Databricks: Delta Lakeを使ってみる

こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
今回はDatabricksで使えるストレージレイヤーである「Delta Lake」について説明します。
Data Lakeじゃなくて、De*l*ta Lakeです。デルタレイク。
DatabricksにCSVをロードしてDataFrameを作っていたら、実行結果の下にNoticeが出てきました。

こう書いてあります。
Accelerate queries with Delta: This query contains a highly selective filter. To improve the performance of queries, convert the table to Delta and run the OPTIMIZE ZORDER BY command on the table.
「Deltaを使ってクエリを加速しよう」と言ってますね。
早速試してみます。
Delta Lakeとは?
Delta Lakeとは、Apache Sparkで使えるスケーラブルなストレージレイヤーです。
ACIDトランザクションとバージョニングもサポートしてます。
DataFrameをDeltaフォーマットで書き出す
まずはDataFrameをDeltaデータとしてファイルシステムに書き出す必要があります。
DataFrameをformatで「delta」を指定して、saveするだけです。
df.write.format("delta").save("/delta/mydata")

DeltaデータからDataFrameを作る
今度は、先程ファイルシステムに書き出したDeltaデータを使ってDataFrameを作成します。
val df_delta = spark.read.format("delta").load("/delta/mydata")

Delta DataFrameにクエリを実行する
では、Deltaデータから作成したDataFrameを操作します。
なお、元データはKaggleの2015 Flight Delays and Cancellationsを使ってます。
目的地を出発地のある州別にグルーピングします。
通常のDataFrameと同じメソッドを使えます。
val df_delta2 = df_delta.filter('count > 5000)
.groupBy('origin_state).agg(collect_list('dest_city).as("dest_cities"))
.withColumn("dest_city_count", size('dest_cities))
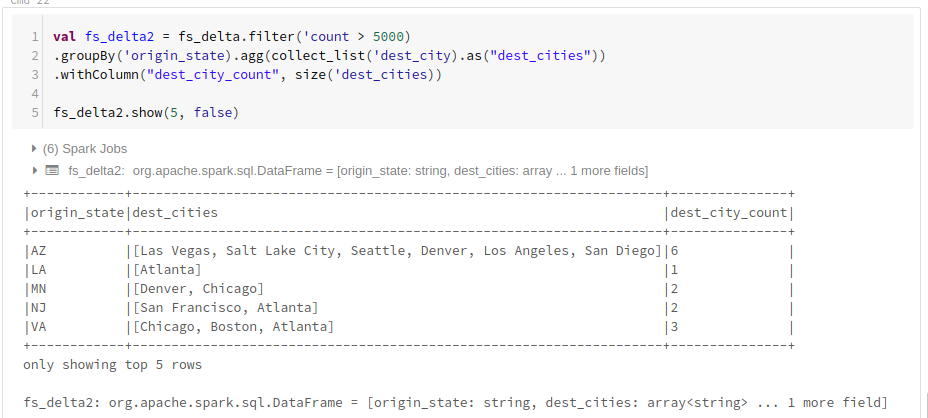
データ量が少ないデモデータで実施すると速さの違いを体感出来ませんが、PB規模のビッグデータに対して高速なクエリを実行できる事が期待される機能です。
弊社はデジタルマーケティングからビッグデータ分析まで幅広くこなすデータ分析のプロ集団です。
Databricksのコンサルティング/導入支援についてのお問合わせはこちらからどうぞ。
ブログへの記事リクエストはこちらまでどうぞ。