わかりやすいPyTorch入門⑤(CNNとデータの拡張)

CNNとデータの拡張
データの拡張とは
今回は前回学んだCNNの練習に加え、データの拡張について学んでいきます。
ここでいうデータの拡張とは「データをランダムに回転、左右反転、拡大縮小」させることを指します。
データを拡張させることで「訓練データの量を増やしモデルの精度を高める」ことができるのです。
データセット
扱うデータセットはCIFAR10(スィーファーテン)という6万枚のカラー画像です。
MNISTは手書き数字の白黒画像でしたが、CIFAR10は動物や車など多くのカラー画像が入っているので、より楽しみながら学習できるかと思います。
では、早速コードを書いていきましょう。
CNNでCIFAR10の画像を分類
内容はデータの拡張以外ほとんど前回の記事と同じなので、今回は大幅に説明をカットします。
'''ライブラリの準備'''
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
'''GPUチェック'''
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
'''ハイパーパラメータの宣言'''
num_epochs = 20
batch_size = 128
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
transform = transforms.Compose([
transforms.RandomAffine([0,30], scale=(0.8, 1.2)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
まず、今回のモデルで行う画像の前処理をtransform.Compose()内で記述します。
・RandomAffine([回転角], scale=(拡大/縮小)):画像の回転、拡大/縮小
・RandomHorizontalFlip(p=確率):確率pで画像を左右反転
・ToTensor:画像データをtensor形式に
・Normalize(平均, 標準偏差):平均と標準偏差を決めて正則化
※今回はNormalizeで平均と分散を「0.5」としました。正則化されたデータは「(元のデータ – 平均) / (標準偏差)」で求まるので、平均を0.5としたことで「元の0.5のデータは0」になり、標準偏差を0.5にしたことで「取り得る値の範囲を2倍」にできるというわけです。
今回は導入してませんが「RandomErasing()」で画像データの一部を削除することもできます。
PyTorchのDocsでは「torchvision.transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False)」という使い方が示されていました。
※p=確率, scale=画像をどの程度消すか, ratio=アスペクト比(縦横比), value=(R,G,B)値の変更など, inplace=画像を置き換えるか
'''Datasetの準備'''
train_set = CIFAR10(root='mydata', train=True, transform=transform, download=True)
test_set = CIFAR10(root='mydata', train=False, transform=transform, download=True)
'''DataLoaderを作成'''
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=4)
test_loader = DataLoader(test_set, batch_size=len(test_set), shuffle=False, num_workers=4)
DataLoaderについては以前紹介しているので、さらに知りたい方はこちらよりどうぞ。
'''データの確認'''
cifar10 = CIFAR10(root="mydata", train=False, transform=transforms.ToTensor(), download=True)
plt.figure(figsize=(7,7))
chkimages, chklabels = iter(DataLoader(cifar10, batch_size=4*4)).next()
for i in range(4*4):
plt.subplot(4,4,i+1)
label = classes[chklabels[i]]
plt.title(label)
t_chkimages = np.transpose(chkimages[i], (1, 2, 0))
plt.imshow(t_chkimages)
plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False)
plt.show()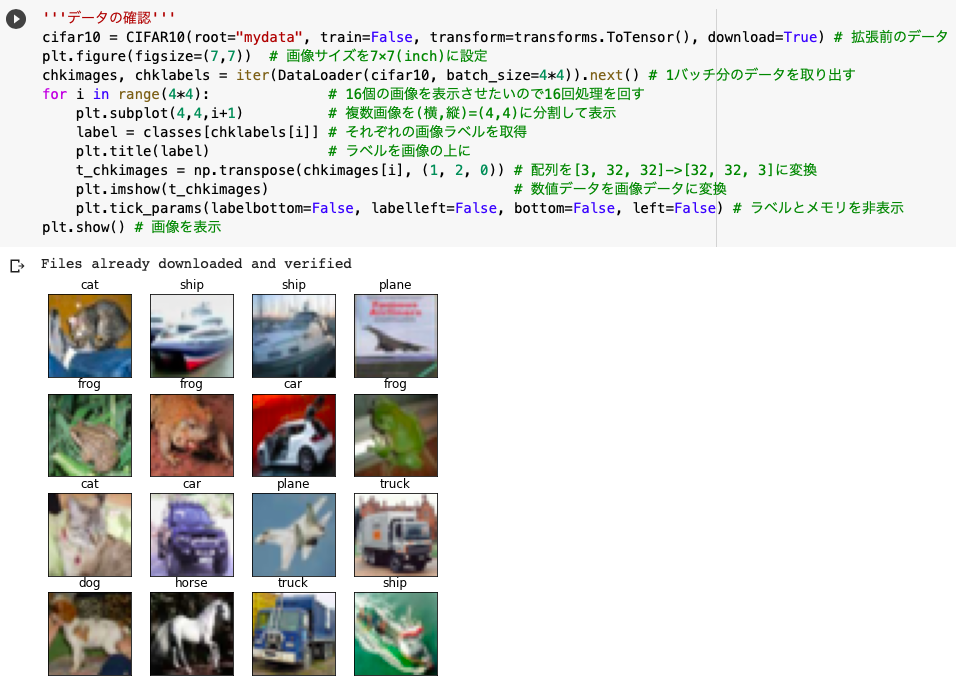
荒い画像を利用しているのですが、何となくうまくいっていることがわかります。
.iter().next()を使って1バッチ分のデータを取り出し、classesの配列からラベルを取得しました。
※chklabels[I]自体は数値なので、そのままではラベルとして機能しません。
そしてnp.transposeで配列のサイズを変更し、plt.tick_paramでラベルとメモリに関する表示をOFFにしました。
'''変換後の画像の表示'''
images, labels = iter(test_loader).next()
images, labels = images[:16], labels[:16]
imshow(torchvision.utils.make_grid(images, nrow=4, padding=1))
plt.axis('off')
plt.show()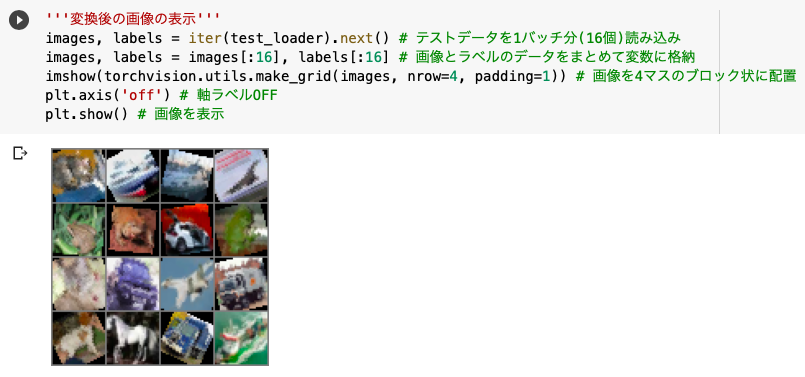
そしてこちらがランダムにデータを加工した画像であり、データの拡張とはこのような処理を指すことがわかりました。
torchvision.utils.make_gridでは画像を指定したサイズでブロック状に配置することができます。
'''モデルの定義'''
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 6, kernel_size=5)
self.bn1 = nn.BatchNorm2d(6)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5)
self.bn2 = nn.BatchNorm2d(16)
self.fc1 = nn.Linear(16 * 5 * 5, 256)
self.dropout = nn.Dropout(p=0.5)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(self.bn1(x))
x = F.relu(self.conv2(x))
x = self.pool(self.bn2(x))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
model = CNN().to(device)
model
'''最適化手法の定義'''
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
nn.Conv2d, nn.MaxPool2d, nn.Linearの使い方や処理の流れは、前回の記事に詳しくまとまっているのでそちらをご参照ください。
※Dropout(), Batch Normalization()のメリット・デメリットに関してまとめた記事はこちら。
def forward:中で1つ目の全結合層では「F.relu(self.fc1(x))」とReLUが適用されているのに対し、2つ目の全結合層ではReLUが適用されていませんが、これは1つ目のReLUが既に適用されているからです。
※ReLUは「y=x(x>=0)、y=0(x<0)」という関数。
'''訓練用の関数を定義'''
def train(train_loader):
model.train()
running_loss = 0
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
running_loss += loss.item()
loss.backward()
optimizer.step()
train_loss = running_loss / len(train_loader)
return train_loss
'''評価用の関数を定義'''
def valid(test_loader):
model.eval()
running_loss = 0
correct = 0
total = 0
with torch.no_grad():
for i, (images, labels) in enumerate(test_loader):
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_loss += loss.item()
predicted = outputs.max(1, keepdim=True)[1]
correct += predicted.eq(labels.view_as(predicted)).sum().item() # 先の例で説明済み
total += labels.size(0)
val_loss = running_loss / len(test_loader)
val_acc = correct / total
return val_loss, val_acc
'''誤差(loss)を記録する空の配列を用意'''
loss_list = []
val_loss_list = []
val_acc_list = []
'''学習'''
for epoch in range(num_epochs):
loss = train(train_loader)
val_loss, val_acc = valid(test_loader)
print('epoch %d, loss: %.4f val_loss: %.4f val_acc: %.4f' % (epoch, loss, val_loss, val_acc))
loss_list.append(loss)
val_loss_list.append(val_loss)
val_acc_list.append(val_acc)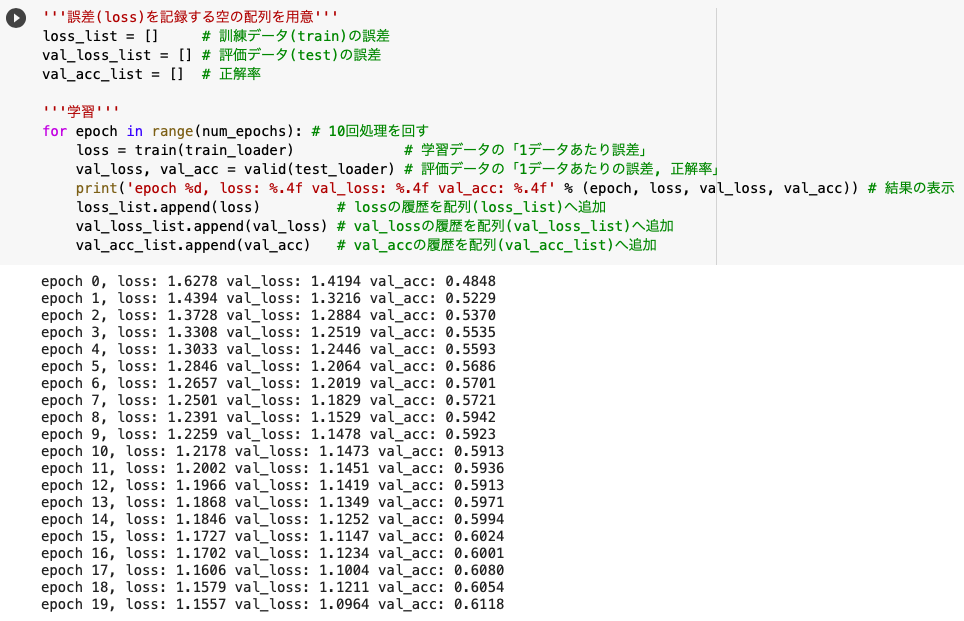
'''学習の結果と使用したモデルを保存'''
np.save('loss_list.npy', np.array(loss_list))
np.save('val_loss_list.npy', np.array(val_loss_list))
np.save('val_acc_list.npy', np.array(val_acc_list))
torch.save(model.state_dict(), 'cnn.pkl')
'''結果の表示'''
plt.plot(range(num_epochs), loss_list, 'r-', label='train_loss')
plt.plot(range(num_epochs), val_loss_list, 'b-', label='test_loss')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.figure()
plt.plot(range(num_epochs), val_acc_list, 'g-', label='val_acc')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('acc')
print('正解率:',val_acc_list[-1]*100, '%')
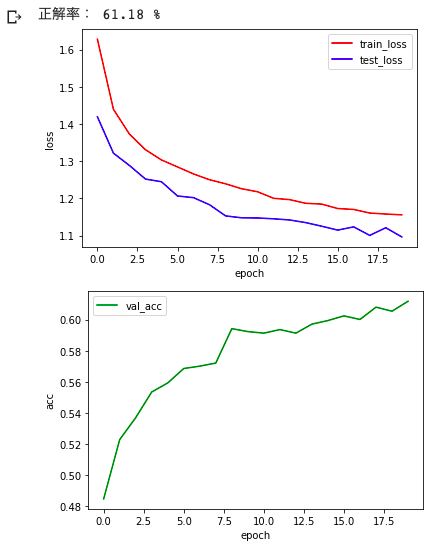
今回は「epoch数=20, batchsize=128」という条件で正解率が「61.1%」でした。
前回のMNISTが「epoch数=10, batchsize=100」という条件で正解率が「99.1%」だったので、epoch数が倍増しているにも関わらず精度があまり良くないことがわかります。
やはりモノクロの数字画像よりも、カラーの動物や車の画像の方が予測が難しいんですね。
さて、せっかくモデルを構築したので、実際にいくつかテストしてみて結果がどうなるか試してみましょう。
'''訓練済みモデルで精度を検証'''
images, labels = iter(DataLoader(cifar10, shuffle=True)).next()
img = np.transpose(images[0], (1, 2, 0))
plt.imshow(img)
plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False)
plt.show()
lab = model(images.to(device))
print("正解:", classes[labels[0]], "予測結果:", classes[lab.argmax(1).item()])
あまり精度が高いモデルではないので、そこそこの確率で間違えます。笑
ただ正解することもあるので何度か実行してみてください。

↑正解
しっかりモデルが機能していることが確認できました。
参考文献
PyTorch (6) Convolutional Neural Network
【詳細(?)】pytorch入門 〜CIFAR10をCNNする〜
Pytorch – torchvision で使える Transform まとめ
pyTorchのtransforms,Datasets,Dataloaderの説明と自作Datasetの作成と使用
PyTorch (5) Multilayer Perceptron
TORCHVISION.TRANSFORMS




