こんにちは、喜田です。
いままでSnowflakeのライトユーザーで一部機能だけに特化して触っている状態でしたが、最近はData Superheroes 2024になったこともあり、いままで関わりの薄かった製品領域も調査したり、海外リージョンでしか出ていないプレビューを触ったりしています。
そのうちの一つがCopilotで、いまは北米など一部リージョンでのみパブリックプレビュー中の、Snowflakeコード開発が一段と捗るAIおしゃべり機能です。
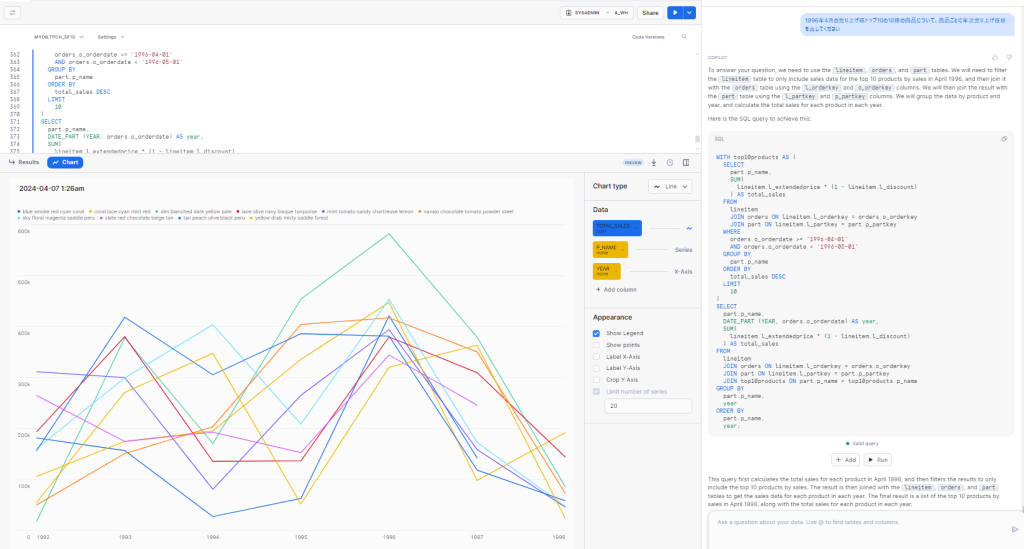
この右側のパネルがCopilotとのチャット。出力が多くてチャットっぽくないですが、上から会話が続いております。
Copilotで作るSQL
私はSQLばかり書いている勢(まれにChatGPTに教えてもらってお遊び程度のPythonも書く)なので、あくまでSQLについて。
元々SQLの講師とかをしていたので、ここ数年はSQL表現で悩むことも少なく、AIに作ってもらわんでもな~みたいな思いがどこかにありました。が、Copilotさんすごすぎる。すごすぎるので、素直にCopilotさんに従って、日本リージョンに来るのを待って、生産性を爆上げしたいと思います!!!
すごいポイント1:データの意味を理解している?
すごすぎてまだ信じきっていないのですが、コメントなしのテーブル名、列名だけでテーブル間の関係性とか、値の意味を理解しているようなクエリを作ってきます。
今回試したのは以下です。誰でも同じデータで試せます!(ただしCopilot使えるリージョンは限られる)
/* Snowflakeが公開してるサンプルのTPCHデータを入手
* この時点ではテーブルや列にコメントがついてる
*/
CREATE DATABASE SNOWFLAKE_SAMPLE_DATA FROM SHARE SFC_SAMPLES.SAMPLE_DATA;
GRANT IMPORTED PRIVILEGES ON DATABASE SNOWFLAKE_SAMPLE_DATA TO ROLE PUBLIC;
/* 自分のデータベースやスキーマを準備、上記をデータのみ全件コピー */
USE DATABASE mydb;
CREATE SCHEMA tpch_sf10;
USE SCHEMA tpch_sf10;
CREATE TABLE customer AS SELECT * FROM snowflake_sample_data.tpch_sf10.customer;
CREATE TABLE lineitem AS SELECT * FROM snowflake_sample_data.tpch_sf10.lineitem;
CREATE TABLE orders AS SELECT * FROM snowflake_sample_data.tpch_sf10.orders;
CREATE TABLE part AS SELECT * FROM snowflake_sample_data.tpch_sf10.part;
CREATE TABLE nation AS SELECT * FROM snowflake_sample_data.tpch_sf10.nation;
CREATE TABLE partsupp AS SELECT * FROM snowflake_sample_data.tpch_sf10.partsupp;
CREATE TABLE region AS SELECT * FROM snowflake_sample_data.tpch_sf10.region;
CREATE TABLE supplier AS SELECT * FROM snowflake_sample_data.tpch_sf10.supplier;
サンプルと同じデータセットを複製していますが、コメントや外部キー制約によるテーブル間の関連性が一切消えました。
このlineitemテーブルはある商店の売り上げデータで、あるタイムスタンプにどの商品がいくつ売れた、定価いくらでディスカウント何パーセント、といった販売実績データが入っています。データは1992~1998年の日付で入っていますので、そのあたりさえ予備知識として知っていれば2024年のデータを要求して結果0件ということもないでしょう。
テーブル作成した直後は、「学習中だよ」というような旨の返答でCopilotさんも答えてくれなかったのですが、2時間後ぐらいにおもむろに投げかけた一つ目の質問ですごさを目の当たりにしました。
1996年4月の売り上げ額トップ10の10種の商品について、商品ごとに年次売り上げ推移を出してください
※この通り、しょっぱなから日本語onlyで聞いています。
※実は、いくつかのLLMで同種のSQLを作らせたことがありますが、適切なテーブル選定が行われない、JOINなんてもってのほか、GROUP BYのキーもなんかおかしい・・・といった程度で、適切な回答は得られないな~と判断していたのが先月ぐらいだったのですが・・・
/* Snowflake Copilotが生成したSQL */
WITH top10products AS (
SELECT
part.p_name,
SUM(
lineitem.l_extendedprice * (1 - lineitem.l_discount)
) AS total_sales
FROM
lineitem
JOIN orders ON lineitem.l_orderkey = orders.o_orderkey
JOIN part ON lineitem.l_partkey = part.p_partkey
WHERE
orders.o_orderdate >= '1996-04-01'
AND orders.o_orderdate < '1996-05-01'
GROUP BY
part.p_name
ORDER BY
total_sales DESC
LIMIT
10
)
SELECT
part.p_name,
DATE_PART (YEAR, orders.o_orderdate) AS year,
SUM(
lineitem.l_extendedprice * (1 - lineitem.l_discount)
) AS total_sales
FROM
lineitem
JOIN orders ON lineitem.l_orderkey = orders.o_orderkey
JOIN part ON lineitem.l_partkey = part.p_partkey
JOIN top10products ON part.p_name = top10products.p_name
GROUP BY
part.p_name,
year
ORDER BY
part.p_name,
year;
3つ以上のJOINもお手の物、副問い合わせ(WITH句を使ったCTEのパターン)も使うし、Snowflake純正というだけあってSnowflakeの方言をちゃんとわかって日付関数など使ってくれています。例えばChatGPTもある程度綺麗に作ってくれますが、「日付の加工などは各DB製品で差があります」と言って結構ラフな加工例を出してきます。
そして注目したいのがこの部分、
SUM(
lineitem.l_extendedprice * (1 - lineitem.l_discount)
) AS total_sales
売り上げを算出するために、価格と値引き幅をちゃんと考慮しています。
繰り返しになりますが、テーブル定義や列定義にコメントは一切入れておらず、列名の情報のみ、値はそれぞれ数字がずら~~~っと並んでいるだけの列です。
このデータが真にそういう意味の列か?はきちんと業務ロジックを理解して検証する必要がありますが、それを提案してきたということがスゴすぎて、もはやゾワッとしました。
すごいポイント2:親切な説明&検証
上記でSnowflake Copilotのリアルな回答がこちら

回答にはSQL文だけでなく、いろいろな文章がくっついていますね。いろんなクエリを試しましたが、常にこのフォーマットで回答を作ってくれます。返答は英文ですが、サボらずに中身をちゃんと読んでみましょう。
- SQL作成の方針
- 要求されたデータはどのテーブルのどの列にありそうか示してくれる
- このロジックを使ってxxxの判定をするよ
- 生成されたSQL
- 見た感じ適切でしかない
- 3つ以上のテーブルのJOINもお手の物
- 動作チェック
- 緑色のアイコンと「Varid Query」
- AddボタンとRunボタン
- 作ったSQLについての説明
- リクエストに対して、このSQLでは最初にxxxをやって、得られた中間結果からxxxを抽出しました。
- このSQLで最終的に得られるものはxxxのリストです。
何と親切な会話!
動作チェックについて
エグいSQL(下記のMATCH_RECOGNIZEなど)を作らせてみたところ、実行OKのSQLが緑マークでRUNボタンを伴うのに対して、赤マークと黄色マークの存在を確認しました。
- 赤マーク:原因追及できないけど構文解析に失敗するSQL
- 黄マーク:構文解析してエラーヵ所が判明しているSQL
のようです。赤黄とも、ワークシートにそのまま転記するAddボタンは押せますがRunボタンは押せませんでした。
実行せずとも(おそらく)構文解析エンジンを通して実行可否を判定してくれるって地味に嬉しい機能だと思います。膨大なデータを読むSQLを、文法としてOKかどうかを判断するためにとりあえず流してみるみたいなトライが激減するでしょう。
すごいポイント3:複雑なSQLを難なく生成
これは他のLLMでもまあまあなところまでは作ってくれるのですが、Snowflakeの魅力の一つに標準SQLに定められた多くの構文に対応していることがあります。そのSnowflakeが書ける(Snowflakeでしか書けない)SQLを生成してくれるLLMはおそらくSnowflake Copilotだけなのではないでしょうか。
複雑なSQLと言えば、例えばウィンドウ関数をまず試してみました。みなさんウィンドウ関数パッと書けますか???
有名な例でいうと「移動平均」を算出するのはウィンドウ関数が適切です。使ったことない人からすると、そもそも「移動平均ってなんやねん」ですよね。
コロナ禍で感染者数が連日報道されていた際、1日のスパイクを無視して増減の傾向を捉えるような目的で、毎日直近1週間の平均を出しているようなケースがありました。これが移動平均です。ある1日だけ感染者数がたまたま増加したとして、翌日以降元の傾向に戻れば全体としての増減の傾向は変わらずつかめます。
こういったユースケースに対して「感染者数の移動平均を出して。ウィンドウの区間は前後3日で、パーティションは県別で」などというと、適切なクエリを作ってくれます。ちょっとウィンドウ関数に親しみのある人の聞き方ですが、後半は無くともそれっぽいクエリを組み立ててくれそうです。
例えば
1995年の売り上げデータのうち、サプライヤー別に月次売上を集計して、売り上げが6カ月連続で増加しているサプライヤーを特定してください。
と聞けば、
WITH monthly_sales AS (
SELECT
l_suppkey AS supplier,
DATE_PART (MONTH, o_orderdate) AS month,
SUM(l_extendedprice * (1 - l_discount)) AS sales
FROM
lineitem
JOIN orders ON l_orderkey = o_orderkey
WHERE
DATE_PART (YEAR, o_orderdate) = 1995
GROUP BY
l_suppkey,
DATE_PART (MONTH, o_orderdate)
),
monthly_sales_lag AS (
SELECT
supplier,
month,
sales,
LAG (sales) OVER (
PARTITION BY supplier
ORDER BY
month
) AS prev_month_sales,
LAG (sales, 2) OVER (
PARTITION BY supplier
ORDER BY
month
) AS prev_2_month_sales,
LAG (sales, 3) OVER (
PARTITION BY supplier
ORDER BY
month
) AS prev_3_month_sales,
LAG (sales, 4) OVER (
PARTITION BY supplier
ORDER BY
month
) AS prev_4_month_sales,
LAG (sales, 5) OVER (
PARTITION BY supplier
ORDER BY
month
) AS prev_5_month_sales
FROM
monthly_sales
)
SELECT
supplier
FROM
monthly_sales_lag
WHERE
sales > COALESCE(prev_month_sales, 0)
AND sales > COALESCE(prev_2_month_sales, 0)
AND sales > COALESCE(prev_3_month_sales, 0)
AND sales > COALESCE(prev_4_month_sales, 0)
AND sales > COALESCE(prev_5_month_sales, 0)
GROUP BY
supplier
HAVING
COUNT(*) = 6;
が即レスされてくるのです。(ちなみに、「6カ月連続で」という問いに対して、これだとある月を基準に5カ月にわたってその売り上げを超えてるを意味しているのでちょっと意図と違うものではありました。意図を修正するような問いかけで改善可能。)でも、この問いにウィンドウ関数でLAGを使うというアイデアは求めていた通りのものです。
同じ質問に対して、Snowflakeだからこそという回答も来ました。
WITH sales_data AS (
SELECT
supplier.s_name AS supplier_name,
DATE_PART (MONTH, orders.o_orderdate) AS month,
SUM(
lineitem.l_extendedprice * (1 - lineitem.l_discount)
) AS total_sales
FROM
lineitem
JOIN orders ON lineitem.l_orderkey = orders.o_orderkey
JOIN part ON lineitem.l_partkey = part.p_partkey
JOIN partsupp ON part.p_partkey = partsupp.ps_partkey
JOIN supplier ON partsupp.ps_suppkey = supplier.s_suppkey
WHERE
orders.o_orderdate >= '1995-01-01'
AND orders.o_orderdate < '1996-01-01'
GROUP BY
supplier.s_name,
DATE_PART (MONTH, orders.o_orderdate)
)
SELECT
supplier_name,
month,
total_sales
FROM
sales_data MATCH_RECOGNIZE (
PARTITION BY supplier_name
ORDER BY
month MEASURES FIRST (month) AS month,
FIRST (total_sales) AS total_sales PATTERN (increase +) DEFINE increase AS total_sales > LAG (total_sales) OVER (
PARTITION BY supplier_name
ORDER BY
month
)
);
MATCH_RECOGNIZE構文は Window関数のさらに特殊なパターンでSQL2016で規定されています。正規表現でウィンドウ内の値の増減パターンを指示して、一致するパターンのみ返すというものです。今回でいうと「6カ月連続でincrease」がパターンにあたります。
まだいくつものDB製品で構文すら非対応ですが、Snowflakeは対応済み、Copilotも使い方を指示してきました。残念ながら構文エラーがあり実行できなかったのですが、エラーヵ所は特定される黄色パターンだったので微修正で使えそうです。(こういう時はまだ人がMATCH_RECOGNIZEの勉強しなければならない)
が、これは将来有望すぎる!
ビジネスユーザがデータから直接示唆を得る時代へ
生成AIの登場でデータ界隈の誰もが考えたと思いますが、非エンジニアがコードやSQLを書けずともデータドリブンな知見を得られる!という未来が一気に現実味を帯びてきています。
イマドキのあたりまえのデータ活用
毎週の経営会議で、「今週のxxの伸びは?」「お、数字いいね、この要因ってなに?」と数字を追っていくことを考えます。これを今はBIダッシュボードによって可視化された指標を追いかけること、注目すべき要素が見つかればそれを深堀りして要因を突き止めるといったことが普通に行われています。
一方で、「定型の指標」を追うことに特化しているのがBIダッシュボードであり、新たなビジネスの立ち上げに伴うテーブル追加・列追加がありダッシュボードに改修が必要になるとか、既存の指標にとらわれない新たな視点での分析といったところはBIの限界・課題とされています。
一歩進んだデータ活用文化へ
部署ごとなどの自由な分析を許す取り組みもよく聞くようになってきました。各チームがそれぞれの業務にフィットするような自由な指標で分析することで、新たな視点での気づきを得ることができます。
個人的には、各チームが独自のダッシュボードを作って活用できている現場を見たことがあります。
そこではセルフサービス型のBIツールを用いたり、多少の手間はあれどExcelで十分ということもありました。(イケイケではないけど、活用という意味では確かにデータを活かせている。)
言い換えると、データ活用できるかはツールの問題ではないように思います。ツールはどうあれ、チームに稀にいる「エクセル王子」「Pythonおじさん」(ほめてる)の貢献あって実現されている実態というのは結構多いのではないでしょうか。(かくいう私もSQLおじさんとしていくつもの社内のご相談を引き受けた過去があります。)そしてExcelなら触れるから、という人のおかげで神Excelが定着しています。
チームでの新たな試みを可視化しようとした際に、一部のシロウト仕事(Python書けるとしても、あくまでも本職は営業でしょ?という意味で)に頼らざるを得ないというのはやっぱり課題ですよね。
Snowflake Copilotが実現する新たなデータドリブン時代
正直、ウィンドウ関数を書けないと出せない分析をビジネスユーザーが生で欲しがるシーンを誰が想像したでしょうか。BIダッシュボードで表示してるものしか・・・と言われても、そりゃそうだよな、の世界です。
しかし、実は移動平均で全体の推移を傾向で捉えると有益なシーンはたくさんあるかもしれません。BIダッシュボードの要件定義で「xxの移動平均を示せるように作って」を挙げるのはある意味ハードルが高いでしょう。全体の予算もあるし、移動平均で何が言えるの?ダッシュボードによくわからん要素を入れたくないんだけど。といったマイナスを覆すほどの価値を説得しないといけません。
これからはCopilotの時代です。「xxの移動平均を出して」と言えば一発で作ってくれます。しかも、Snowsightの描画機能とものすごく相性が良いです。その場で出したデータを数クリックで意味の読み取りやすいグラフにして描画できます。

SQLやダッシュボード開発の難度を完全に無視して、とにかくCopilotに聞くといいことありそう!というところまで来ました。あとは日本でのGAを待つだけです。
これからは、Copilotに質問するためのビジネス的な視点(つまり移動平均が何を表すかといった、日本語とビジネスのお勉強)に全力投球するのがいいと思います。
みんなでAIを使い倒して生産性を爆上げしましょう!!!