Google ColabでPyTorchを触ってみる
まずはGoogle Colaboratoryを用意します。
用意ができたら早速コードを実行して、挙動を確認していきましょう。
※今回主に参考にした記事はこちらです。
'''ライブラリの準備'''
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
機械学習に必要なライブラリやパッケージを取り込みます。
「####### as 〇〇」とすることで名前を簡略化しコードを描きやすくしました。
'''学習用データセットの準備'''
x_train = np.array([3.3, 4.4, 5.5, 6.71, 6.93, 4.168, 9.779, 6.182, 7.59, 2.167, 7.042, 10.791, 5.313, 7.997, 3.1], dtype=np.float32)
y_train = np.array([1.7, 2.76, 2.09, 3.19, 1.694, 1.573, 3.366, 2.596, 2.53, 1.221, 2.827, 3.465, 1.65, 2.904, 1.3], dtype=np.float32)
x_train = x_train.reshape(-1, 1)
y_train = y_train.reshape(-1, 1)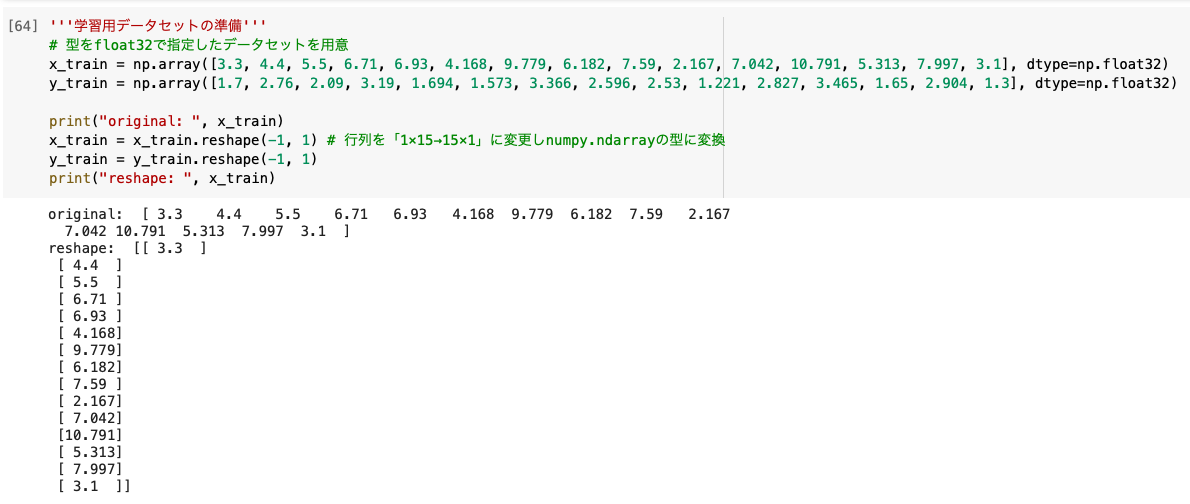
今回は手動でデータセットを用意しました。
reshapeで学習用データを縦持ちにし、型をfloat32にすることで今回のモデルが利用できます。
ちなみにreshape(-1, 1)はreshape(15, 1)と同じ意味です。
'''ハイパーパラメータの定義'''
input_size = 1
output_size = 1
num_epochs = 100
learning_rate = 0.002
ハイパーパラメータとは機械学習の設定のことです。
変数の名前は任意ですが、自分がわかるように中身を推測しやすい名前にします。
input_size, output_sizeは後ほど作成するクラスで使う変数で、それぞれ入力・出力の数を表します。
エポック数とは「1つの訓練データを繰り返す回数」のことで、少なすぎると学習の精度が低く、多すぎると*過学習に繋がります。
*過学習:訓練データを学習しすぎて他の予期せぬ値に対応できない状態。汎用性が低い。
学習率とは「機会学習の最適化においてどのくらい値を動かすかというパラメータ」のことで、大きすぎると発散し、小さすぎると収束までが遅くなります。
'''モデルの定義'''
class LinearRegression(nn.Module):
def __init__(self, input_size, output_size):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(input_size, output_size)
def forward(self, x):
out = self.linear(x)
return out
model = LinearRegression(input_size, output_size)
PyTorchのモデルを作成する際は基本的にnn.Moduleを継承します。
__init__のコンストラクタ(一番初めに実行される処理)を定義する際、superを使うことでnn.Moduleの__init__を引き継ぐことができます。
superを使わずに__init__を書くと__init__が上書きされてしまうので注意が必要です。
*引数のselfは「自分自身」を意味するpython独自の決まり事です。慣れましょう。
nn.Linearの線形変換とはザックリいうと「ある値を受け取って計算した値を出力する」という計算の仕組みのことです。
そしてforward()の中身は通常、活性化関数activationなどが使われたりするのですが、今回は特に何もしないことにします。
modelは先ほど定義したクラスを用いるために使われます。
'''最適化手法の定義'''
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
MSELossは平均二乗誤差の損失関数のことです。
Optimizerは機械学習で損失関数の値をできるだけ小さくするパラメータ値を見つける手法(最適化)を指し、損失をゼロに近づけることで予測値と正解値の差を少なくします。
この最適化手法では「SGD」が最も標準的で、他には「Adam」などが有名です。
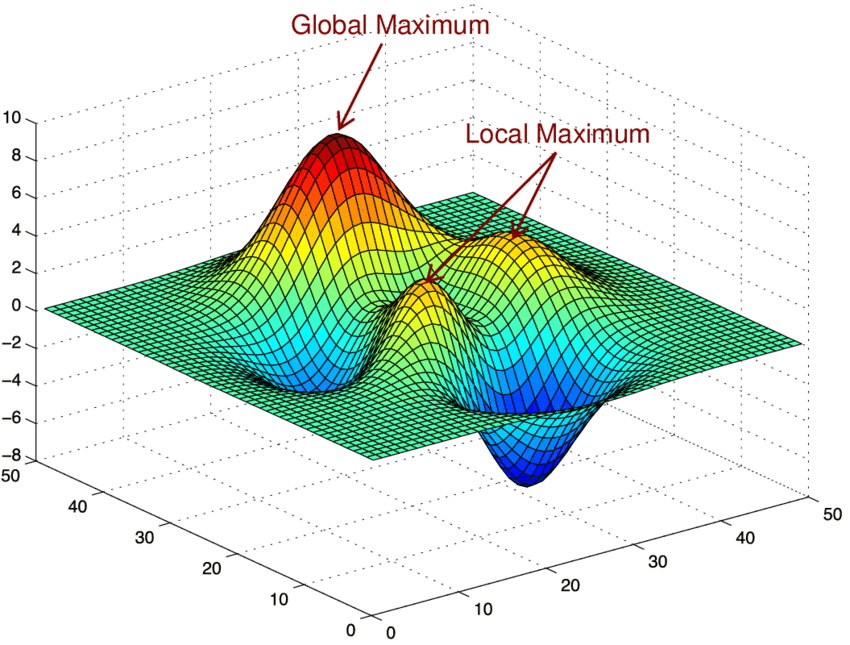
損失関数で計算した値を3次元上にプロットするとこのようになり「座標の傾き(微分値)を計算し損失が少ないパラメータを見つける」のが最急降下法です。(SGDやAdamはその派生)
*最適化手法・最急降下法について詳しく学びたい方はこちら。
'''学習'''
for epoch in range(num_epochs):
inputs = torch.tensor(x_train)
targets = torch.tensor(y_train)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print('Epoch [%d/%d], Loss: %.4f' % (epoch + 1, num_epochs, loss.item()))
torch.save(model.state_dict(), 'model.pkl')
PyTorchではエポックの繰り返し処理をforで実装するのが一般的です。
流れとしては「torch.tensor(データをtensor型に変換)」→「optimizer.zero_grad(各エポックで勾配をクリア)」→「正解値と予測値からlossを計算」→「loss.backward(各変数の微分値を計算)」→「optimizer.step(パラメータ更新)」で、学習後にはtorch.saveでモデルを保存します。
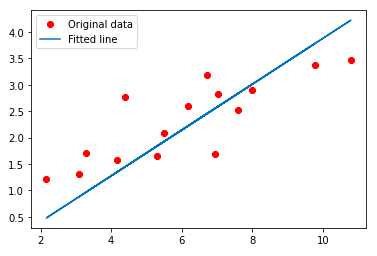
'''評価'''
predicted = outputs.detach().numpy()
plt.plot(x_train, y_train, 'ro', label='Original data')
plt.plot(x_train, predicted, label='Fitted line')
plt.legend()
plt.show()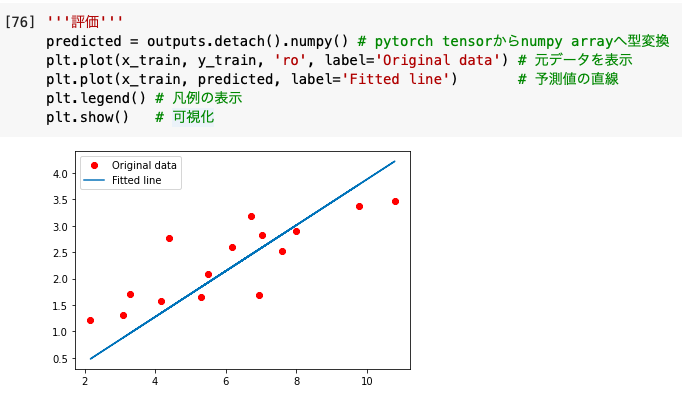
pytorch tensorだと勾配の情報が含まれており、matplotlibで可視化することができません。
そこでdetach().numpy()を使ってnumpy arrayへ型変換しました。
参考文献
人工知能に関する断創録
St_Hakky’s blog
Qiita – 学習率による動きの違いを確認する
IT-media PyTorch入門
Qiita – super()を使って派生クラスをinit
Optimizer入門&最新動向
Qiita – わかりやすい最適化アルゴリズム








この記事へのコメントはありません。