LangChainって何?: 次世代AIアプリケーション構築 その3

こんにちは、エクスチュアの石原です。
こちらは第3回の記事になっております。前回、前々回の記事をお読みになっていない方は、ぜひ併せてご確認ください。
LangChainのクイックスタートを実施していく「LangChainって何?」シリーズも今回で最後となります。前回の記事では現在のLLMのトレンドとなっているRAGやAgentについてご紹介させていただきました。ここまでの内容でアプリケーション開発の基礎となる部分は確認できました。
いよいよ最終回となる今回は作成したアプリケーションをAPIとして提供するにあたって便利なLangServeとアプリケーションのテストに役立つLangSmithをご紹介します。
今回の記事ではサーバーの構築を行うため、ローカル環境でのpythonで処理を実施していきます。
LangServe
LangServeは開発したLangChianチェーンを簡単にREST APIとして公開することが出来ます。
REST APIとは、ウェブアプリケーションやサービス間でデータを効率的に交換するためのプロトコル定義です。REST APIのアプリケーションは以前実行した状態に依存せず、クライアントとサーバ側が完全に独立しているという性質を有しています。そのステートレスな性質とシンプルなインターフェースにより、REST APIで提供されたサービスは開発者やユーザーにとって扱いやすいアプリケーションです。
それではここまでに作成してきたLangChainアプリケーションを公開していきましょう。
まずはインストールを行います。
pip install "langserve[all]" langchain langchain-openai beautifulsoup4 langchainhub
次にアプリケーション用のサーバーを作成するには、serve.pyファイルを作成します。このファイルではアプリケーションを提供するためのロジックとして以下の 3 つで構成されています。
- 構築したチェーンの定義
- FastAPI アプリ
- チェーンにサービスを提供するルートの定義。(
langserve.add_routes)
#!/usr/bin/env python
from typing import List, Union
from fastapi import FastAPI
from langchain import hub
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.pydantic_v1 import BaseModel, Field
from langchain.tools.retriever import create_retriever_tool
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_community.vectorstores import FAISS
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langserve import add_routes
# 1. Load Retriever
url_list = ["https://docs.smith.langchain.com/user_guide","https://python.langchain.com/docs/langserve","https://python.langchain.com/docs/get_started/introduction"]
docs = []
for url in url_list:
loader = WebBaseLoader(url)
docs.extend(loader.load())
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings()
vector = FAISS.from_documents(documents, embeddings)
retriever = vector.as_retriever()
# 2. Create Tools
retriever_tool = create_retriever_tool(
retriever,
"langsmith_search",
"LangSmithに関する情報を検索。LangSmithに関するご質問は、こちらのツールをご利用ください!",
)
search = TavilySearchResults()
tools = [retriever_tool, search]
# 3. Create Agent
prompt = hub.pull("hwchase17/openai-functions-agent")
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 4. App definition
app = FastAPI(
title="LangChain Server",
version="1.0",
description="LangChainのRunnableインターフェイスを使ったシンプルなAPIサーバー",
)
# 5. Adding chain route
# We need to add these input/output schemas because the current AgentExecutor
# is lacking in schemas.
class Input(BaseModel):
input: str
chat_history: List[Union[HumanMessage, AIMessage, SystemMessage]] = Field(
...,
extra={"widget": {"type": "chat", "input": "location"}},
)
class Output(BaseModel):
output: str
add_routes(
app,
agent_executor.with_types(input_type=Input, output_type=Output),
path="/agent",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
Agentの部分をこれまでに作成してきたChainに置き換えて以下のコマンドで実行してみてください。(Quickstartに記載のコードだとchat_historyが読み込まれない問題があったので一部修正)
python serve.py
実行するとlocalhost:8000でサーバが立ちあがっていることが確認できます。
http://localhost:8000/agent/playground/にアクセスしてChainの実行を確認してみてください。
アクセスすると下記の画像のようなUIが構築されています。
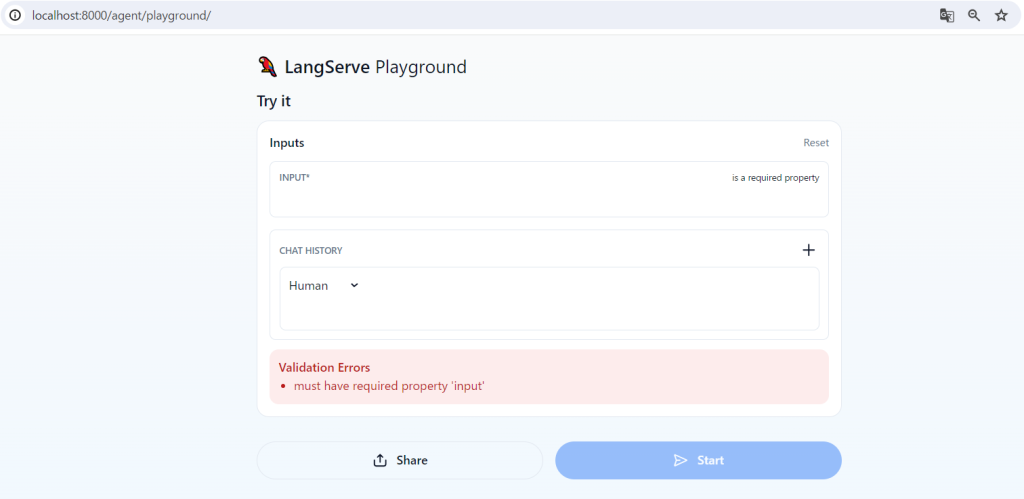
これまでに作成してきたアプリケーションと同じ動作をすると思います。
次にクライアント側での処理を作成してみます。client.pyファイルを作成してみましょう。
from langchain_core.messages import AIMessage, HumanMessage
from langserve import RemoteRunnable
remote_chain = RemoteRunnable("http://localhost:8000/agent/")
chat_history = [HumanMessage(content="LangSmithは私のLLMアプリケーションのテストに役立ちますか?"), AIMessage(content="Yes!")]
response = remote_chain.invoke(
{
"input": "どのように役立ちますか?",
"chat_history": chat_history,
}
)
print(response)
これを使用すると、クライアント側で定義・実行されているかのように、LLMChainと対話できます。
{'output': 'LangSmithはLLMアプリケーションの開発、モニタリング、テストに役立ちます。以下はLangSmithがどのように役立つかの概要です:\n\n1. プロトタイピング:LLMアプリケーションのプロトタイプ作成では、プロンプト、モデルタイプ、検索戦略などのパラメーターを素早く実験することが重要です。\n2. デバッグ:LangSmithのトレ
ース機能を使用することで、アプリケーションの開発中に問題を特定し、デバッグすることができます。\n3. 初期テストセット:LangSmithを使用して、LLMアプリケーション
のテストケースを作成し、テストを実行することができます。\n4. 比較ビュー:異なるバージョンのアプリケーションを比較し、テストケースの結果を確認できます。\n5.
プレイグラウンド:LangSmithは迅速な反復と実験を可能にするプレイグラウンド環境を提供します。\n6. ベータテスト:実世界のシナリオでのアプリケーションのパフォー
マンスを収集し、フィードバックを収集します。\n7. フィードバックの収集:ユーザーからのフィードバックを収集し、問題のあるトレースを特定します。\n8. トレースの
注釈付け:注釈者が興味深いトレースを検査し、異なる基準に基づいて注釈を付けることができます。\n9. データセットへのランの追加:アプリケーションがベータテスト段
階を進むにつれて、ランをデータセットに追加して実世界のシナリオでのテストカバレッジを拡大します。\n10. プロダクション:アプリケーションのパフォーマンスを監視
し、重要なデータポイントを詳細に調査します。\n11. モニタリングとA/Bテスト:LangSmithはモニタリングチャートを提供し、A/Bテストをサポートします。\n12. オートメ
ーション:LangSmithのオートメーション機能を使用して、トレースを自動的に処理し、評価します。\n13. スレッド:LangSmithは複数のターンを持つLLMアプリケーションを
サポートし、トレースをグループ化して追跡しやすくします。\n\nこれらの機能を使用することで、LangSmithはLLMアプリケーションのテストに役立ちます。'}
これで、LLMを使用したREST APIアプリケーションを公開することが出来ました。こちらをWeb上に公開する場合は各種クラウドサービス上にデプロイするという方法があります。詳細についてはこちらをご参照ください。
LangSmith
LangsmithはLangChain社LLMOpsツールです。 Langsmithを使用するとLLMに送信されているプロンプトの管理などが簡単になります。また、アプリケーションへの実装も非常に簡単です。
使用するためにはLangChain社のアカウントが必要です。アカウント作成はこちら。
アカウント作成し、ログインすると以下のような画面になります。
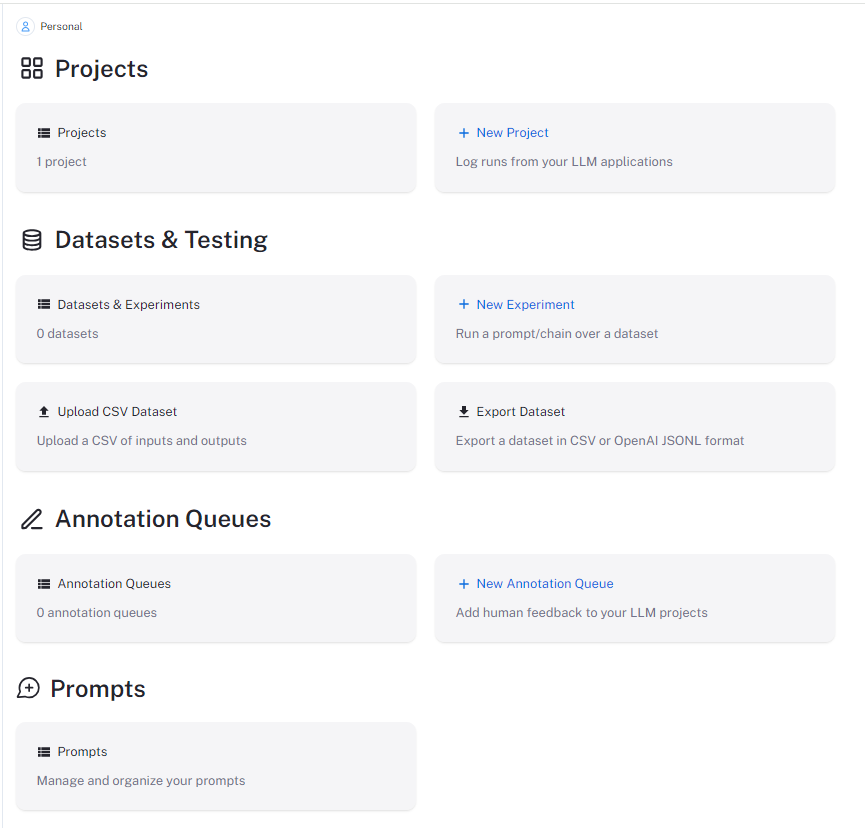
langsmithを使用するためにはkeyが必要になります。サイドバーのSettingsよりCreate API Keyを選択し、鍵を作成してください。
作成した鍵とトレースの設定を環境変数に設定します。
LANGCHAIN_TRACING_V2=true
LANGCHAIN_API_KEY={作成した鍵を記載}
その他の設定がなければdefaultプロジェクトに以下のような実行履歴がトレースされるようになります。この履歴にはユーザーがインプットした内容に加えて実行に使用したプロンプトや履歴などの情報も含まれており、LLMの生成に影響を与える情報が漏らさずに含まれているので、複雑なプロジェクトになるほどより便利に感じるようになるかと思います。
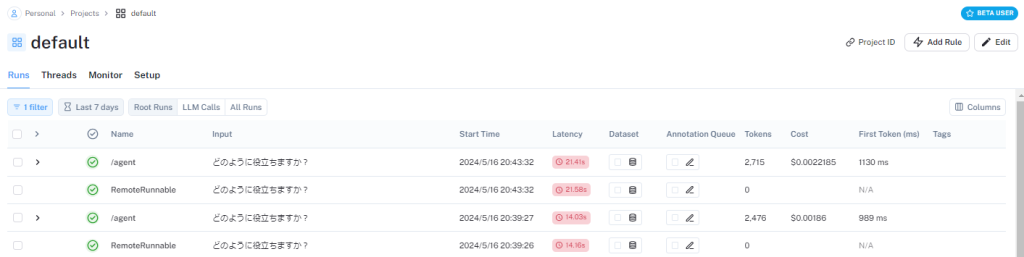
それぞれを開くと以下のように入力されたデータとその出力が確認できます。

LangSmithに関しては検証やテストにも使用できる機能が存在しています。さらなる機能についてはウォークスルーの内容も確認していただけると良いかと思います。
まとめ
本記事ではアプリケーションの運用を行う上で役立つLangServe、LangSmithについてご紹介しました。ここまでの全3回の記事でLLMを使用したアプリケーション開発は実施できるようになったのではないでしょうか。今回ご紹介した内容の詳細については公式ドキュメントをどうぞ。
第1回からご覧になっていただいた方がいましたら厚く御礼申し上げます。
シリーズは最後ですが、今後もLangChainのアップデートやLLMの最新ニュースをご紹介していく予定ですので、どうぞご注目ください。
エクスチュアはマーケティングテクノロジーを実践的に利用することで企業のマーケティング活動を支援しています。
ツールの活用にお困りの方はお気軽にお問い合わせください




