Databricks: Spark DataFramesをJDBCから作成する

こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
今回はDatabricks のDataFrameを、JDBC接続から作成する方法について紹介します。
RDBMS内のデータをDatabricksのDataFrameとしてロードしたい場合、JDBC接続を使えば簡単です。
針に糸を通す時に「アレ」を使えば簡単なのと同じです(謎
Databricks + MySQLで試す
例として、MySQLのSakilaサンプルDBをロードします。
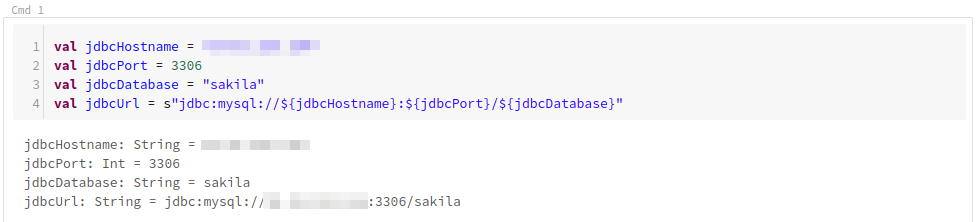
まずはJDBC接続URLを宣言します。
val jdbcHostname = "203.0.113.1" //ホスト名
val jdbcPort = 3306 //ポート番号
val jdbcDatabase = "sakila" //データベース名
val jdbcUrl = s"jdbc:mysql://${jdbcHostname}:${jdbcPort}/${jdbcDatabase}"
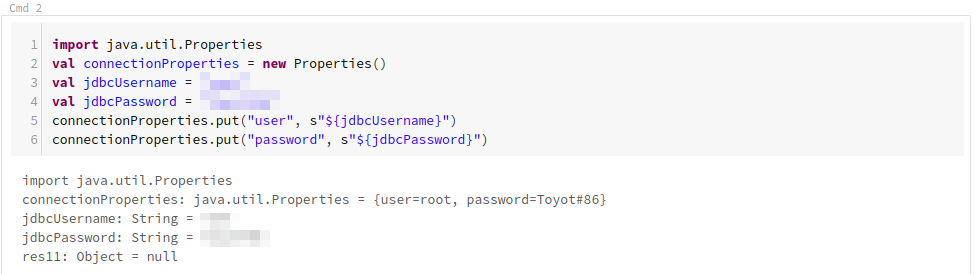
次に、java.utilPropertiesを使って認証情報をセットします。
import java.util.Properties
val connectionProperties = new Properties()
val jdbcUsername = "ユーザー"
val jdbcPassword = "パスワード"
connectionProperties.put("user", s"${jdbcUsername}")
connectionProperties.put("password", s"${jdbcPassword}")
さて、いよいよjava.sql.DriverManagerを使って接続します。
import java.sql.DriverManager val connection = DriverManager.getConnection(jdbcUrl, jdbcUsername, jdbcPassword)

DBに接続出来ました。
試しに「film」テーブルをロードします。
val film = spark.read.jdbc(jdbcUrl, "film", connectionProperties)

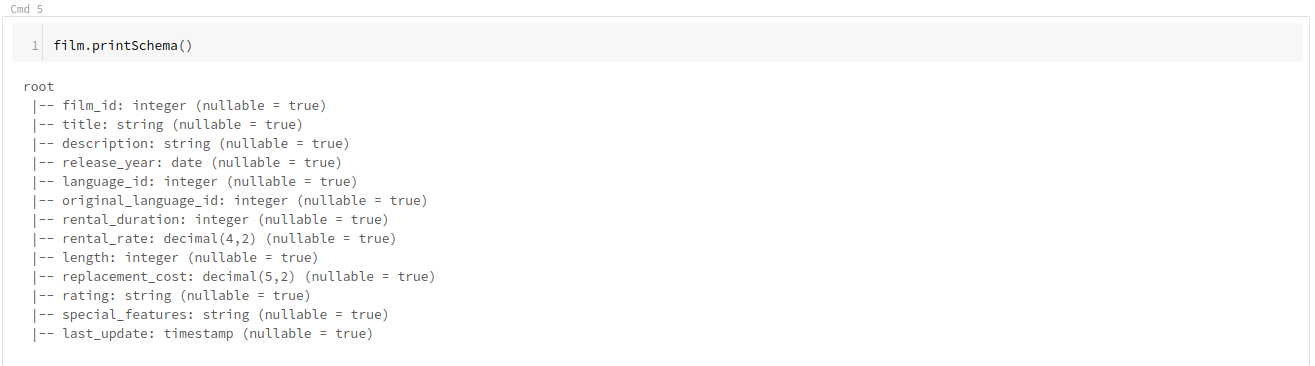
次は、テーブルのスキーマを表示してみましょう。
film.printSchema()
この「film」テーブルから film_id カラムと、 title カラムを表示します。
rating が「G」に等しい、という条件も付加します。
display(film.select('film_id, 'title).filter('rating === "G"))
Scalaでは、カラム名の前にシングルクオートを一つ付けるだけでカラムを呼び出せます。
1文字だけタイプすればいいので、とてもラクです。Pythonでは出来ません。
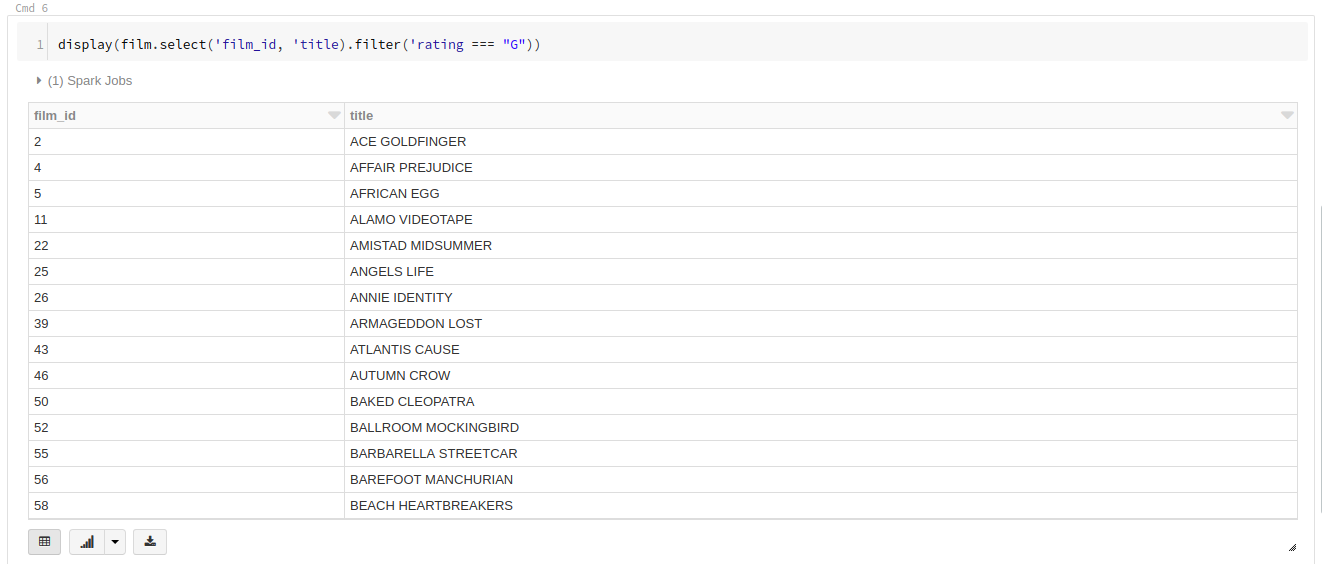
SakilaサンプルDBの中身を簡単に表示する事が出来ました。
通常のDataFramesとして操作出来ましたね。
まとめ
今回はJDBCからDataFramesを作成する方法について紹介しました。
RDBMSからデータを直接ロード出来るので便利です。
弊社はデジタルマーケティングからビッグデータ分析まで幅広くこなすデータ分析のプロ集団です。
Databricksのコンサルティング/導入支援についてのお問合わせはこちらからどうぞ。
ブログへの記事リクエストはこちらまでどうぞ。





