Snowflakeや最新データ基盤が広義のマーケティングにもたらす価値 in 2024

こんにちは、喜田です。
この投稿はSnowflake Advent Calendar 2024の3日目です。年末にありがちな1年の振り返り記事です。
振り返りの観点として、エクスチュアのお客様との会話や自身の経験などから、マーケティング領域やデータ活用領域でできること、これから盛り上がってくるであろう事を語りまくります。
長くなりそう( *´艸`) と思ったら超長文になったので記事内リンクをどうぞ
記事内リンク
私の2024年を3行で振り返り
転職でこの界隈にきてデータ領域2年生の私ですが、年初にSnowflake Data Superheroes 2024に選出いただいたこと、Snowflakeとコミュニティを中心にいろいろなことが腹落ちして楽しくなってきたキラキラ真っ只中、というのが今年のハイライトです。
Snowflakeでは年初から怒涛のリリースがあり検証しつづけてたり、Python & Streamlitの新参者としていろいろ教えてもらったり、コミュニティ運営に深く携わったり、Snowflakeきっかけでたくさんの経験を積ませてもらいました。雰囲気で見てきたデータマネジメント領域を学習し業務に活かしたり、Modern Data Stackを構成するSnowflakeと周辺ツールの仕事も経験できました。
そしてコミュニティで出会った人たちと会話する中で「RevOps」を知り、データ基盤周りで学んできた技術・機能が実用性としての意味を持ち、視界が開けたような感覚を持ちました。今なお勉強中ではありますが、そのような視点で見たときのSnowflakeやModern Data Stackがもたらす価値をまとめておきたいと思いました。
背景:RevOpsと広義のマーケティングとデータ基盤
デジタルマーケティングの支援で成長してきたエクスチュア
エクスチュアはデジタルマーケティング領域のデータ活用を支援する会社です。企業のサイト来訪・サイト内行動をGA4を使って計測したり、顧客に関する情報を一元的に集めて次のマーケ戦略に活かすCDP構築~運用コンサルなどが代表的です。
デジタルから広義のマーケティングへ
サイト計測ならGA4、顧客体験向上ならKARTE、CDPなら・・・と目的特化のマーケツールは多々あり、多くはツール内で収集したデータを分析・可視化できます。それをデータ基盤に集めることでツール横断・部門横断で社内のデータをフル活用できるように整える「ビッグデータ活用支援」にも注力するようになり、2023年頃から他のDWH製品と並んでSnowflakeを提案・実装するようになりました。(私はこのチームでデータ基盤インフラ寄りのことをやっています。)
このような領域では、デジマだけでない広義のマーケティングに関わることも増えてきます。教科書的なところで言うと、「プロモーション」だけがマーケではなく、企業の営業活動すべてがマーケティングであるということ。例えば製造プロセスを最適化することで価格転嫁を抑え競争優位にする。じゃあ製造プロセスの課題をデータドリブンに解決しましょう、みたいなことです。
トレンドはRevOpsへ、企業の利益を中長期で最大化するには
この夏ぐらいからデータ界隈でも耳にするようになってきたRevOps(レヴェニューオペレーション、レヴオプス)という言葉があります。
マーケ部門、セールス部門、プロダクト部門、顧客満足部門・・・が協調してトータルでの利益創出を最大化するように動きましょうという考え方です。そのためには、マーケが追うKPIはリードの数でなくセールスに渡ったあとに「商談につながるリードの数」だし、セールスが追うのは目先の売り上げではなく「顧客の要件にビッタリと合って顧客満足を最大化する成約」です。であれば、マーケが作ったリードはSalesforce上の商談ステータスでどう推移していくかまでウォッチしていたり、セールスは商談管理に終始するのではなくプロダクト部門やサポート部門(顧客満足部門)が持っている顧客からのフィードバックデータにも関心を持たなければなりません。
私や所属部門としては、Snowflakeの初期導入とかガバナンスの実践、要件通りにダッシュボードを作る案件は身近にやってきたのですが、RevOpsを勉強してふと顔を挙げてみると、弊社で取り扱っている様々なマーケツールやCX(顧客体験)のツールこそがRevOpsに重要なデータの生まれる場所であり、基盤構築案件で終わるのはもったいなく感じ、データそのものやクライアントの業務に踏み込んで考える良いキッカケになりました。
さて、そろそろSnowflakeやデータ基盤の話へ。
2024年のSnowflakeを振り返ると「Data Cloud」から「AI Data Cloud」にリブランディングして、AIエンジニアが業務用AIプロダクトを作るための機能を怒涛の勢いでリリースしましたね。この時代においてあるべき進化だと思いますが、パートナーの立場としてはAI案件のご提案ばかりというわけにはいきません。
データ基盤、RevOps(=全社のデータ活用をあるべき姿にする)の観点で、地に足着いた重要な機能もたくさんリリースしています。
【ポイント1】データ基盤へのデータ集約を強力に後押し
業務ごとに生まれ散在するデータをデータ基盤に統合するために、従来ETLが担ってきた領域に転換が起きています。キーワードとしては最新~今後も主流というところで
- ZeroETL
- Native Connector
- Modern Data Stack
あたりでしょうか。
ZeroETL
そもそもSnowflakeが提供してきた、Snowflake同士でデータファイルそのものをシェアして組織間でデータを利用できることをZeroETL(データ転送にかかるETLジョブ開発、データ中継場所やコンピュートリソースが不要)と解釈していたのですが、2024年頭にはSalesforce Data CloudとのZeroETL連携が発表され驚きと期待に胸が高まりました。直近ではSnowflakeのデータをAWSのデータと掛け合わせで分析できるData Clean Roomも発表されていますね。
SaaS間で共通フォーマットでデータを保持し、一方で更新されたものをリアルタイムに他方で見ることができる。特にローコードアプリ開発の視点でSalesforceを見ると、テーブル定義などETLジョブ定義に影響しそうな変更があってもデータファイルそのものを見てるのでそれすら影響なしというのは非常に有益です。
ところで、マルチプラットフォーム間でのInteroperability(相互運用性)を実現するIcebergも話題ですが、個社単位で使いこなすのはまだ様子見かな~などと思っております。(使いどころはRAKUDEJI前田さんが解説してくれています。ご指摘歓迎でございます。。。)各社の開発が隆盛な今、仕様変更に追従しなければならないことを考えると、個社のシステム実装をそこに依存して作りこむのはリスキーかなと。とはいえこういった低レイヤーの技術が進歩し、ZeroETLのようなサービス化されたものが出てくることには大いに期待しています。この先しばらくは次々と各社のリリースが続くと思うので、ベンダー側としてはもちろん注目して追いかけていく所存です。
Native Connectors
この流れでもう一つ触れておきたいのがSnowflakeのNative Connectorsです。このジャンルへの期待も込めて、ということで。
フロントの業務アプリケーションやSaaSで生まれたデータをSnowflakeに取り込む手法はいくつもありますが、Native ConnectorsはSnowflakeが標準提供している「データソースに特化してリアルタイム同期を実現」する機能です。2024年時点ではRDB(PostgreSQL、MySQL)とGA4、ServiceNow、逆向きではLooker Studioがリリース済です。
PostgreSQLやMySQLはショートトランザクションの同時実行に優れたRDBで毎秒大量の更新を受け付けることができます。一方Snowflakeの更新はバッチ型に向いており、更新ごとにリアルタイムに同期をとることは現実的ではありません。対策としては5分間隔とかで変更された差分をドカッとSnowflakeに持っていくことですが、これを手で実装するのはまあまあ骨が折れます。RDB側でアプリ的に更新差分を追うには前回同期したタイムスタンプ以降のデータをクエリするなど、本番稼働しているRDBに本業でない範囲検索をさせる余分な負荷をかけることになります。(業務DB管理者は余計な負荷増にものすごくシビアです!!!)
これをPostgreSQLやMySQLが標準機能としてもっているレプリケーション機能で、(下流スタンバイのフリをして)変更履歴ファイルから差分を受信し続けるのがDatabase Connectorです。データソースに特化と書いたのはそのためで、このコネクタのコードはPostgreSQLやMySQLのレプリケーションプロトコルに則って作られているのです。ちなみに連続的に受信はしますが、Snowflake側への反映はSnowflakeにとってパフォーマンス最適となるよう「準リアルタイム」です。
業務DB側からみると、慣れたレプリケーションのスタンバイが1台増えるぐらいの扱いで、性能影響の見えない謎クエリが流れることなく、Snowflakeとも異なる第三の野良SaaSからのアクセスが増えることもなく要件に応えてあげられます。
これで、ZeroETLとは遠いところにある自社データベースからもデータ基盤への準リアルタイムなデータ同期が実現できます。
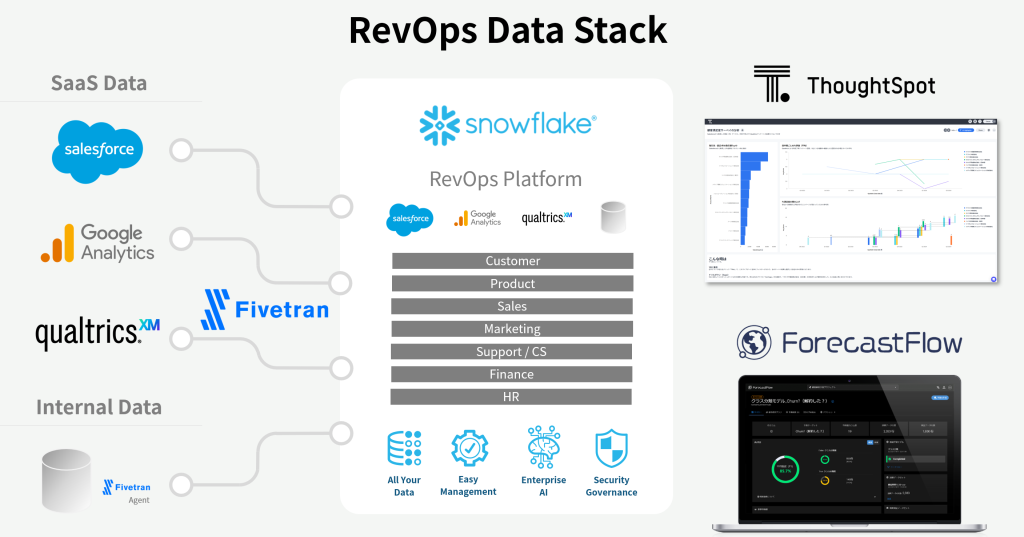
Modern Data Stack(Snowflake以外を含むSaaS Connectorsとしての価値)
最新技術ではないものの、今年、私自身は初めてFivetranを実業務で触る中で改めて感じているのが結局Modern Data Stackと言われてきたのはここが強いゆえだな、と腹落ちしましたという話です。
マーケ、セールス、カスタマーサクセス・・・多様な業務のためのSaaSが溢れ、各領域は便利になっているが、社内で横断的に活用しきれないデータが散在している現状に対して、RevOpsを実現するにはFivetranが備えるConnector+Transformationsがものすごく効いてくると見ています。
目的特化のSaaSでは、標準的な使い方の範囲で集まるデータはどのユーザー企業にとっても同じくデータモデル化することができるはずです。では、ConnectorでSnowflakeに連携したデータを集計・分析しやすいようにTransformまでも定めてしまいましょう、と提供されてるのがFivetranのQuickStartモデルです。さらにカスタマイズを可能にするdbt連携機能もあります。
前述のSnowflake GA4 Connectorもそうですが、決まったデータソースに対しては決まったモデル化ができれば有益なケースは多く、ポチッとして気づいたら分析Readyなデータが揃っていた!がRevOpsの推進には超重要になります。
RevOpsのための基盤を作りたいんじゃない、RevOpsの施策をまわしたいんだ!
ということで、特に上流の設計をされる皆様におかれましては「集めたデータをどう活用するか?」のほうに目を向けていかなければなりません。データ基盤側ベンダーが提供するべきプロダクト機能はこの2024年に揃ったといっても過言ではありません。
ここで言う「データをどう活用するか」のヒント
システム面でデータ連携が容易になる話をしてきましたが、じゃあその集めたデータから有益な知見を引き出すには実はもう一工夫が必要です。ここからがRevOpsエンジニアの腕の見せ所になると思って私も日々勉強しているところなのですが。
SalesforceのAccount(取引先)やOpportunity(商談)と、そっちのデータは紐づけできるか?
そっちってどっちやねんな見出しですが、そういうことです。
商談の結果として提供した商品やサービスの評価(アンケートやサポートログによるフィードバック)は、ちゃんと商談IDと紐づいていますか?アンケートツールで評価をもらう際に、商談IDを埋め込んでおくことで、データ基盤に集めて結合し分析に使うことができます。
Salesforceで管理している年間取引額のレンジでアンケート評価を分類したり、セールスチームで定める重点顧客に対してサポート対応ログをAIでサマリして次の提案につなげるなどが考えられます。
GA4のアクセスログは他のデータと紐づけできるか?
日々サービス利用してくれているエンゲージの高いユーザーと、非ログインだけど繰り返し見てくれている人が同じアクセス傾向であれば、有償プランに加入して良いユーザーに育ってくれる可能性が高いです。そういう人にクーポンを蒔きましょう。で、答え合わせをしましょうなんですが、あの人(Cookie)がこの人(ログイン後のメアド)といつでも完全には一致しないのでどうするか?
Cookieやトラッキングとログイン後のアカウントの名寄せであったり、ユーザー行動から属性付けして、同じ属性の人に対するアプローチ(個を特定しなくても一定の効果がでるアプローチ)を考えます。
こんなことを、あらゆる業務にフィットして理解していくことが重要になってきそうです。マーケター経験のない人がマーケのデータや用語を理解して、営業のためのデータとつなぐ・・・となるとハードルが高く感じますが、データ基盤側の機能が揃った2024年は高速道路が敷かれたぐらいのインパクトがあると思っています。ぜひ一緒に勉強していきましょう~~~。
【ポイント2】ビジネスパーソン向けのデータ活用の出口を考える
データを活用して業務に役立てる人(=ビジネスパーソン、つまり営業、マーケター、経営層などなど)にとって、いままでのデータ基盤はまだ単なるデータ置き場ではなかったでしょうか。ビジネスパーソンが見ているデータは、BIダッシュボードとして作りこまれた「アプリケーション」として仕上がったものでした。その状態で使えるようになるにはアプリ開発の工数がかかりリードタイムがあり・・・。
せっかくデータが一ヵ所に統合できたら、それを自由に縦横無尽に分析して、隠された知見を誰もが発見できる(隠れているので気づいて来なかったが、それを発見するチャンスがある)が理想ですよね。
そのためには、ショートスパンでデータドリブンな施策を実行しまくることだと思っています。なんらかの示唆らしきものを見て、業務に適用してみて、使えるか判断するの繰り返しですね。そのサイクルが早ければ早いほど正解を踏む可能性があがります。
その視点で注目しているのが
- Streamlit / Notebook
- ライブダッシュボード
- AutoML
です。もっといろいろなツールがあるかもしれませんが、今年仕事や検証で関わったプロダクトと共に紹介します。
SnowflakeのStreamlitとNotebook
Snowflake界隈では今さら感がありますが、StreamlitとNotebookはビジネスパーソンとデータを結びつける最強の入り口になってくれると確信しています。
私自身、Python1年生でStreamlitやNotebookのおかげで重い腰をあげて学習し始めたのが今年の頭だったのですが、可視化も機械学習も生成AIも見よう見まねで動くものが作れるようになりました。高速道路を超えてリニアモーターカーばりの手段が来たような感じです。とはいえここでは非エンジニアもそのぐらい勉強すれば使えるよ、というつもりはなく。
1時間の打ち合わせ1回で「とりあえず動くもの」を提供できる
ビジネスサイドからの要求で「こういうデータない?」「こういう分析(BI上で)したいんだけど」に対して、100点回答するにはかっちり要件定義して開発期間をn週間見込んで・・・が必要でした。StreamlitやNotebookのおかげで、コード書ける人にとってはほぼ会話のスピードで「こういう分析したい」に対する30点の仮見せして「もうちょっとこうして」の会話からスタートできるようになりました。60点位まで育ったら業務適用してみて、当たりなら本格システム化を検討し、全営業が見るためのツールとして作りこむといった判断、外れならその時点でアプリ実装も中断でも良いのです。
ThoughtSpotのライブダッシュボード
「自由に縦横無尽に分析して、隠された知見を誰もが発見できる」を全社に浸透させるために、大げさでなく10年早めるのがThoughtSpotだと思っています。クエリ生成のアルゴリズム(≠AI)と生成AIを組み合わせて、100%精度のクエリ生成をして期待する分析ができます。Excelで何かしらのグラフを作った経験があれば十分使える可視化機能と、Tableauで値を作りこむような詳細な数式の定義、得られた結果の説明・考察を助けるAIチャット機能を持っています。
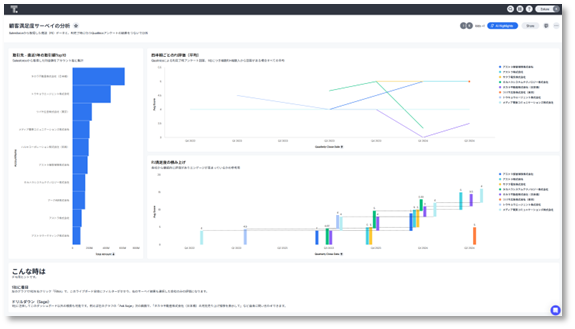
こちらも操作慣れしたエンジニアであれば1時間の打ち合わせで業務サイドの要望を簡単なダッシュボード化できます。さらに日々の業務で新たな疑問が出てきたら今度は利用者が自身で追加質問を投げかけ、新たなグラフを出力しピン留めして、ダッシュボードを育てることができます。お隣のチームで上手く使われてるダッシュボードをこっちでも真似する、といったこともできます。データ+数式でビジネス上の意味を反映しておくセマンティックレイヤーに期待する機能や、値やダッシュボード自体を自然言語で検索できることから、データカタログ的に全社データの入り口として浸透するポテンシャルがあります。
組織間のデータ活用に対する出口ツール
RevOpsの実践にあたって組織をまたいだデータ活用が期待されます。マーケのデータは営業部が持っているデータとどう繋がるでしょうか?サポート部隊が持っているデータだったら?マーケチームのイチ担当者が他部署のデータを理解することから始めるよりも、とりあえず検索して知見らしきものが見える。「こういう分析始めてみたんだけど」を一緒に見ながら「だったらこの値のほうがいいよね」と会話すると捗りそうです。
ForecastFlowで超簡単AutoML
AutoML、使ってますか?日々Excelと睨めっこして業務課題に対して打ち手を考えている皆様にぜひ触ってみて欲しいと思っています。機械学習というと非エンジニアにはハードルが高い感じがしますが、ほぼボタンクリックだけで学習と特徴量に対する考察、予測や分類の結果を得ることができます。
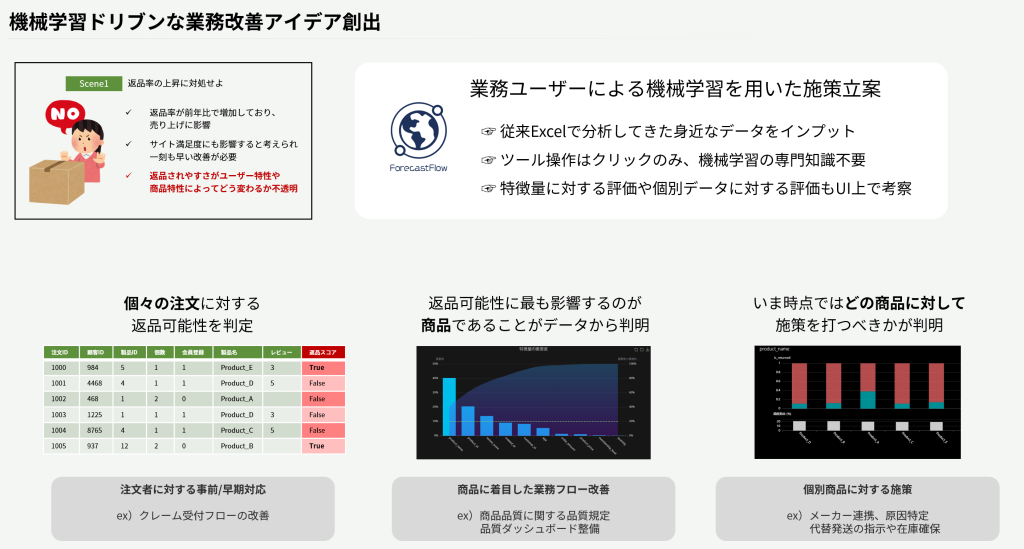
どんなシーンで使えるか、ビジネスパーソンが使いこなすにはどんな準備が必要かをセミナーで話しています。興味のあるかたは是非リンク先もご覧ください。
【ポイント3】2025年はDCR元年になるか?外部データ活用の本格到来へ!
エクスチュアでは、2023年からデータクリーンルーム(DCR)についてSnowflakeの製品機能面での情報発信をしてきました。
いきなり例え話ですが、スーパーで食品メーカーの商品の購入者がいて、その個人に関するデータはメーカーにどう理解されるべき(または理解されないべき)でしょうか。個人的には、どのような人がどのような買い物をしているのか、メーカーが理解してくれて、大いに活用されるべきと思っています。そうすればもっと消費者ニーズにマッチした商品が生まれ、「私が欲しい商品」がおススメされ手に入る可能性が高くなります。ここで例に挙げたスーパーですが、真に顧客データを捉える接点となるのはポイントカードであったり決済サービスであったりします。
DCRの本質は、①顧客接点のあるところにデータが蓄積していること、②そのデータは顧客に価値を提供しうるメーカーにとって超重要であること、③その橋渡しをする機能をDCRがもっていることです。
このような分析において「どのような人がどのような買い物を」は個人を識別する必要はなく、有益な属性を切り出して「20歳代でxxxな嗜好の人が手に取りやすい」のような分析できることが価値です。
生活に密着して利用されているポイントサービスの膨大なデータからこのような属性を取り出すことはAI/MLの領域で、ここ数年の進化もあってより高精度でニッチな属性付けがされるようになると、さらに有益な情報としてメーカーに渡り関心の高い商品やサービスの開発に役立ってくれると信じています。
RevOpsと外部データ活用
さて、RevOpsでは企業内の様々なデータを活用しますが、その中には当然「カスタマー」のデータも含まれます。マーケティング文脈では広告配信の最適化などのために外部データを使ってCDPを充実させてきたのですが、このカスタマーデータはRevOpsにおいては顧客フィードバックであり商品開発などにもこれまで以上に活かされることになります。この価値は広告のROIだけでは測れないものです。
極論ですがそのカスタマー(スーパーでの購入者)のデータは世の中に確かに存在して、誰か(ポイントサービス)は持っているデータなので「集められるものはぜんぶ集める」その先でどう使えるか考えるのも面白いんじゃないかなと思います。
一方でデータプロバイダーについては、2024年にいくつかDCRサービス開始のニュースリリースや検証記事が出ています。(実装がSnowflakeまたは他プラットフォーム依存かなど非公開も含め)
提供者が自社データの価値をしっかり認識して、「そのデータでどんな価値が提供されるか」「法律やコンプラに対してどのような対応が必要か」などコンシューマー(受信者)に説明されていくでしょう。3rd Party Cookieベースだったり、ルールに則ってデータ授受してレポートビジネスを展開されてきたその道の専門のプロバイダー企業が描くDCRでどんな未来が出来上がるか非常に楽しみです。
終わりに:RevOpsと「Data to the People」
エクスチュアの企業理念「Data to the People」すべてのビジネスパーソンがデータを使いこなし、それは一般の消費者向けに提供される様々なサービスで世の中を便利にすることにつながり、すべての人がデータの恩恵を受けることにつながります。
企業がRevOpsによって利益を得ることは、短期的な売上をあげることではなく、ユーザーに求められるサービスやプロダクトを作り、ユーザーに選ばれることを意味します。そして、その実現には組織横断でデータを活用できていること、データ基盤のあるべき姿が整えられていることが鍵になりそうです。
エクスチュアではこれまでのマーケティング、ビジネスのための各種SaaSプロダクトの知見と、データ基盤構築やデータ活用に携わってきた経験を活かしてRevOps実現のためのご支援を提供します。