AdobeAnalytics Datafeed: BigQueryのSIGN関数を使った小ワザ

こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
今回もあまり需要はないけど知ってたら役に立つDatafeed + BigQuery用の小ワザです。
- トラフィック変数にCVを紐付ける
- セグメントを作る
これらはいずれもSIGN関数の使い方を覚えると簡単にSQLを書けます。
SIGN関数 | 標準 SQL 関数と演算子 | BigQuery | Google Cloud
使い方を以下のケースで説明します。
1. トラフィック変数にCVを紐付ける
propなどのトラフィック変数で計測してる値をeVarみたいに最後の値にCVを紐付けたいけど、今からAA実装直したんじゃ遅い!という事が人生で何度かおきました。
私が過去にやった例だと、s.channelの値をeVarに入れ忘れ(以下略)
トラフィック変数に対するCV紐付け方法として、パーティシペーション指標を使う方法があります。
これを使えばセッションまたはレポート期間中において発生したすべてのprop値にCVが紐付きます。
しかし、propに対して「最初の値」か「最後の値」にCVを紐付けたい場合はパーティシペーションは有効ではありません。
そんな時にはササっとお手軽にSQLで抽出する方法を覚えておくと人生がラクになります(当社比)
i. propの最後の値(直近)にCVを紐付けるSQL
WITH t1 AS (
SELECT
CONCAT(post_visid_high, post_visid_low, CAST(visit_num AS string)) AS sid,
hit_time_gmt,
post_channel AS channel,
SIGN(SUM(CASE WHEN CONCAT(',', post_event_list, ',') LIKE '%,1,%' THEN 1
ELSE 0 END)
OVER(PARTITION BY CONCAT(post_visid_high, post_visid_low, CAST(visit_num AS string))
ORDER BY hit_time_gmt DESC ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW)) AS cvflag
FROM exture.hit_data
WHERE
DATE(hit_time_gmt, 'Asia/Tokyo') >= "2019-11-01"
AND DATE(hit_time_gmt, 'Asia/Tokyo') < "2019-12-01"
AND post_channel IS NOT NULL
AND exclude_hit = 0
AND duplicate_purchase = 0
),
t2 AS (
SELECT
sid,
hit_time_gmt,
channel,
ROW_NUMBER() OVER(PARTITION BY sid ORDER BY hit_time_gmt DESC) AS rownum,
cvflag
FROM t1
WHERE cvflag = 1
)
SELECT
channel,
SUM(cvflag) AS cv_last
FROM t2
WHERE rownum = 1
GROUP BY 1
ORDER BY 2 DESC
解説:
最初のCTE t1 では、同一セッション内でコンバージョンイベントが発生したよりも前のヒットを絞り込みます。
SIGN関数を使って同一セッションのヒットに「1」というフラグを立てて行きます。
なお、OVER句において
ORDER BY hit_time_gmt DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
を使う事で、CVが発生したヒットよりも前のヒットに対してパーティションを作成してます。
それらの行にSIGN関数でCVの合計数を渡すことで、CVが1件以上あれば「1」を、CVがなければ「0」を返します。
その後、CTE t2においてセッション内のヒットをDESCで降順にソートして、行番号であるrownumberカラムを生成します。
そして最後のクエリでrownumberが「1」の値(=CVより前にヒットした最後のs.channelの値)に対して、CV数が出てくるという仕組みです。
ii. propの最初の値(元の値)にCVを紐付けるSQL
WITH t1 AS (
SELECT
CONCAT(post_visid_high, post_visid_low, CAST(visit_num AS string)) AS sid,
hit_time_gmt,
post_channel AS channel,
SIGN(SUM(CASE WHEN CONCAT(',', post_event_list, ',') LIKE '%,1,%' THEN 1
ELSE 0 END)
OVER(PARTITION BY CONCAT(post_visid_high, post_visid_low, CAST(visit_num AS string))
ORDER BY hit_time_gmt DESC ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW)) AS cvflag
FROM exture.hit_data
WHERE
DATE(hit_time_gmt, 'Asia/Tokyo') >= "2019-11-01"
AND DATE(hit_time_gmt, 'Asia/Tokyo') < "2019-12-01"
AND post_channel IS NOT NULL
AND exclude_hit = 0
AND duplicate_purchase = 0
),
t2 AS (
SELECT
sid,
hit_time_gmt,
channel,
ROW_NUMBER() OVER(PARTITION BY sid ORDER BY hit_time_gmt ASC) AS rownum,
cvflag
FROM t1
WHERE cvflag = 1
)
SELECT
channel,
SUM(cvflag) AS cv_first
FROM t2
WHERE rownum = 1
GROUP BY 1
ORDER BY 2 DESC
解説:
CTE t1 は「最後の値」と同じです。
CTE t2においてセッション内のヒットを昇順ソートしているのが違いです。
※分かりやすくするためにASCを明示的に入れてますが、なくてもOKです。
そして最後のクエリでrownumberが「1」の値(=CVより前にヒットした最初のs.channelの値)に対して、CV数が出てくるという仕組みです。
2. セグメントを作る
条件に一致したヒット・訪問・訪問者別にコンテナを作成し、該当するデータだけにフォーカスするのがAdobeAnalyticsにおける「セグメント」です。
SIGN関数を使えば、条件に一致するヒット・訪問・訪問者に対してフラグを簡単に立てられます。
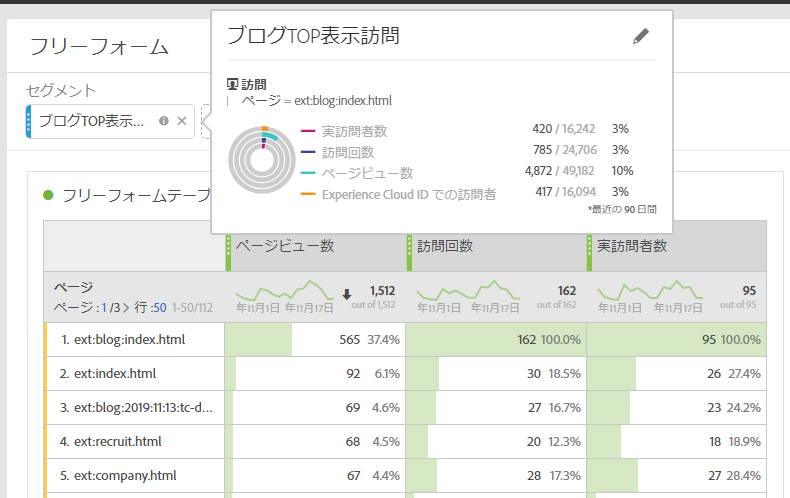
例えば「弊社ブログTOPページを表示した訪問」というセグメントを定義して、セグメントに一致するトラフィックを集計するならばこう書けます。
WITH t1 AS (
SELECT
CONCAT(post_visid_high, post_visid_low, CAST(visit_num AS string)) AS sid,
CONCAT(post_visid_high, post_visid_low) AS vid,
hit_time_gmt,
post_pagename AS pagename,
SIGN(SUM(CASE WHEN post_pagename = 'ext:blog:index.html' THEN 1
ELSE 0 END)
OVER(PARTITION BY CONCAT(post_visid_high, post_visid_low, CAST(visit_num AS string))
ORDER BY hit_time_gmt ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING)) AS flag
FROM exture.hit_data
WHERE
DATE(hit_time_gmt, 'Asia/Tokyo') >= "2019-11-01"
AND DATE(hit_time_gmt, 'Asia/Tokyo') < "2019-12-01"
AND post_page_event = 0
AND exclude_hit = 0
AND duplicate_purchase = 0
)
SELECT
pagename,
count(1) as pv,
count(distinct sid) as visits,
count(distinct vid) as visitors
FROM t1
WHERE flag = 1
GROUP BY 1
ORDER BY 2 DESC
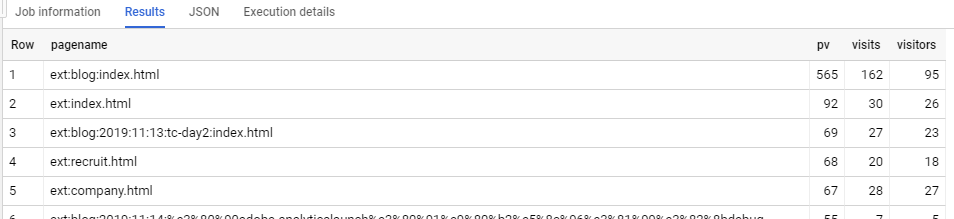
解説:
CTE t1 でSIGN関数を使うのは同じですが、OVER句の中で ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING を使うのが特徴です。
これによって、条件に一致した訪問の「最初から最後まで」の行が対象になります。
そして最後に flag=1 の行だけを抽出すれば、セグメントに一致したデータを抽出出来ます。
また、「順次セグメント」のように「~より前」(BEFORE) という定義にしたい場合は
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
という書き方をすれば条件に一致するより前のデータだけが対象になり、逆に「~よりも後」(THEN)という定義ならば
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
という書き方でスコープを狭める事が出来ます。
まとめ
SIGN関数を使って「該当するセッション内のヒットにフラグを立てる」手法はAdobeAnalyticsの「セグメント」を再現する時に私は頻繁に使ってます。
このテクニックはGoogleAnalytics360 または Apps+Web PropertyのデータをBigQueryで分析する時にも使えるので、使い方を覚えておきましょう。
弊社では、Google Cloud認定データエンジニア資格とAdobe認定エキスパート資格を保持した技術者達によるデータ分析基盤構築業務を承っております。
お問い合わせはこちらからどうぞ。