ScalaでDatabricksのDataFrameを扱う

こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
今回はScala言語でのDatabricksのDataFrameの使い方を紹介します。
DataFrameとは
DataFrameとは、Spark上でデータファイルをデータベーステーブルのようにして扱うためのオブジェクトです。
DataFrameにはfilterやjoinなどのメソッドが用意されており、これらを扱うためのAPIがDataFrame APIです。
以前の記事ではSparkのRDD(Resilient Distributed Datasets)というコレクションを使ってデータを操作しました。
DataFrameはRDDよりも強力で便利な機能が備わってるので、ぜひ覚えましょう。
DatabricksのサイトにはDataFrameのチュートリアルが載ってます。
DataFrames – Getting Started with Apache Spark on Databricks
しかし例として掲載されてるサンプルコードがPythonとSQLで記述されていて気に入らないのでw、ここはScalaで書き直します。
データファイルをロードする
Databricksにはチュートリアル用のサンプルデータ*が用意されてます。
このCSVファイルをロードして、DataFrameを作成します。
*アメリカの州別の人口と住宅価格の比較データです。
空のScalaノートブックを作成して、下記のScalaプログラムを実行します。
//サンプルデータ val fileLocation = "/databricks-datasets/samples/population-vs-price/data_geo.csv" val fileType = "csv" val data = spark.read.format(fileType) .option("header", "true") //一行目はヘッダ .option("inferSchema", "true") //スキーマは自動推測 .load(fileLocation) val datac = data.cache() //キャッシュしとく val df = datac.na.drop() //全てがnullの行はドロップ
DataFrameの中身を確認する
dfという名前のDataFrameを作成したので、この中身をtakeメソッドで確認します。
takeの引数で、表示する行数を指定する事が出来ます。
df.take(10) //先頭10行を取得
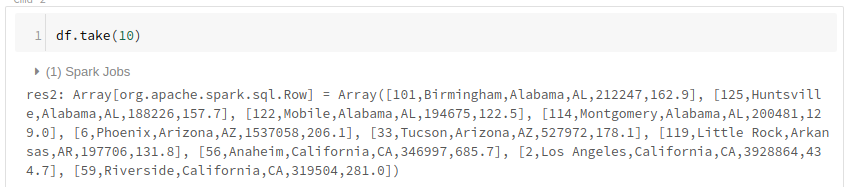
中身が見えたのですが、Array型の配列データなので見づらい。。
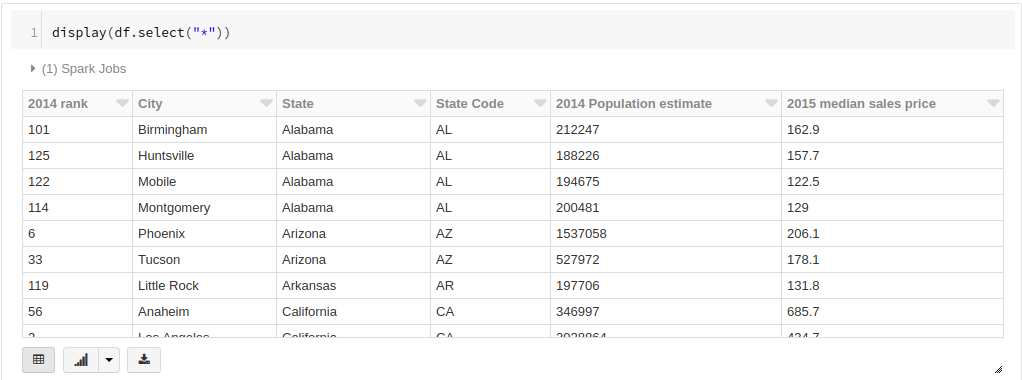
というわけで、今度はdisplayメソッドを使って、これを表形式に整形します。
display(df.select("*"))
DataFrameからデータを抽出する
CSVファイルからDataFrameを生成する事が出来たので、今度はselectメソッドを使ってデータを抽出します。
試しに、[State Code]カラムと[2015 median sales price]カラムを抽出します。*
*アメリカの州コードと、2015年の住宅価格中央値
display(df.select("State Code", "2015 median sales price"))
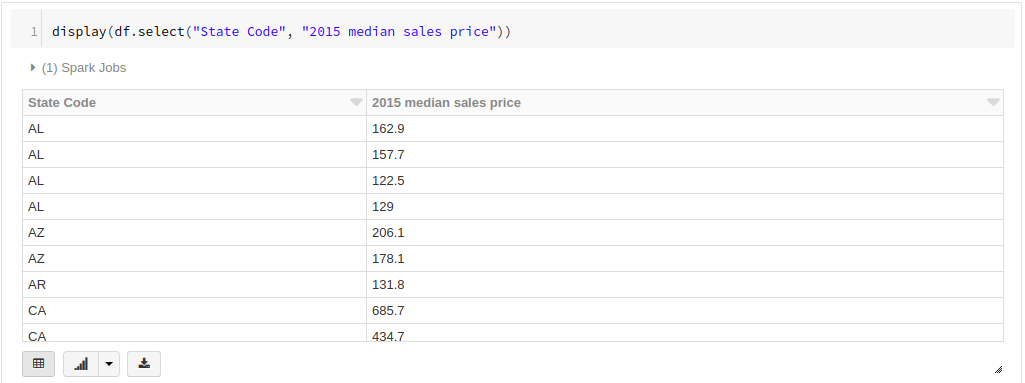
SQLのような感覚でデータを抽出できました。
データを条件で絞り込みたい場合はfilterメソッドを使います。
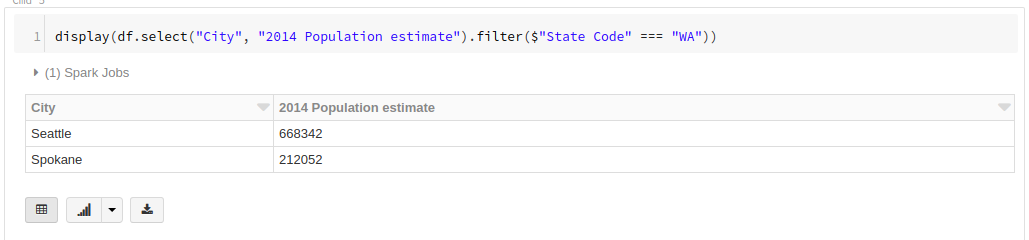
[City]カラムと[2014 Population estimate]カラムを抽出して、ワシントン州([State Code]が「WA」に等しい)という条件でデータを絞り込みます。
display(df.select("City", "2014 Population estimate").filter($"State Code" === "WA"))
DataFrameをグラフ化する
DataFrameのdisplayメソッドを使って表形式でデータを表示する事が出来ましたが、他にも様々なビジュアライズオプションを使ってグラフ化する事が出来ます。
では、さらに新しいデータを抽出します。
[City] カラムをディメンションとして、[2014 Population estimate]と[2015 median sales price]を指標として並べて、これを円グラフにします。
下記のScala文でまずは表形式のデータを表示します。
ここでは、orderByとdescを使ってデータを降順でソートしています。
display(df.select("City", "2014 Population estimate", "2015 median sales price")
.orderBy($"2015 median sales price".desc).take(10)) //降順でソートして先頭10行を取得
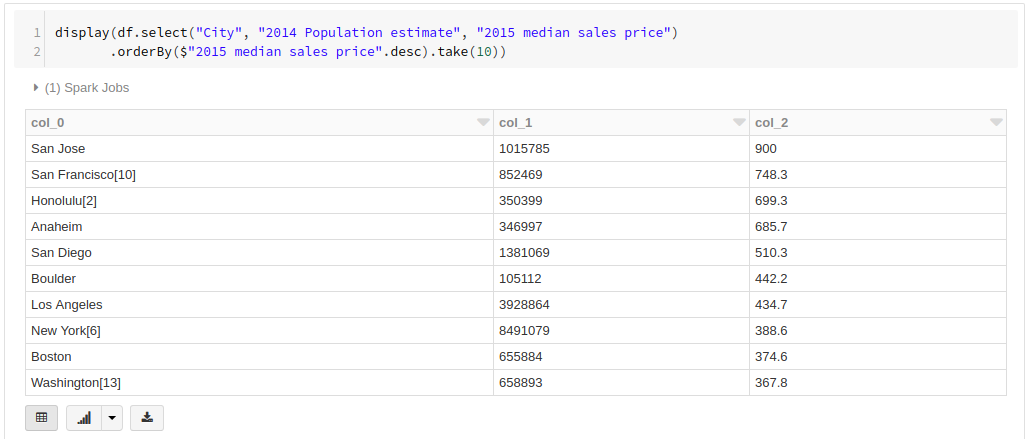
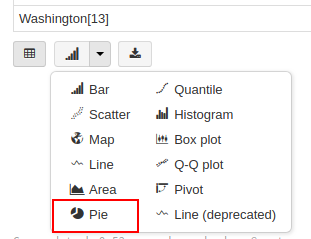
抽出結果の表の下に、ビジュアライズオプションのボタンが表示されています。
この中から、[Pie]を選びます。
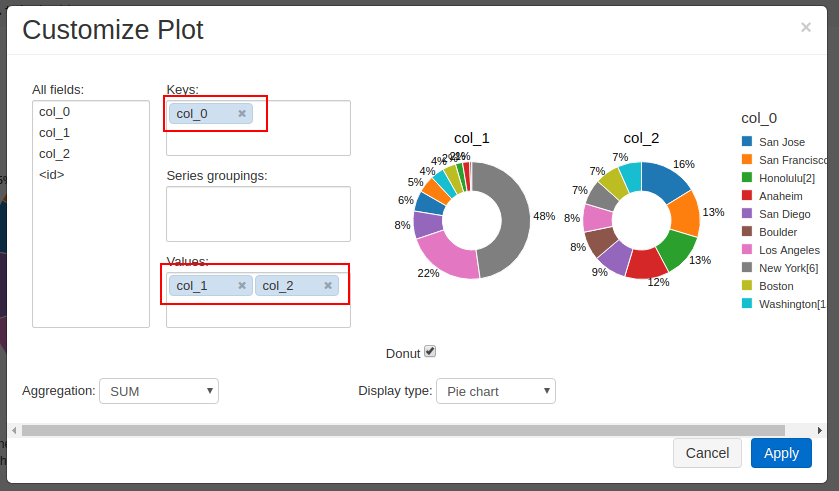
デフォルトでは円グラフが1個しか描画されないので、[Plot Options]を開いて下記のように並べます。
Keys:[City]
Values: [2014 Population estimate], [2015 median sales price]
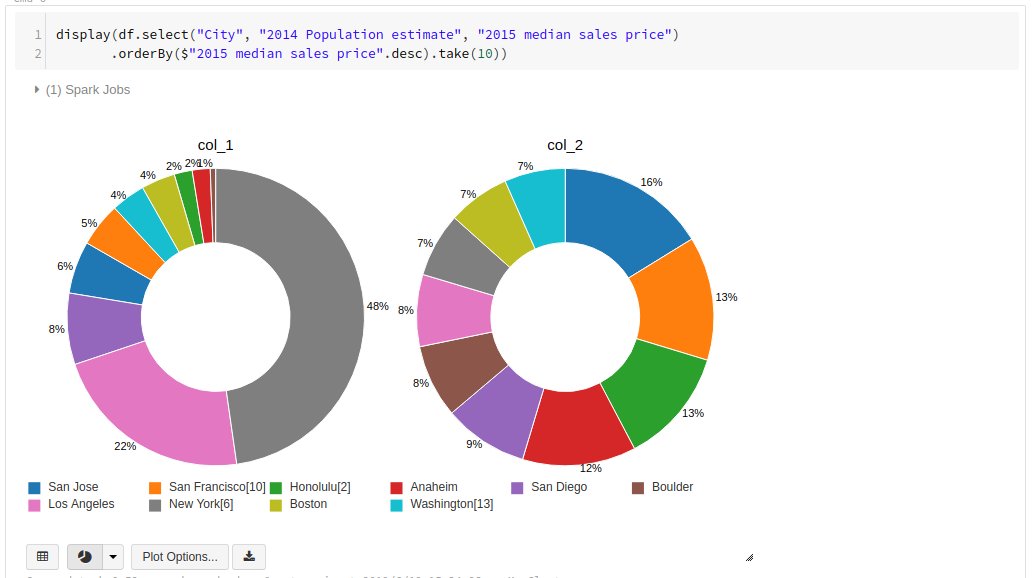
[Apply]を押すと、円グラフが描画されます。
まとめ
DataFrameはデータベーステーブルを操作するような、より直感的なAPIが備わってます。
ぜひDataFrameAPIをマスターして、柔軟でスケーラブルな分析を実践してください。
弊社はデジタルマーケティングからビッグデータ分析まで幅広くこなすデータ分析のプロ集団です。
Databricksのコンサルティング/導入支援についてのお問合わせはこちらからどうぞ。
ブログへの記事リクエストはこちらまでどうぞ。


