Databricks Community Editionを使ってApache Sparkを無料で学ぶ

こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
今回は、無料で使えるDatabricks Community Editionについて紹介します。
DatabricksのSpark実行環境として現在AWSまたはAzureを選ぶ事が出来ます。
AWS・Azure両方ともに14日間のフリートライアルが用意されます。
しかし、「14日間では学びきれないから無料でもっとSparkを勉強したい!」という方向けにCommunity Editionが用意されてます。
Sign Up for Databricks Community Edition
Community Editionでは商用版と比較して以下の制限があります。
・6GBメモリのインスタンス1台のみ作成可能(ワーカーノードは作れない)
・ノートブックの基本機能のみ利用可能(コラボレーション機能はない)
・ログインIDは3個まで作成可能
・選べるリージョンはus-west-2のみ
サインアップフォームに記入する
下記ページから申し込みます。
Sign Up for Databricks Community Edition
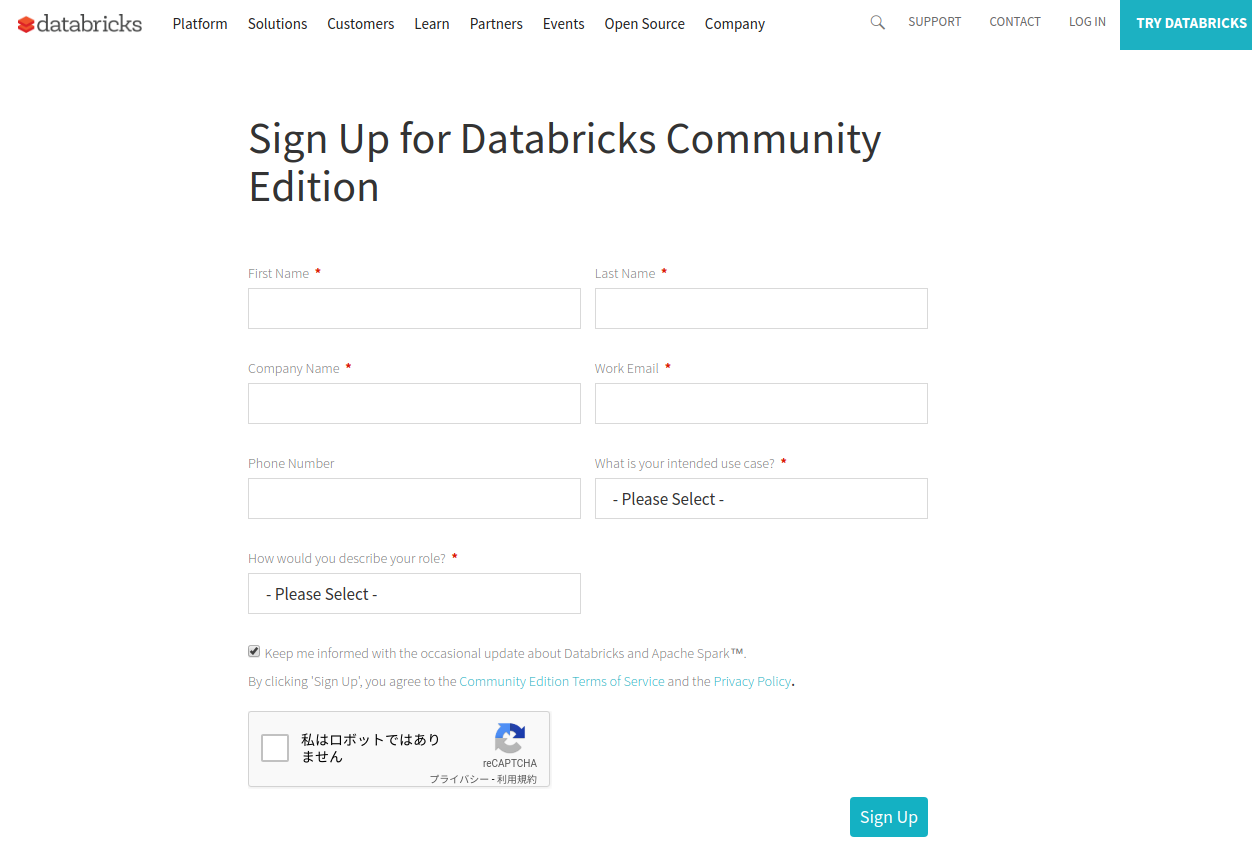
必須入力項目は下記のものです。
First Name … 名
Last Name … 姓
Company Name … 会社名
Work Email … 会社のEメール. ここにメールアドレス確認用のリンクが記載されてメールが来る
What is your intended use case? … コミュニティエディションの利用目的
How would you describe your role? … 職種
以上を入力して、reCAPTCHAの「私はロボットではありません」をチェックしたら、「Sign Up」ボタンを押して送信します。
メールアドレスを確認する
しばらくすると、「Welcome to Databricks! Please verify your email address」という件名のメールが届きます。
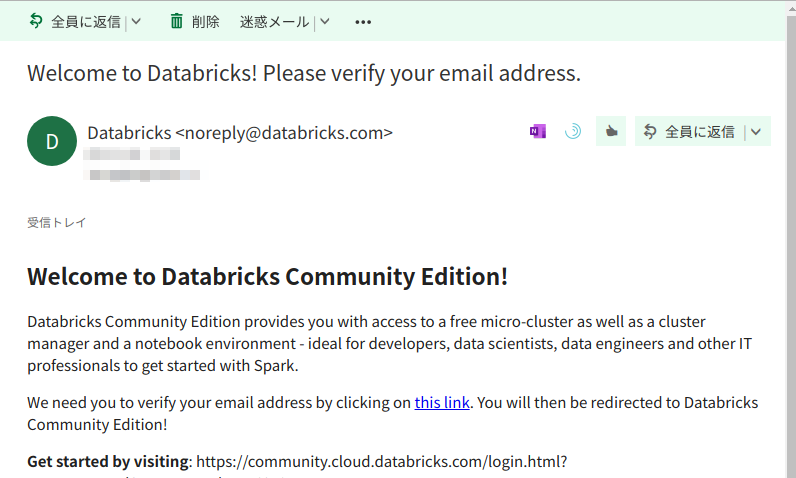
メール内のリンクをクリックするとユーザー登録完了です。
Databricks Community Editionにログインする
以下のログイン画面から入ります。
https://community.cloud.databricks.com/login.html
クラスターを作る
まずはSparkを実行するためのクラスタ(VM)を作成します。
左のメニューから[Clusters] > [Create Clusters]を開き、クラスター作成画面を開きます。
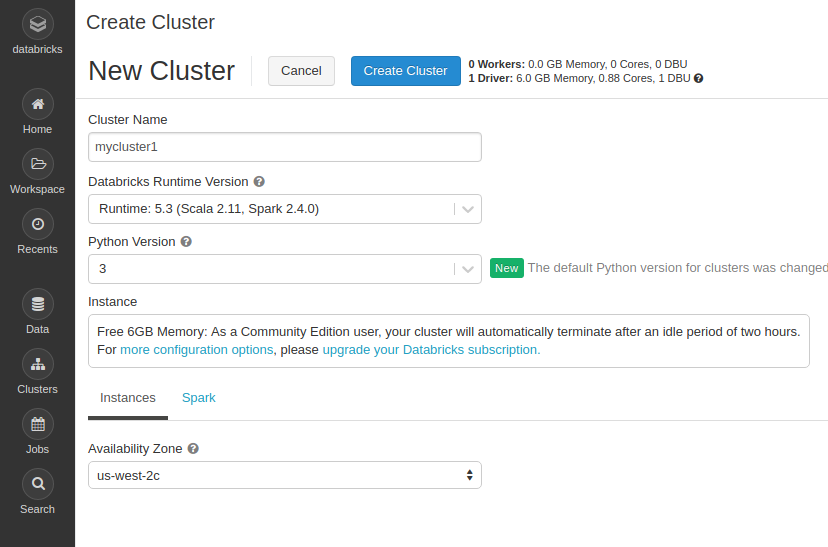
下記の情報を入力します。
選べる項目は少ないので、適当にクラスタの名前をつけて、クラスタをデプロイするAZをus-west-2リージョンの中から選んで作成します。
しばらくするとクラスタの状態が「Running」になるので、これで利用可能になりました。
※Community Editionでは、2時間操作がないクラスタは自動で停止します。
データセットをアップロードする
次に、今回テストで使うデータファイルをアップロードします。
今回はSparkのチュートリアルでよく使われるデータセットを利用します。
grouplensというサイトで公開されている、映画のレビュースコアのデータを使います。
MovieLens 100K Dataset
約1,000人のユーザーによる、およそ1,700作品の映画のレビュースコアが10万件格納されてるというCSVファイルを使います。
上記リンク先から「ml-100k.zip」というファイルをダウンロードして解凍します。

zipファイルの解凍して、その中の「u.data」というファイルをDatabricksにアップロードします。
左のメニューから [Data] > [Add Data]を開きます。
下記のような画面が開くので、[File]のボックスに先程の「u.data」ファイルをドラッグ&ドロップします。
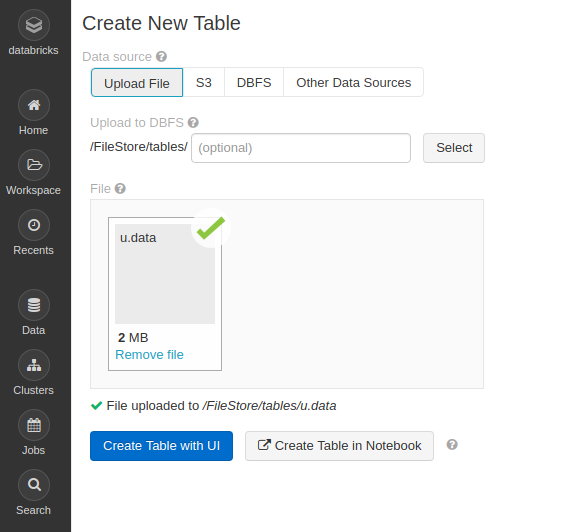
「File uploaded to /FileStore/tables/u.data」というメッセージが出ればアップロード完了です。
※ここからテーブルを作る事も出来ますが、今回は作りません。
レビュースコアをカウントする
それではノートブックを開いて先程のデータセットを分析します。
左のメニューから[Workspace] > [Create] > [Notebook]を選びます。
下記のダイアログが出るので、ノートブックの名前をつけて、[Create]をクリックします。
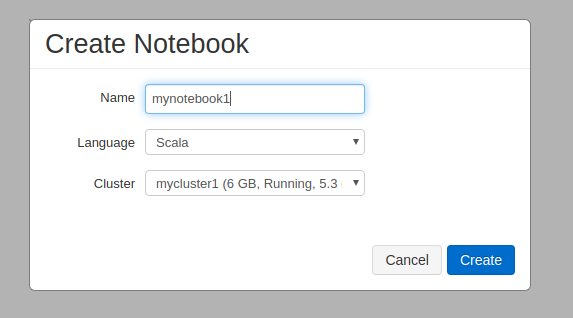
これでノートブックが開きます。
ここのテキストエリアにScalaコードを入力してSparkを実行していきます。
ここでは簡単に先程の「u.data」の集計を行います。
ファイルの中身はこのようになってます。
user id | item id | rating | timestamp
という順番でデータが並んでるのですが、今回は3番目のスコア(1〜5の5段階)だけを使います。
ササっと、「各スコア毎の件数」をカウントします。
このようなScalaコードを書いて実行します。
//ファイル読み込んでSparkのRDD形式にする val lines = sc.textFile("/FileStore/tables/u.data") //タブでsplitして3番目のカラム(ゼロベースで2番目)を取得 val rates = lines.map(x => x.toString().split("\t")(2)) //各スコア別にカウント val results = rates.countByValue() //多い順でソート val sorted = results.toSeq.sortBy(_._2).reverse //出力 sorted.foreach(println)
これの実行結果はこうなります。
(4,34174)
(3,27145)
(5,21201)
(2,11370)
(1,6110)

4点が34,174件で一番多いという結果になりました。
というわけで、こんなに簡単に無料Sparkを実行出来る環境が手に入った訳です。
ぜひ、Databricks Community Editionを使って気軽にSparkを始めましょう!
弊社はデジタルマーケティングからビッグデータ分析まで幅広くこなすデータ分析のプロ集団です。
お問合わせはこちらからどうぞ。
ブログへの記事リクエストはこちらまでどうぞ。