MNISTの手書き数字画像をCNNで分類
前回の記事でも利用したMNISTの手書き数字画像を使って、CNNの理解を深めていきたいと思います。
CNNとは
CNN(Convolutional Neural Network)とは、畳み込みニューラルネットワークの略で「画像データの特徴を効率よく集めるための仕組み」のことです。
CNNの流れをザックリ説明すると以下のようになります。
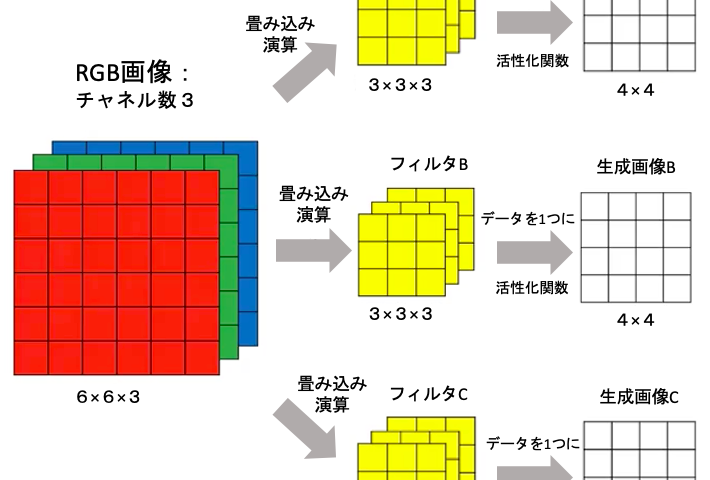
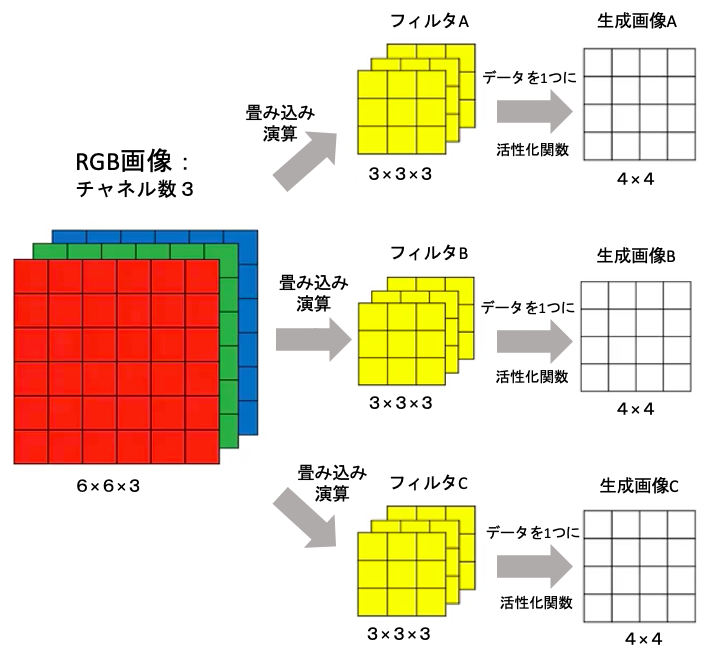
- 1枚の画像を複数チャネルに分化(RGB画像であればチャネル数は3)
- 各チャネルに畳み込み演算(フィルター)を用いて画像を小さくする(4×4の部分を1マスに)
- 演算後(フィルタ後)の各チャネルのデータを合計して1つのチャネルを作成
- 活性化関数(LeRUなど)を施し画像を生成
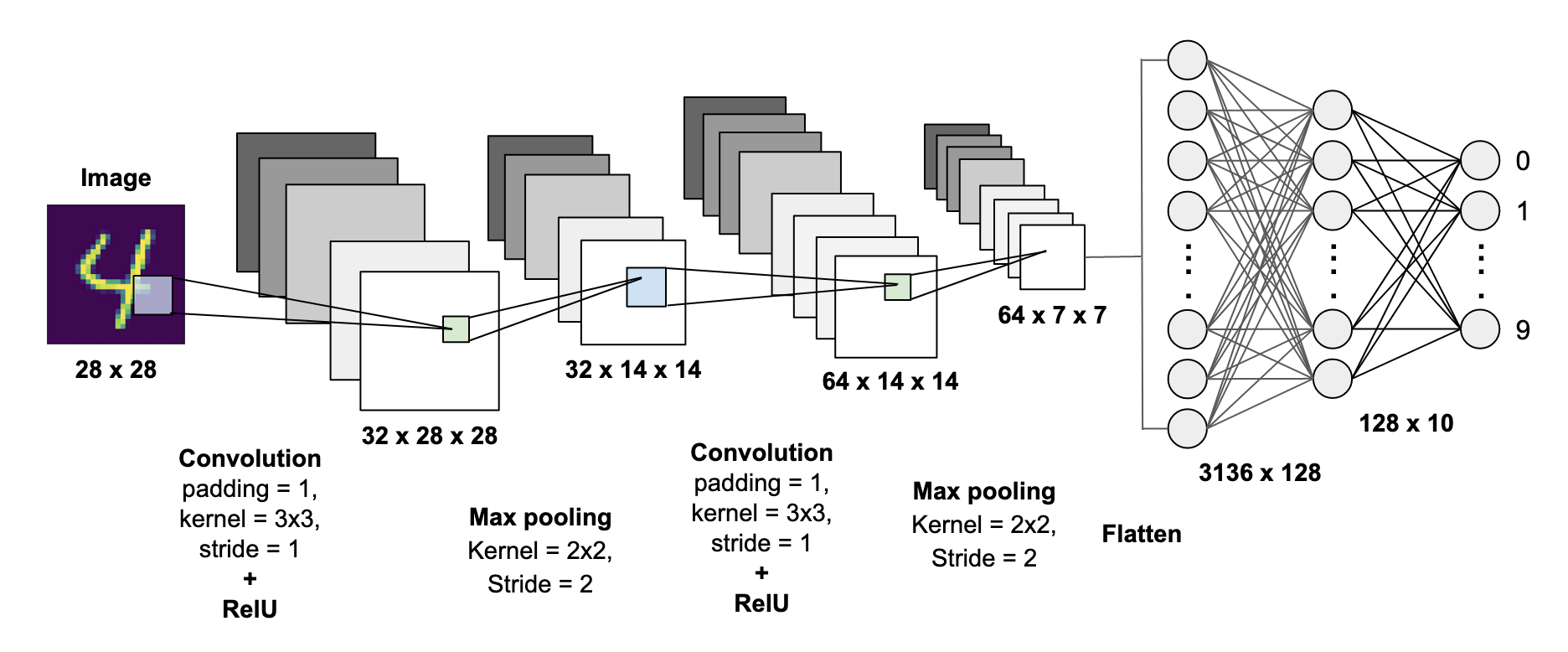
そしてこちらがCNNをモデルに組み込んだ大枠となります。
Convolutionが畳み込み層を表し、Max poolingはn×nのマスの最大値を取得する層を表しています。
※paddingは「画像の周りにデータ0のマスを用意すること」、karnelは「フィルターをかけるときのマスの数(n×n)」、strideは「どの程度マスをズラして処理を行うか」を意味します。
※Max poolingでn×nマスの最大値を取得する際に、同じ値が何度も取得されると特徴が強調されてしまうので、strideはkarnelの大きさに合わせるのが一般的です。
※toward data scienceより引用
MNISTをCNNで分類
'''ライブラリの準備'''
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
'''Datasetの準備'''
train_dataset = MNIST(root='mydata', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = MNIST(root='mydata', train=False, transform=transforms.ToTensor())
'''DataLoaderを作成'''
train_loader = DataLoader(dataset=train_dataset, batch_size=100, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=100, shuffle=False)
◆ライブラリとデータセットの準備
前回はscikit-learnから手書き画像のデータセットを用意しましたが、今回はtorchvision.datasets.MNISTから用意することにします。
MNIST読み込み時の引数(root, train, transform, download)は上の画像を参照してください。
◆DataLoderの作成
DataLoaderとは「データセットからデータをバッチサイズにまとめて返すモジュール」のことです。
DataLoaderについては以前紹介しているので、さらに知りたい方はこちらよりどうぞ。
'''モデルの定義'''
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc = nn.Linear(7 * 7 * 32, 10)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = CNN().to(device)
'''最適化手法の定義'''
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
◆モデルの定義
nn.Sequentialは前回の記事でも説明しましたが「モデルとして組み込む関数を1セットとして順番に実行しますよ」というものです。
<第一層>
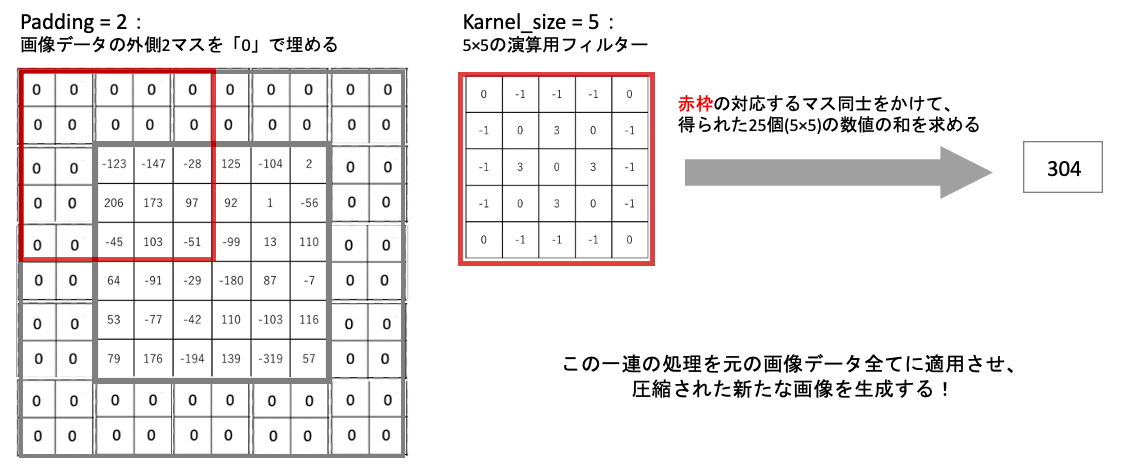
まずnn.Con2dで1つの画像データに16種類のフィルター(畳み込み演算)を適用させ、16個の生成画像(数値データ)を得ます。
このとき画像の外側に2マス分を0埋めするのが「paddding=2」、そして5×5の演算用フィルターが「karnel_size=5」となります。
そしてnn.BatchNorm2dで16個の生成画像に正則化を施した後、活性化関数ReLU「y=x(x>=0)、y=0(x<0)」を適用させ、nn.MaxPool2dで2×2マスの中の最大値を取りさらに画像サイズを小さくします。
※Batch Normalizationを含むPytorchのキホンを確認したい方はこちら。
<第二層>
畳み込み演算で特徴量を「16→32」に増やし、あとは第一層と同様の処理を行います。
そして、torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’)で、GPU(cuda)が使える環境であれば「cuda」という文字を返してください、という処理をdeviceという変数へ格納します。
GPUが使える前提であれば「device = cuda」という式が成り立つので、これ以降.to(device)は「.to(‘cuda’)」を意味することとなり処理をGPUへ移行させることができるのです。
※GPUが使えない環境であれば.to(device)は「.to(‘cpu’)」を意味することとなり、処理がCPU上で行われます。
◆最適化手法の定義
今回、評価方法は「交差エントロピー誤差」、損失関数には「Adam」を採用しました。
'''訓練用の関数を定義'''
def train(train_loader):
model.train()
running_loss = 0
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
running_loss += loss.item()
loss.backward()
optimizer.step()
train_loss = running_loss / len(train_loader)
return train_loss
'''評価用の関数を定義'''
def valid(test_loader):
model.eval()
running_loss = 0
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_loss += loss.item()
predicted = outputs.max(1, keepdim=True)[1]
labels = labels.view_as(predicted)
correct += predicted.eq(labels).sum().item()
total += labels.size(0)
val_loss = running_loss / len(test_loader)
val_acc = correct / total
return val_loss, val_acc

今回モデル内で利用したBatch nomalizationは訓練時とテスト時で挙動が変わってしまうので、明示的に「訓練モードmodel.train()」と「評価モードmodel.eval()」を示す必要があります。
◆訓練用の関数を定義
まずは「訓練モードmodel.train()」を明示し、lossを記録する用の変数を用意します。
<for文の中身>
train_loaderから画像データ(images)とラベル(labels)を取得するという流れは前々回と同じなのですが、これらのデータ(images, labels)をGPUへ送るという点が異なります。
その後は「勾配のクリア → 交差エントロピー誤差を計算 → 誤差逆伝播 → パラメータの更新」といういつもの流れです。
※ここで学習に使ったデータ(train_loader)は全てのデータではなく、あくまでデータの一部(バッチ)であることを忘れずに。
◆評価用の関数を定義
中身はほとんど訓練用の関数と同じですが、以下の点で異なります。
・「with torch.no_grad()」で勾配を計算せずにGPUの負荷を減らす(処理速度を上げる)
・「.max(1, keepdim=True)[1]」で各テンソルの予測ラベルを集計
・「.view_as()」で正解ラベルと予測ラベルの型を合わせる
・「.eq()」で複数ラベルを同時に比較し「.sum().item()」で一致数の合計値を取得
'''誤差(loss)を記録する空の配列を用意'''
loss_list = []
val_loss_list = []
val_acc_list = []
'''学習'''
for epoch in range(10):
loss = train(train_loader)
val_loss, val_acc = valid(test_loader)
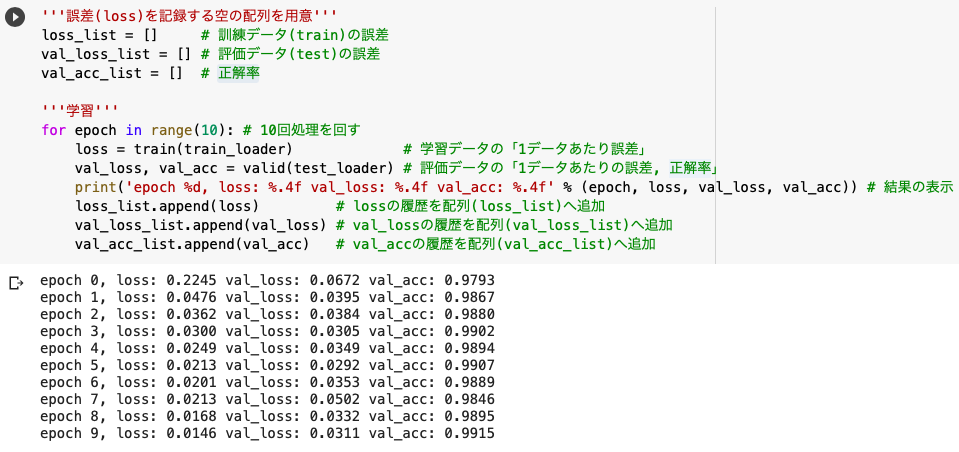
print('epoch %d, loss: %.4f val_loss: %.4f val_acc: %.4f' % (epoch, loss, val_loss, val_acc))
loss_list.append(loss)
val_loss_list.append(val_loss)
val_acc_list.append(val_acc)
'''学習の結果と使用したモデルを保存'''
np.save('loss_list.npy', np.array(loss_list))
np.save('val_loss_list.npy', np.array(val_loss_list))
np.save('val_acc_list.npy', np.array(val_acc_list))
torch.save(model.state_dict(), 'cnn.pkl')
「訓練データ・テストデータの誤差の推移, 正解率の推移」はNumpy形式で保存し、「モデルのパラメータなど」はPickle形式で保存しました。
'''結果の表示'''
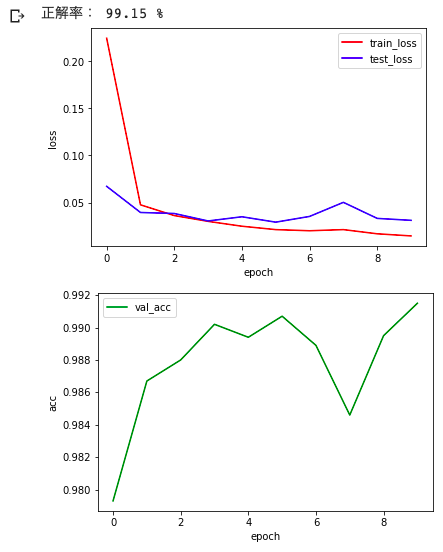
plt.plot(range(10), loss_list, 'r-', label='train_loss')
plt.plot(range(10), val_loss_list, 'b-', label='test_loss')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.figure()
plt.plot(range(10), val_acc_list, 'g-', label='val_acc')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('acc')
print('正解率:',val_acc_list[-1]*100, '%')

plt.plot(x, y)でx,y軸に座標を打つことができ、それ以外にも「色・グラフ形状・凡例名」などを指定することができます。
また、真ん中のplt.figure()は「新しいウィンドウを生成する」という機能で、これがないと今回の2つのグラフが1つになってしまうのです。
さて、最終的な精度が「99.15%」という数値になりましたが、これは前回(多層パーセプトロン)の結果が「94.7%」であったことに比べるとCNNはかなり性能が良いことがわかりますね。
次回はMNISTではなく、CIFAR10という6万枚のカラー画像を扱う予定です。乞うご期待!
参考文献
【GIF】初心者のためのCNNからバッチノーマライゼーションとその仲間たちまでの解説
pytorchで初めてゼロから書くSOTA画像分類器(上)
【前編】PyTorchでCIFAR-10をCNNに学習させる【PyTorch基礎】
Pytorchのニューラルネットワーク(CNN)のチュートリアル1.3.1の解説
人工知能に関する断創録
pyTorchでCNNsを徹底解説
畳み込みネットワークの「基礎の基礎」を理解する ~ディープラーニング入門|第2回
定番のConvolutional Neural Networkをゼロから理解する
具体例で覚える畳み込み計算(Conv2D、DepthwiseConv2D、SeparableConv2D、Conv2DTranspose)
PyTorch (6) Convolutional Neural Network









この記事へのコメントはありません。