最初に
なにか発見したことを総合研究所で発表したり、デモ資料を作ったりする時に顧客の実データを持ち出すわけにはいきません。
そのようなときにダミーのデータをつくれると大変便利です。
ただ、データ分析において完全に適当なデータを用いてデモをしても実用性に乏しいと考えられるのでできる限り実データに近いものを生成できるように試行錯誤してみました。
また、記事を書くにあたってPythonのNumPyとFakerパッケージを使ってダミーデータを作成するを参考にさせていただいております。
目標
渋谷区に存在する小売店Extureのダミーデータをつくります。
Extureは購買層の男女比6:4,購入額の中央値¥6000,顧客10万人の小規模商業施設です。
年齢層は18-60まで一様分布で存在しているものとします。
試行錯誤
まず必要なものをインポートします
まずはidです。たんに1から順にidを振ってあげてもよいのですが、少し寂しいのでハッシュ化しておきます。
次にメールアドレスです。こちらもハッシュ化するべきなのでしょうが、今回はFakerのデモも兼ねているということでそのままで放置しておきます。
メールデータが入手出来ているのはそれほど多くないだろうと考えられるので(そういう設定なので)だいたい14%ぐらいしかデータが入っていないことにします。
また、IDが一括管理されていないかもしれません。Exture社は会員の加入率90%を誇る独自アプリをもっており、それぞれの顧客はアプリのIDも持っているものとします。こちらは数字で適当に振ってやりますが、5桁で0埋めしてやることにします。(‘00001’のようにするということです)
次に、顧客の住所を市区町村の単位で振り分けてやります。
Fakerを使えばダミーの郵便番号や住所を作ることも一発でできるのですが、今回はExture社は渋谷区に一店舗しかなく、関東以外の顧客のデータは持っていないものとします。
前回までに作った関東の市区町村一覧を利用します。
関東の市区町村一覧のテーブルは以下のようになっています。
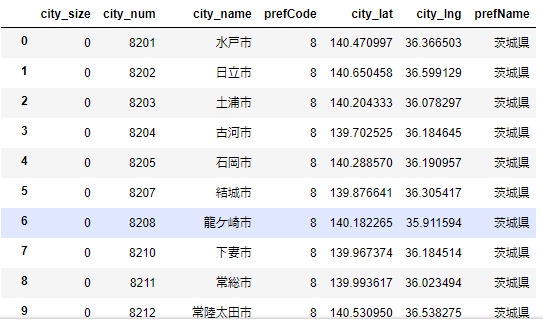
city_sizeが0のものは普通の市町村、1のものは政令指定都市、3のものは23区で割り振られているので(詳しくは該当記事をご覧ください)それぞれ適当な割合で割り振ってやります。
性別は6:4で割り振ってやります。
フラグやダミー変数はrandomで振り分けてやってもよいですがウエイトを付けて割り振る方法をとっています。
最後に購入額です。Extureは客単価(年)の中央値は6000円ほどです。
ただ、購入額は正規分布ではなく、平均値と中央値にずれがあり、一部の太客が平均値を吊り上げている分布で作ります。
このような分布は対数正規分布で作成できます。対数正規分布とは下図のようなものです。

年収の分布に何となく似ていそうだということは分かってもらえるかと思います。
今回は中央値¥6000で作成します。
ちなみにこのデータだと中央値6000,平均8000となっておりまさに狙い通りのデータが作れています。
最終的に作成したデータがこちらです。
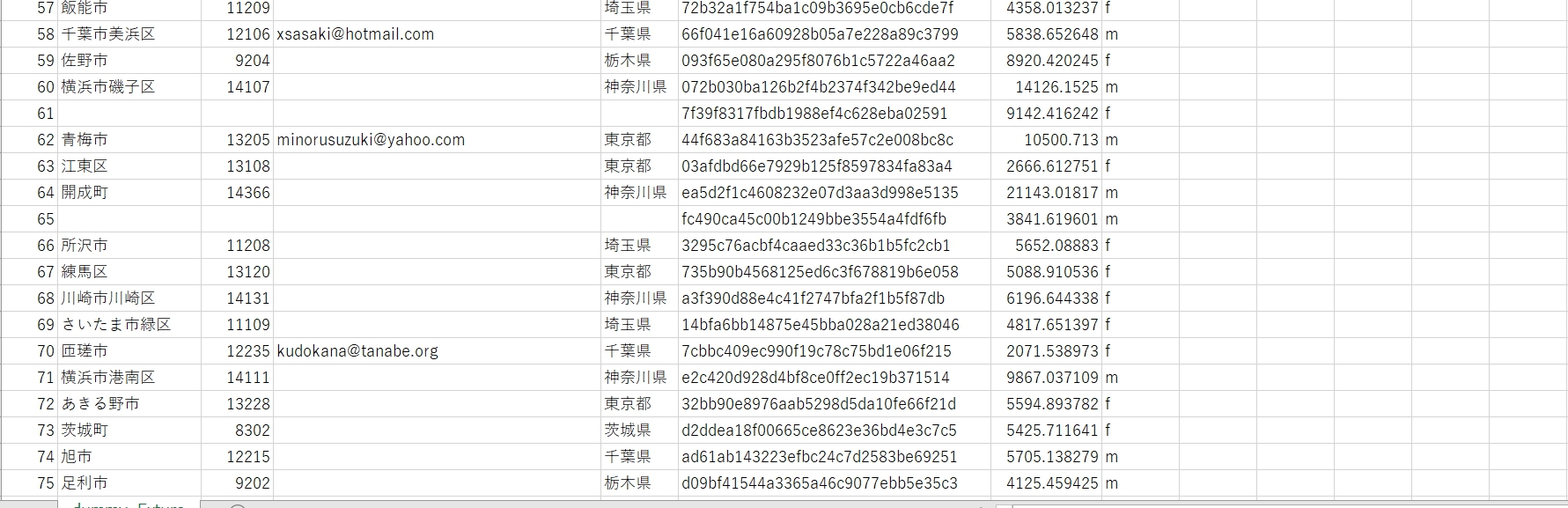
考えているより”詰まっている”感じがしました。こんなにきれいにデータが取れていることは少ないのでもう少し空行を増やせばよかったと思います。
実際にデモデータとしてダミーを作成するときは実データの分布やカラム数を確認して作りましょう。
なにはともあれこれで完成です!
次回は前回までに作成したExtureまでのドライブ時間のTableauとこのデータを組み合わせてドライブ時間による顧客の分析を行いたいと思います。
それでは。
参照サイト
PythonのNumPyとFakerパッケージを使ってダミーデータを作成する
Pythonのfakerで日本語テストデータを生成する











この記事へのコメントはありません。