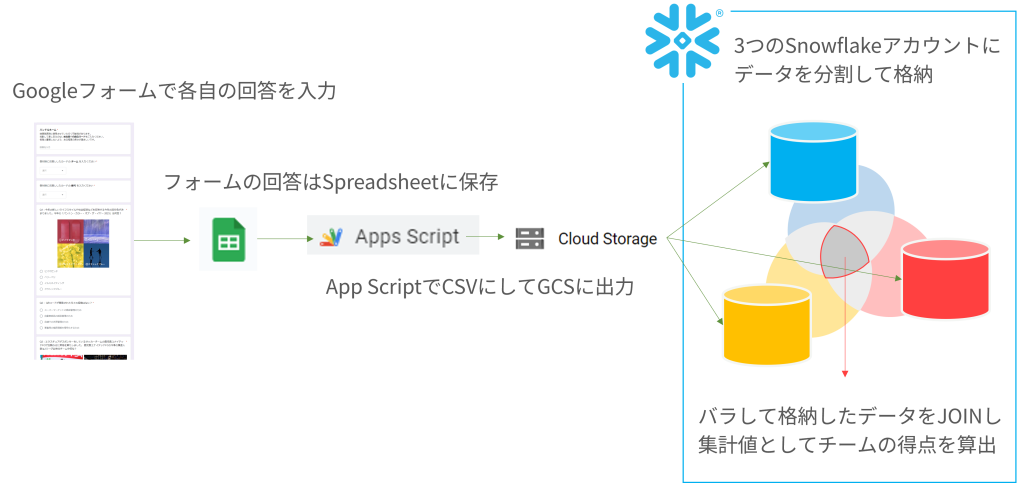
パーティの参加者100名ほどだったのですが、Googleフォームでクイズを出題し、みなさんにスマホから回答いただきます。この時、
- ハンドルネーム(個人の特定用、プライバシー配慮で流出してはいけない文字列)
- 受け付けでランダムに配ったチームカードに書かれたチーム名(集計単位)
を回答とあわせて送信してもらうようフォームを作成しました。
これをCSVファイルにしてSnowflakeにロードします。SnowflakeではGCS上のファイルを読みにいく「外部ステージ」を用意しておき、以下のように取り込みました。
Googleフォームに集められた回答は、1人の回答者の回答がぜんぶ横に並ぶ形になるので、あとで他のテーブルとJOINしやすいように縦持ちのデータにして取り込みます。SQLで言うとPIVOT/UNPIVOTで行いますが、今回は裏技的な方法で。
INSERT INTO answer SELECT $1,1,$4 FROM @bucket/answer.csv;
INSERT INTO answer SELECT $1,2,$5 FROM @bucket/answer.csv;
回答のCSVファイルは、1列目がハンドルネーム、2,3列目がチーム分け、4列目がQ1の回答、5列目がQ2の回答・・・となっています。@付きのFROM句で外部ステージ上のCSVファイルを直接読みにいくことができますので、$1でハンドルネーム、1,2と数字を入れているのは問題ID、$4や$5はそれぞれ4列目(Q1回答)5列目(Q2回答)の値を読んでINSERTするようにしました。10回INSERT文を流せば、10問の全員の回答がデータベースに格納されます。
一方、パーティCには参加者のチーム分け情報を格納します。上記とほぼ同じ方法ですが、ハンドルネーム を一意にして取り込むようにしました。
INSERT INTO team_member SELECT distinct($1),$2,$3 FROM @bucket/answer.csv
$1はハンドルネームをdistinctを付けて一意に、$2,$3はその人が属するチームとチーム内での通し番号です。
図の黄色で記載したデータベースにはクイズ問題と正解の選択肢を格納するクイズ問題マスタ的なデータをあらかじめいれてあります。
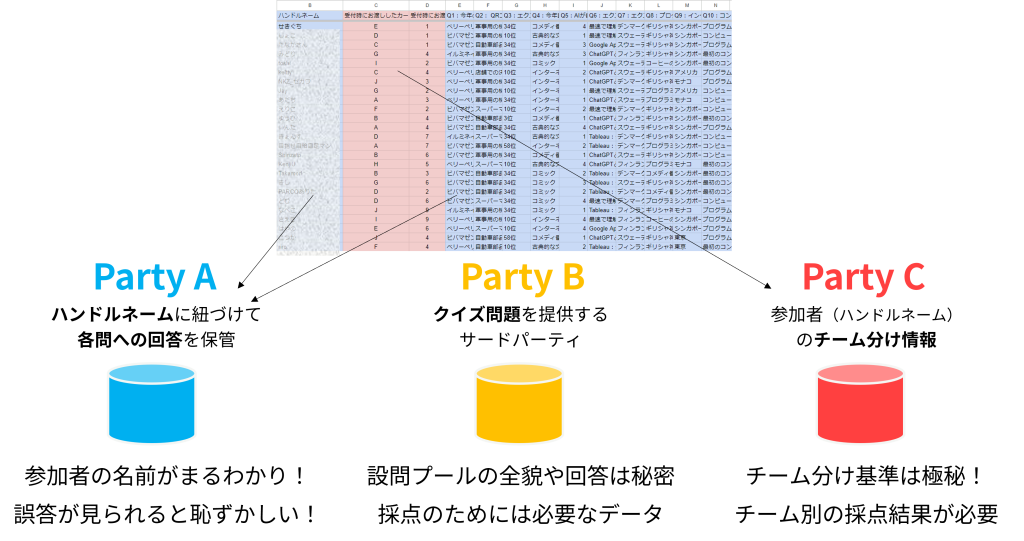
機密情報を扱う3つのパーティ
このシナリオはごっこ遊びでありながら、ちゃんと機密情報チックなデータを3つのパーティに分けて格納しており、それぞれ相手に見せないように、でも必要な結果を得ることを考えています。
パーティA:皆さんの回答
個人が何を回答したかは公開されません。参加者情報(今回はハンドルネームを使いましたが、これは通常メールアドレスだったり、自社が保有する顧客IDであり非公開です。)と、各々が何と回答したかがとれています。
👀ここでは神様の視点で、各パーティにどんなデータが入っていたかこっそり覗いちゃいます。
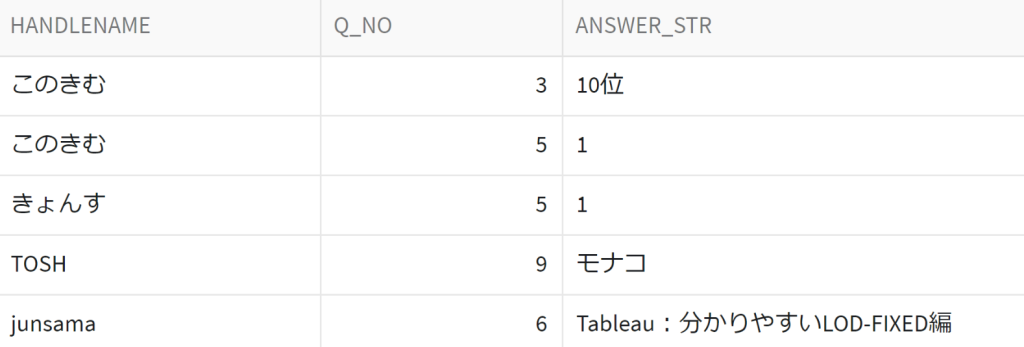
誰が、どのQに対して、何と回答したがか格納されています。
パーティB:クイズ出題マスタ
今回は10問のクイズ企画にしましたが、データビジネスの最前線をいく架空のエンタメデータ集団「くいずやさん」が膨大な問題プールを持っていて、この出題マスタ表にはたくさんの問題とその答えが格納されています。データ販売を生業とするサードパーティ事業者です。

今回は10問いくらの課金して問題を購入した、という設定ですね。問題プールの全容や、その正解が流出することは彼らのビジネスの根幹に関わることで、これは個人情報こそ含まないもののビジネス上の重要な機密情報です。
ただし、今回の出題した10問に関しては、正解を明かすか、どうにか採点ロジックを提供しないことには採点ができません。パーティAが集めた回答データには顧客の個人情報(=ハンドルネーム)が含まれており、パーティBにそれを丸ごと預けて採点業務を委託することは難しいです。
これをどうすれば解決できるでしょうか。
パーティA×パーティB:個々人の回答を採点する
パーティAからクエリ実行することを考えます。パーティBのデータはAに対して「シェア」しますが、なんでもクエリを許すわけではありません。今回の参加者の回答をJOINし、採点するためのSQLのみ実行を許可します。
SELECT handlename,
a.q_no,
answer_str,
correct_answer,
CASE a.answer_str WHEN q.correct_answer THEN 10 ELSE 0 END AS score
FROM answer AS a
JOIN from_qa_mst.public.qa_pool AS q ON a.q_no = q.q_no
;
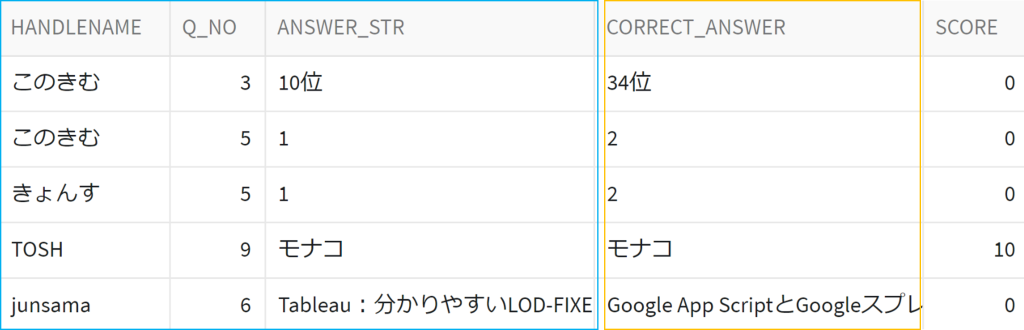
両パーティのデータをJOINすることで、採点ができます。
ただしこれではくいずやさんのビジネスの根幹である正解データが流出してしまっていますね。このクエリは実は許可されていません。この回答をさらにGROUP BY handlename すると以下のようになります。
SELECT handlename,
sum(CASE a.answer_str WHEN q.correct_answer THEN 10 ELSE 0 END) AS score
FROM answer AS a
JOIN from_qa_mst.public.qa_pool AS q ON a.q_no = q.q_no
GROUP BY handlename
;
この許可済みの集計クエリによってのみ、くいずやさんのデータを引き出し、採点することができます。
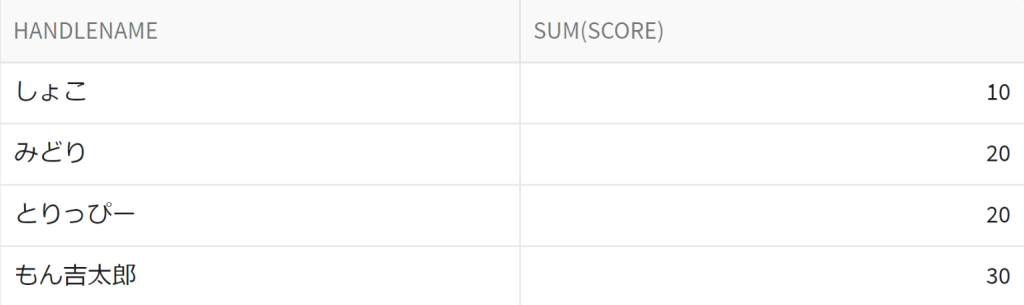
パーティAでクエリし、パーティBのデータを使った採点が行われ、個人の獲得点数が得られました。パーティBが保有する問題データ、設問の回答はここからは読み取ることはできないですが、個人の獲得点数は得られたわけです。
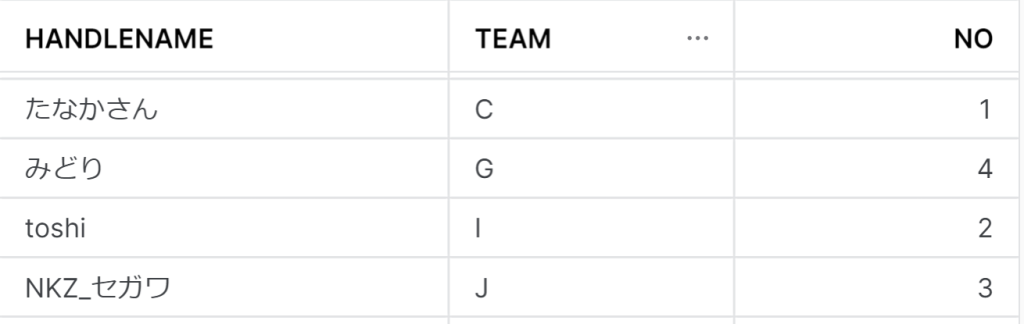
パーティC:営業部隊の日々の活動の結晶、チーム分けデータ
このイベントでは100人の参加者を完全にランダムなカード配布という形でチーム分けしたのですが、実際のお仕事ではチーム分け=顧客の属性付けです。
あるお客様はxxxの製品の購入歴あり、ある個人はxxxな嗜好、場合によってはそれはAI/MLによって得られた自社顧客の特徴であり、そこには適切な分類のための多大なる努力が隠されています。誰がどのクラスタに属するのか、どんな風にクラスタ分けしているのか、これこそ企業にとっての価値あるデータというわけです。簡単に社外に公開するわけにはいきません。
データとしては単純でこれだけのものです。
A×B×C:機密情報を隠して優勝チームを特定せよ!
再掲ですが、A×Bで得られた個人の得点。
これはイベントとしてはまだ非公開データです。なぜかというと、チーム対抗なのに個人の得点がバレバレだと、「おい、お前!足引っ張ってんじゃねーよ!」みたいなことになりかねません。笑
これをチームの合計点にすることでみんなHappy!3者3様の機密情報を隠しながら、イベントの目的であるチーム得点を計算し、優勝チームを特定することができます。
SELECT team,
sum(case a.answer_str WHEN q.correct_answer THEN 10 ELSE 0 END ) AS team_score_sum,
count(distinct t.handlename) AS member_cnt,
(team_score_sum / member_cnt)::integer AS avg_team_score
FROM from_csv_answer.public.answer AS a
JOIN from_qa_mst.public.qa_pool AS q ON a.q_no = q.q_no
JOIN team_member AS t ON t.handlename = a.handlename
GROUP BY team
ちなみに、3つのパーティのデータを使うので、シェアの向きが最初のSQL例と変わっています。パーティCでクエリ実行、パーティAからC、BからCにそれぞれシェアしています。Snowflakeのデータシェアリングは、シェアされてきたものをさらに別の相手にシェアすることはできませんのでこのように向きを変えています。
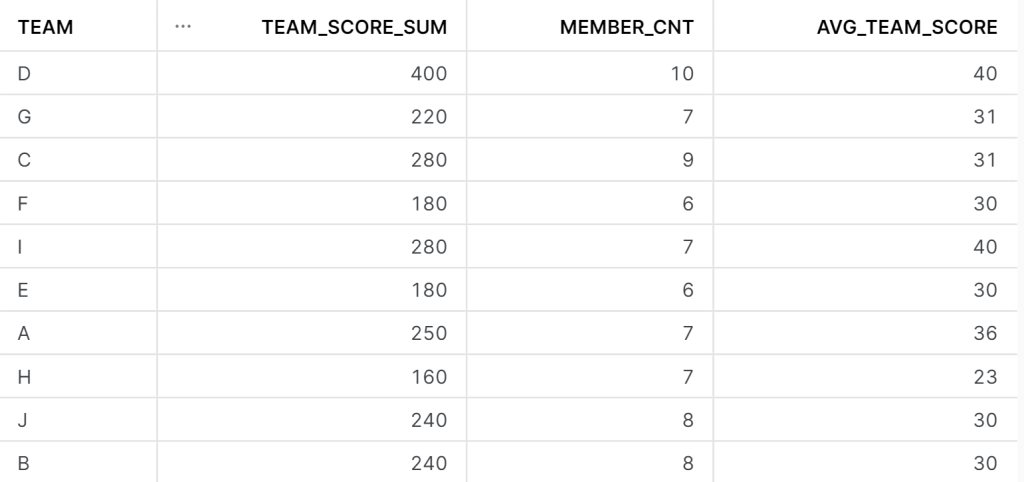
個人情報であるハンドルネームを隠し、誰がどのチームにいるかを隠し、クイズの設問と解答を隠し、でもきちんと採点がされ、チームの合計点数がわかり、優勝チームを決定することができます。
みんなHappy!
結果発表!!!
さて、パーティのお楽しみ企画として、結果発表ではみなさんの目を引くものでないといけません。
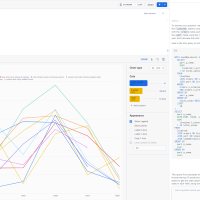
↑の集計データをバーンと公開してもパッと見どこが優勝かわからないですよね。というわけで・・・
Steamlit in Snowflake!使っちゃいました。(実は初めて触った。Pythonド初心者が2時間ぐらいでサクッと可視化できました)
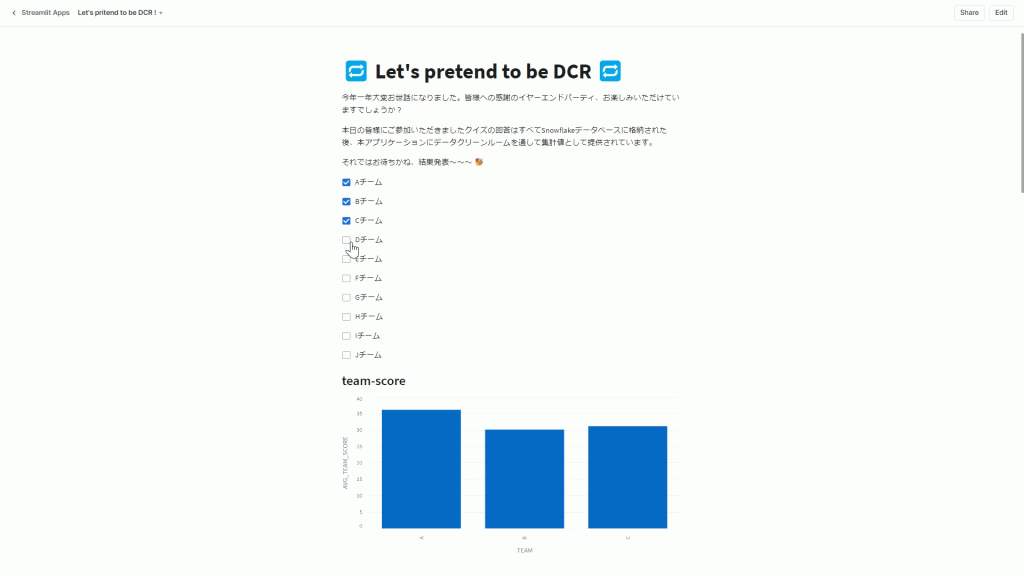
チェックを入れたチームの得点が集計され、その場でグラフに反映されるようにして結果発表を行い、大いに盛り上がることができました!!!
終わりに
アドベントカレンダーで本記事を目にしていただくであろうSnowflake界隈のみなさま、今年一年大変お世話になりました。Snowflake初めて、データクリーンルームの概念から初めて勉強したのが3月ごろ。それがお客様先での構築案件を経て、6月のSnowflakeサミットでDCRに興味があるという話から多くの方との意見交換につながり、ついにはTeam Data Clean Roomの立ち上げまでやらせていただきました。
まだまだ概念や必要性、ユースケースが世に出回っていないという点が、この素晴らしい技術の足かせになってしまっている部分が非常にもったいなく感じていて、企業の枠を超えて技術ノウハウや事例を蓄積していくことが重要と考えコミュニティの発足を提案したという背景があります。
私は日々DCR漬けというぐらい、どういうデータでこういうやりとりできそうと、テレビCMを見るたび、買い物するたび、新しめのウェブサービスを見るたび日常の中でも妄想しています。そういった中で身近に想像つくデータでDCRでできることを体験する「模擬DCR」は何かしらの形でやってみたいと思っており、今回絶好の機会でお披露目することができました。DCRというキーワードが少なくとも100名ほどのお客様に認知してもらい、そして面白おかしく盛り上がれたのも良かったです。
忘年会イベントで「DCRごっこ」おススメです!!!笑









この記事へのコメントはありません。