こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
今回はAzure Databricksについてです。
Azure DatabricksとはAzureの機能のひとつで、Apache Sparkをベースとした分散処理ソリューション「Databricks」のフルマネージドサービスです。
という訳で早速Adobe DatafeedをAzure Databricksにロードして分析します。
Azure Databricksを使い始める
Azure Databricksは、Azureのアカウントがあればまずは14日間無料のトライアルが可能です。
1.トライアルにサインアップする
Azureにログインしたら、[すべてのサービス] > [Databricks]を開きます。

すべてのサービス > Azure Databricks
[+追加]ボタンを押して、Databricksのワークスペースを新規作成します。
[Pricing Tier]で、[Trial (Premium – 14-Days Free DBUs)]を選ぶと14日間無料トライアルが出来ます。
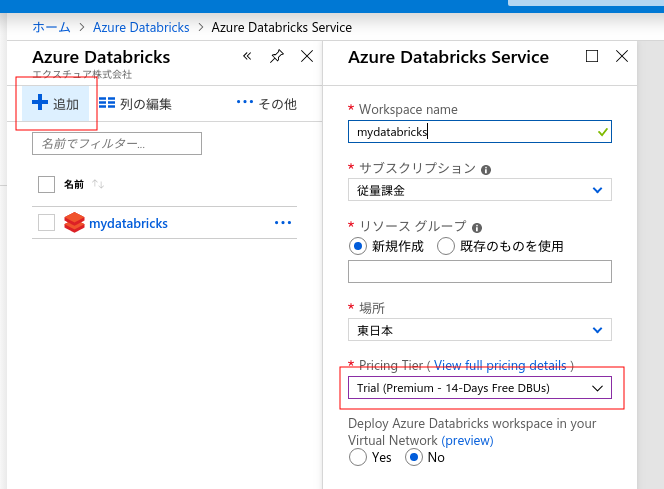
14日間無料トライアル
これでDatabricksを始める準備が出来ました。
[Launch Workspace]をクリックしてDatabricksにログインします。
ここからクラスタを作り、Notebookで分析を進めていきます。
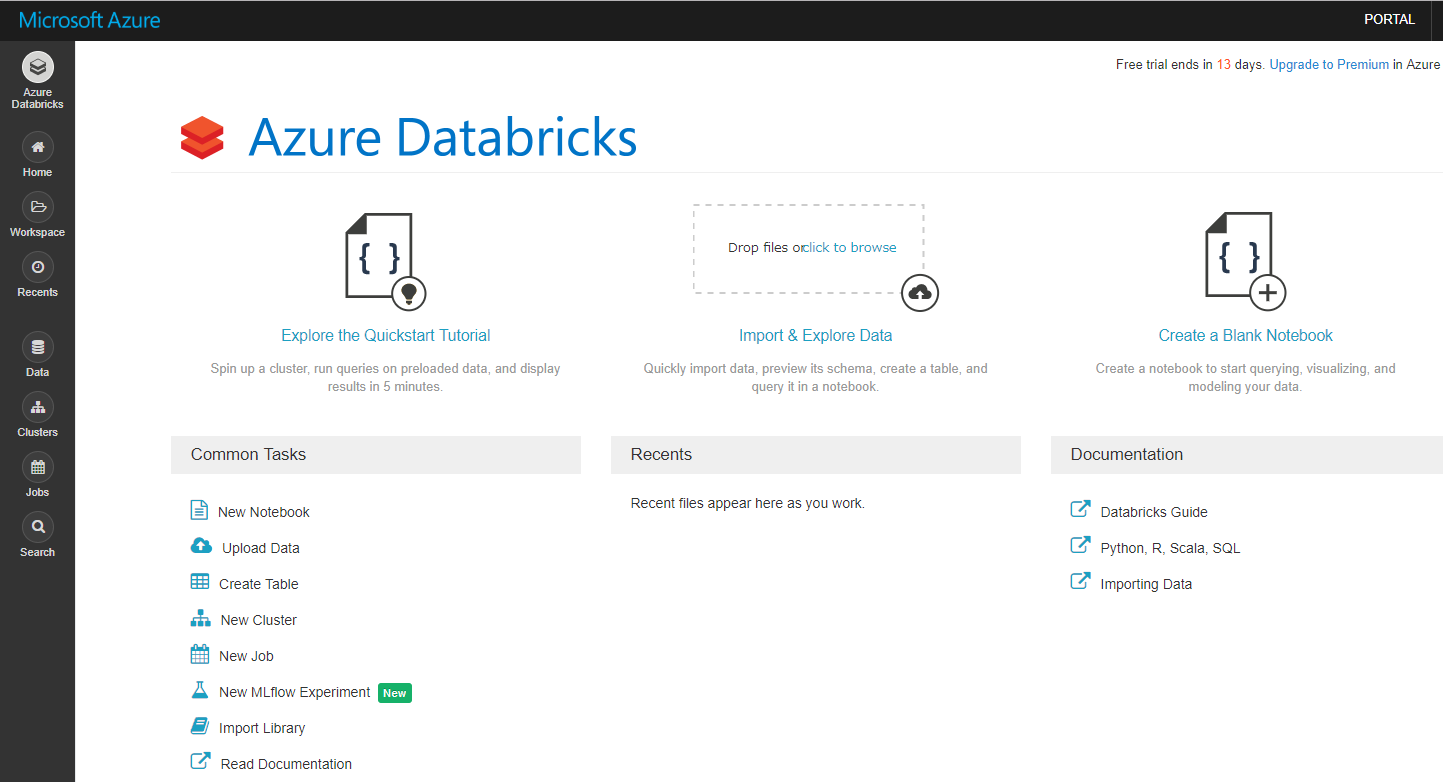
Azure Databricks ホーム画面
2.クラスタを作成する
分析するためのクラスタを作成します。
左のメニューの[Clusters]を開き、[Create Clusters]をクリックします。
クラスタの名前をつけて、ライブラリのバージョンはデフォルトのままにします。
そしてクラスタを構成するマシンスペックを選ぶのですが、トライアル中は最大でCPUを10コアしか使えないので、マシンタイプとワーカー数を調整してCPUコアが10以下になるようにします。
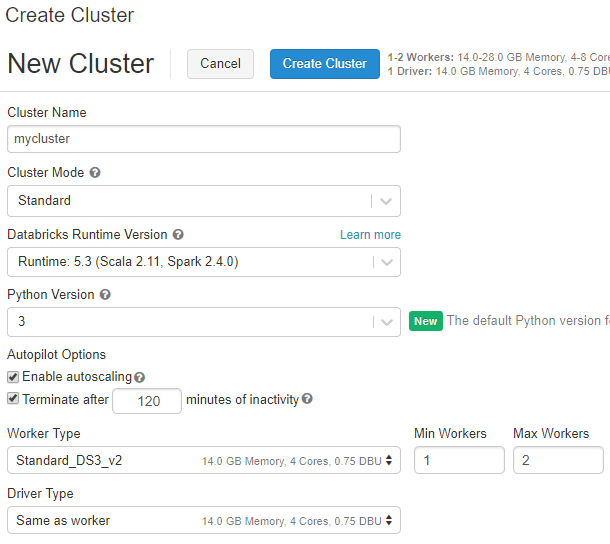
クラスタを作成する
3.データを用意する
次は分析するデータを用意します。
小さいテキストファイルならブラウザからアップロード出来ます。
また、Databricksには様々なコネクタが用意されます。
Azure Blobをクラスタのファイルシステムにマウントする事も出来るので、今回はAzure BlobにAdobe AnalyticsのDatafeedファイルをアップロードしておきました。
DatabricksからAzure Blobへ接続するためには、アクセスキーが必要です。
Azureホーム画面から[ストレージアカウント] を開き、マウントするBlobのアカウントを選んで[アクセスキー]を開きます。
ここに記載されてる[key1]の値をコピーしておきます。
ストレージアカウントのアクセスキーを取得
4.ノートブックで分析する
さてここからがFun Partです。
実際にデータをロードして分析をします。
Databricksのホーム画面から[Create a Blank Notebook]をクリックします。
ノートブックの名前をつけて、言語とクラスタを選択します。
今回はScalaを選びます。
空のノートブックを作成
ノートブックを作成すると、空白のセルが一つ用意された画面が出てきます。
ここにScalaのコードを書き込んで、各ステップごとに確認しながら分析を実行できます。

Notebook上で分析のためのコーディングを行う
各ステップ毎に実行するScalaコードを説明します。
i.Azure Blobをマウントする
dbutils.fs.mountを使ってBlobをクラスタのDBFSファイルシステムにマウントします。
マウントポイントは/mnt配下にしないと怒られるので、/mnt/datafeedにしました。
dbutils.fs.mount(
source = "wasbs://コンテナ@ストレージアカウント.blob.core.windows.net/",
mountPoint = "/mnt/datafeed",
extraConfigs = Map("fs.azure.account.key.ストレージアカウント.blob.core.windows.net" -> "アクセスキー"))
ii.ファイルロケーションとファイルタイプを宣言する
マウントしたディレクトリ配下にある、Adobeのhit_data.tsvファイルの場所を宣言します。
val file_location = "/mnt/datafeed/hit_data_20190513.tsv" val file_type = "csv"
iii.ファイルを読み込む
spark.read.formatを使ってCSVファイルをロードします。
Adobe Datafeedはタブ区切りのTSVファイルなので、delimiterはタブを指定してます。
また、見やすいようにhit_dataにはヘッダ列を一行目に追加してるので、headerオプションも指定します。
val df = spark.read.format(file_type).option("inferSchema", "true").option("delimiter", "\t").option("header", "true").load(file_location)
さて、うまく読み込めたかデータを表示してみます。
iv.データを表示する
df.selectでデータを抽出して、displayで表示します。
display(df.select("*"))
実行すると、結果が表形式で返って来ました。
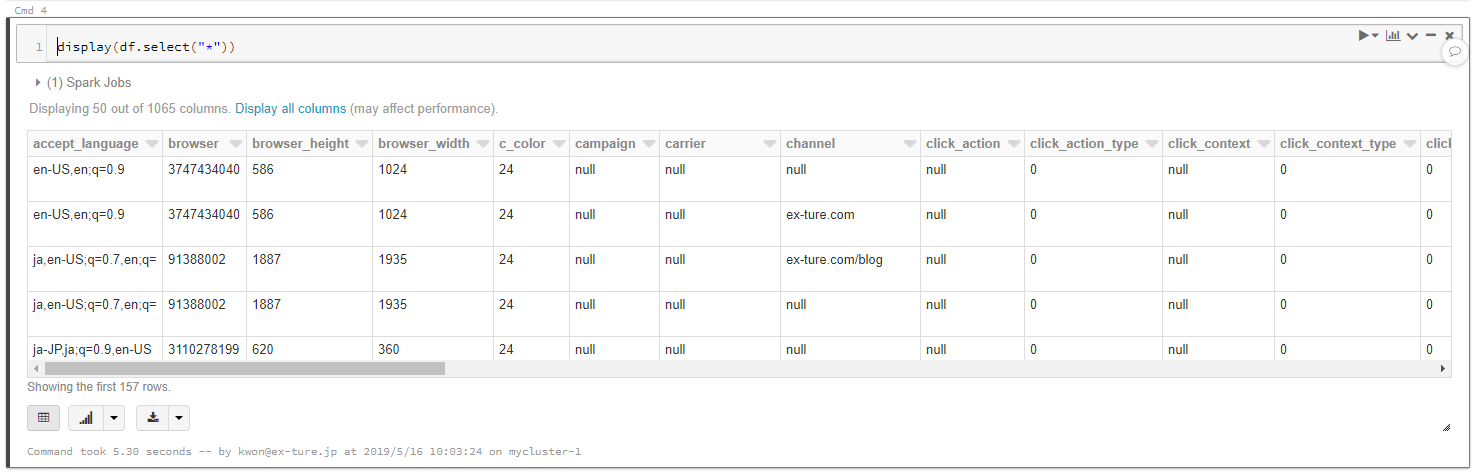
読み込んだ全カラムを表示
v.SQLでアクセスするためのビューを作る
ここから先は使い慣れたSQLで分析します。
まずはその前に、SQLでアクセス出来るように読み込んだデータをビューとして保存します。
df.createOrReplaceTempViewを使います。
df.createOrReplaceTempView("hit_data_20190513")
vi.SQLでデータを抽出する
セルの冒頭で「%sql」と一行書くことでSQLを使えるようになります。
SQLを使って、リファラードメインとセッション数の上位8件を抽出します。
%sql SELECT ref_domain, count(concat(post_visid_high, post_visid_low, visit_num)) as sessions FROM hit_data_20190513 WHERE exclude_hit = '0' and post_page_event = '0' and ref_domain != 'null' GROUP BY 1 ORDER BY 2 DESC limit 8
これまたSQLの結果が表形式で返って来ました。
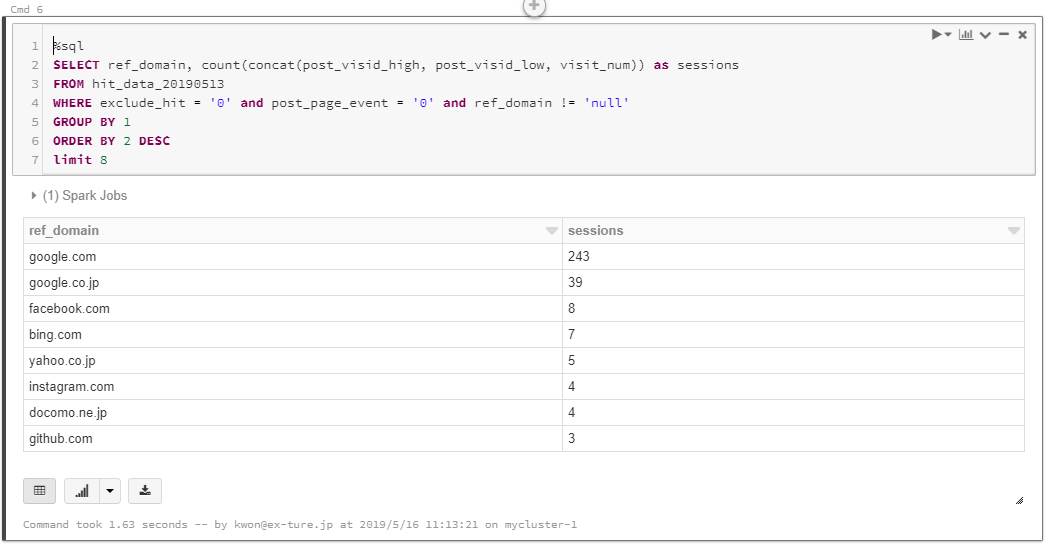
SQL実行結果
このままでは面白くないので、円グラフに変換します。
グラフボタンから「Pie」を選びます。
グラフ化します
すると、見事に円グラフが出てきました。
デフォルト表示だと小さくて字が潰れてしまうので、グラフの右下をマウスで抑えながらリサイズすると見やすくなります。
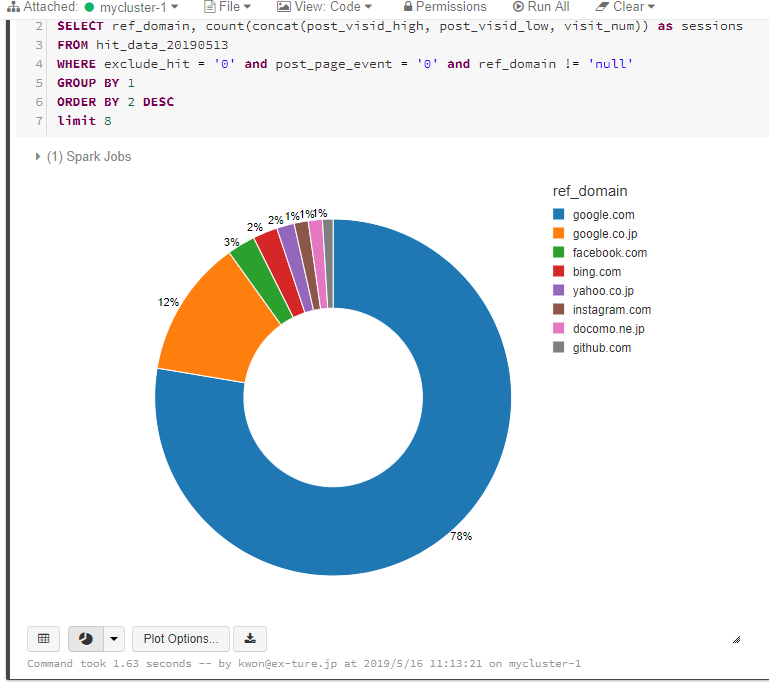
円グラフの出来上がり
これはなんとも使いやすいフルマネージドSparkですね。
Scalaだけではなく、SQL、Python、Rも使えるので、得意な言語でデータ分析を行えます。
可能性が無限大です。
まとめ
Sparkは以前からGCPのDataprocで使ってましたが、Azure Databricksはより使いやすいパワフルなGUI付きのフルマネージドSparkでした。
今後はDatabricksとSparkのメリットを活かして、データ分析と機械学習を推進して行きます。
弊社はデジタルマーケティング領域から抜け出した、データ分析集団です。
クラウドの強さを活かした弊社のデータ分析に興味がありましたら、こちらからお問い合わせください。
ブログへの記事リクエストはこちらまで