Databricks: Spark DataFrameでピボットグラフを作る

こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
今回はDatabricksにおける、Spark DataFrameのピボット機能を使った集計方法についてです。
DataFrameを作成する
まずはサンプルデータでDataFrameを作成します。
公開データのPopular Baby NamesのCSVを使います。
このデータは、「ニューヨーク市で生まれた新生児の名前」を出生年別・人種別・性別でまとめたパブリックデータです。
Databricksにデータをアップロードしてから、下記のコードでDataFrameを作成します。
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
val myschema = StructType(
Array(
StructField("Year of Birth", IntegerType, true),
StructField("Gender", StringType, true),
StructField("Ethnicity", StringType, true),
StructField("Child's First Name", StringType, true),
StructField("Count", IntegerType, true),
StructField("Rank", IntegerType, true)
)
)
val babyname = spark.read.option("header", true)
.schema(myschema)
.csv("/FileStore/tables/Popular_Baby_Names.csv")
dispaly(babyname)
DataFrameの中身が表示されました。
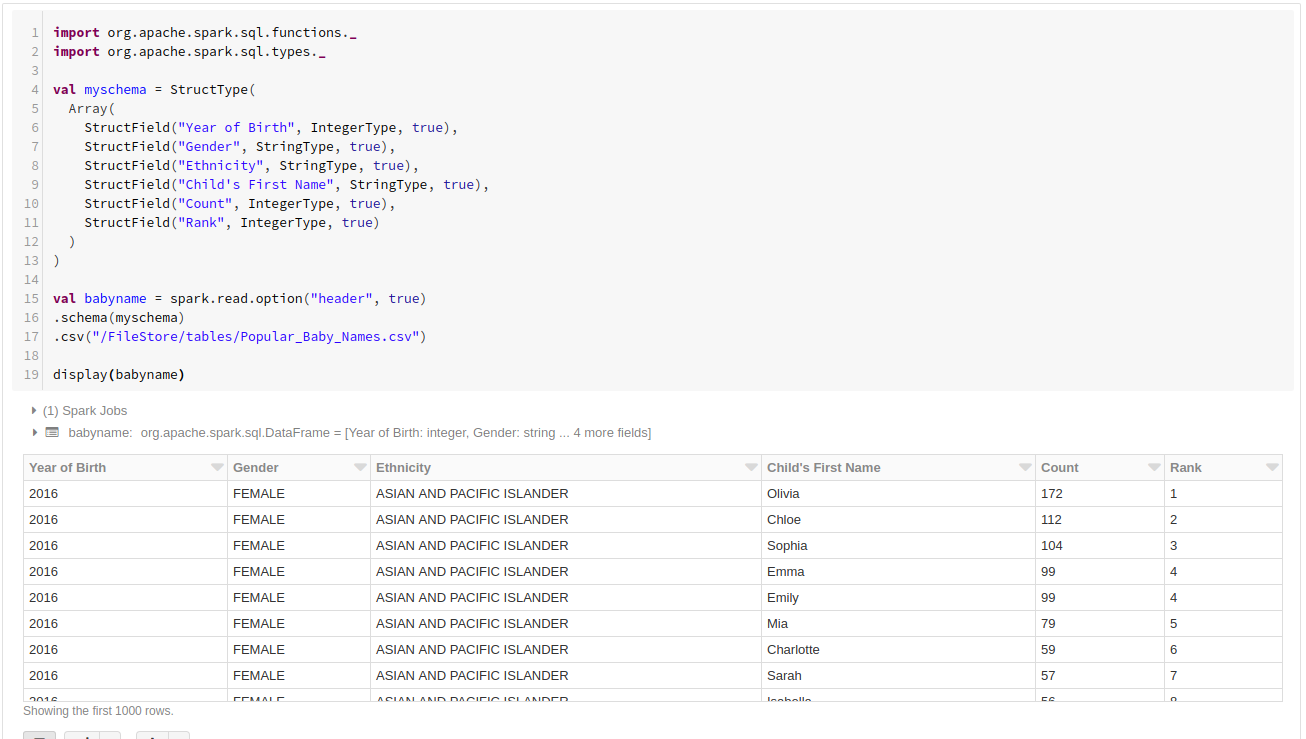
このデータを使って、
2013年〜2016年に生まれた「男の子」の名前でピボットを作ります。
pivotメソッドでピボットテーブル化
ピボットテーブルを作るにはその名もズバリpivotメソッドを使います。
groupByのあとに、さらに軸にしたいカラムをpivotで指定します。
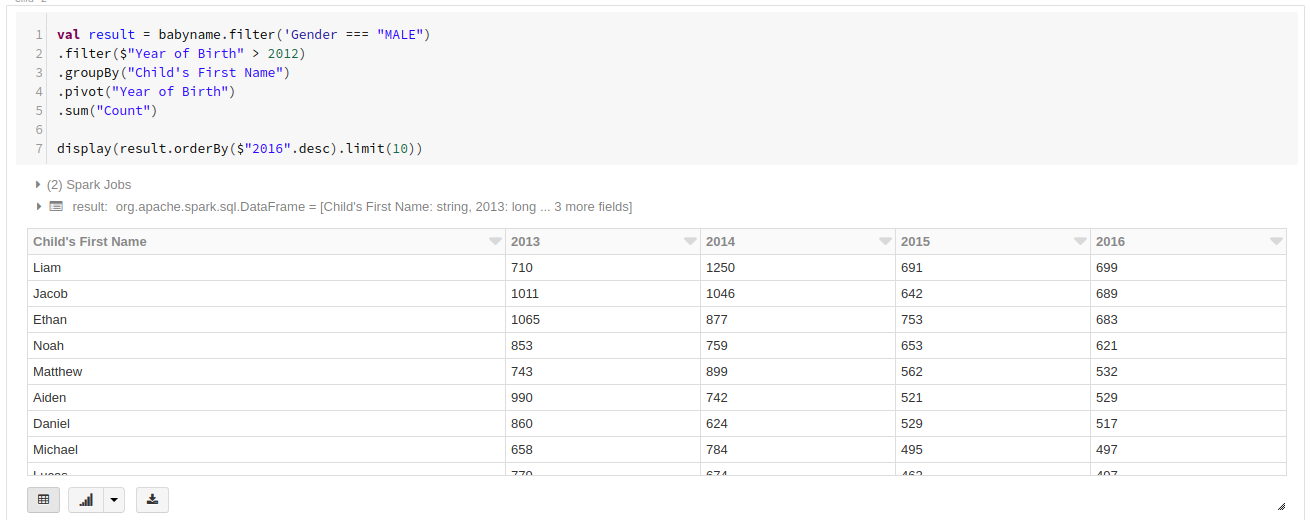
val result = babyname.filter('Gender === "MALE")
.filter($"Year of Birth" > 2012)
.groupBy("Child's First Name")
.pivot("Year of Birth")
.sum("Count")
display(result.orderBy($"2016".desc).limit(10))
2016年の出生数を降順でソートしてトップ10だけを表示してます。
ピボットグラフを作成する
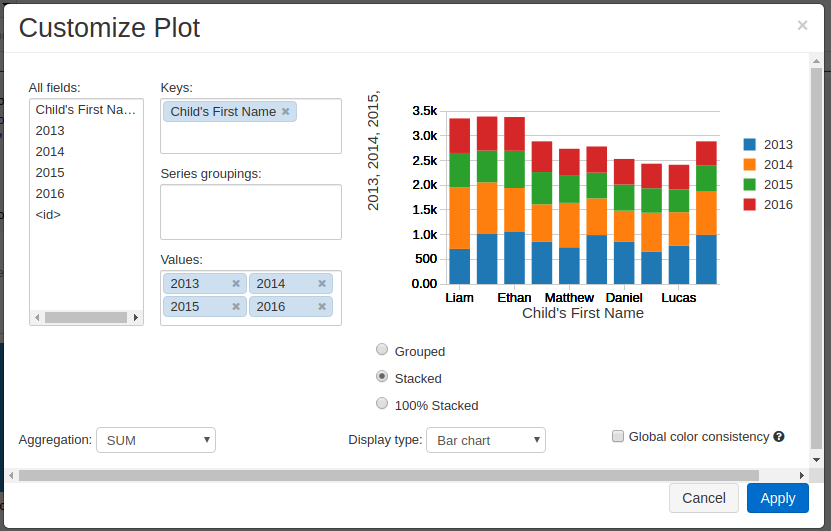
最後にテーブルをグラフ化します。
グラフボタンを押して「Bar」を選んだ後、「Plot Option」を開いて下記のように設定します。
Keys: Child’s First Name
Value: 2013, 2014, 2015, 2016
Display type: Stacked Bar chart
Applyをクリックすると、グラフが描画されて完成です。
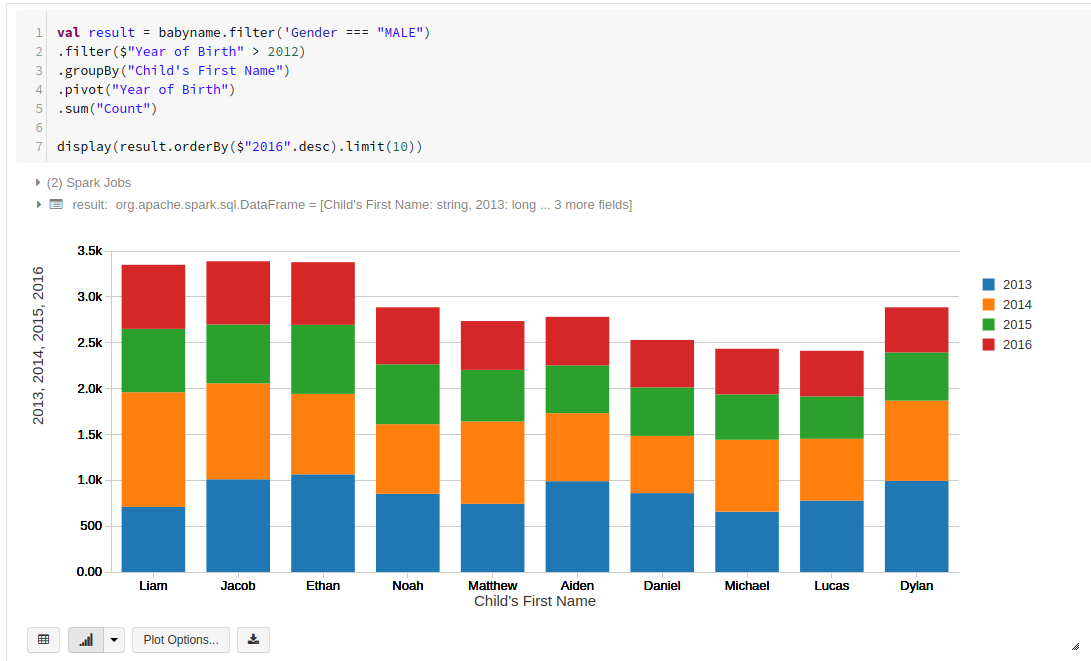
Databricksを使えば、ETLから可視化までをScala/Pythonで一貫して作業出来るのでメソッドさえ覚えてしまえばとてもスムーズな分析が可能です。
弊社はデジタルマーケティングからビッグデータ分析まで幅広くこなすデータ分析のプロ集団です。
Databricksのコンサルティング/導入支援についてのお問合わせはこちらからどうぞ。
ブログへの記事リクエストはこちらまでどうぞ。


