爆速データウェアハウスなApache Druidを試す

こんにちは、エクスチュアの權泳東(権泳東/コン・ヨンドン)です。
今回はApache Druidについてです。
Apache Druidとは
Apache Druidはカラム型(列指向)の分散型データストアで、オープソースで開発が進められてます。
データのインジェストはバッチとストリーミング両方に対応しており、垂直方向へのスケールに強く、また、新しくインジェストしたデータにはリアルタイムで検索インデックスが作成されるという特徴があります。
SQLインターフェースを備えたリアルタイムデータウェアハウスと言う感じで、とにかくパフォーマンス命で低レイテンシを重視してます。
クエリ実行におけるパフォーマンスはHiveの260倍、BigQueryの10倍出るらしい。。
TL;DR
Apache Druidは爆速データウェアハウスです。
そんなApache Druidを早速GCP上で動かして見ました。
さっそくQuickStart
Apache DruidのQuickstartを実際に試しました。
Quickstart · Apache Druid
まずはVMを用意します。
マシンタイプは n1-standard-1 (1 vCPU, 3.75 GB memory) で、OSはUbuntu 18.04にしました。
これはApache Druidの必要最低スペック(nano-quickstart用)です。
DruidはJava 8が必要なので今回はOpen JDK 8をインストールします。
Open JDK 8をインストール
Ubuntuでインストールするには、下記のコマンドを実行します。
sudo apt install openjdk-8-jdk -y
インストール後、/etc/environment に環境変数JAVA_HOMEをセットします。
JAVA_HOME="/usr/lib/jvm/java-8-openjdk-amd64"
それからsourceコマンドでJAVA_HOMEを反映。
source /etc/environment
Apache Druidをインストールして起動
Apache Druidを下記のミラーサイトからダウンロードします。
Apache Download Mirrors
ダウンロード後、tar.gzを展開します。
私は/usr/localにコピーしました。
tar -zxf apache-druid-0.17.0-bin.tar.gz sudo cp -r apache-druid-0.17.0 /usr/local/ cd /usr/local/apache-druid-0.17.0/
そしてDruidを起動します。
n1-standard-1マシンを選んだので、nano-quickstartを起動します。
export DRUID_SKIP_JAVA_CHECK=1 nohup ./bin/start-nano-quickstart &
これでDruidがtcp 8888番ポートで起動するので、ブラウザでアクセスします。
なお、VPC FirewallでVMインスタンスのtcp 8888番ポートとの通信を許可する必要があります。
IP制限も適宜実施してください。
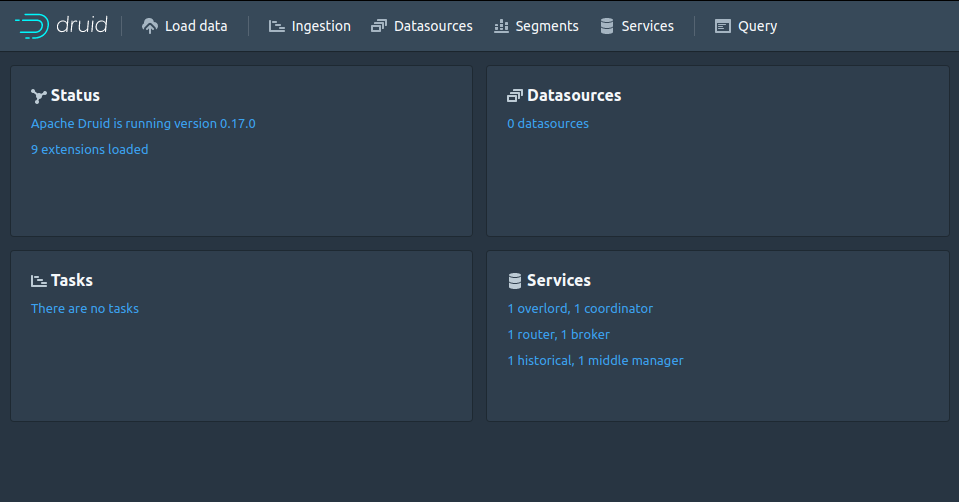
サンプルデータをロード
次はサンプルデータをロードします。
画面上部の[Load data]をクリックするとこういう画面が出ます。
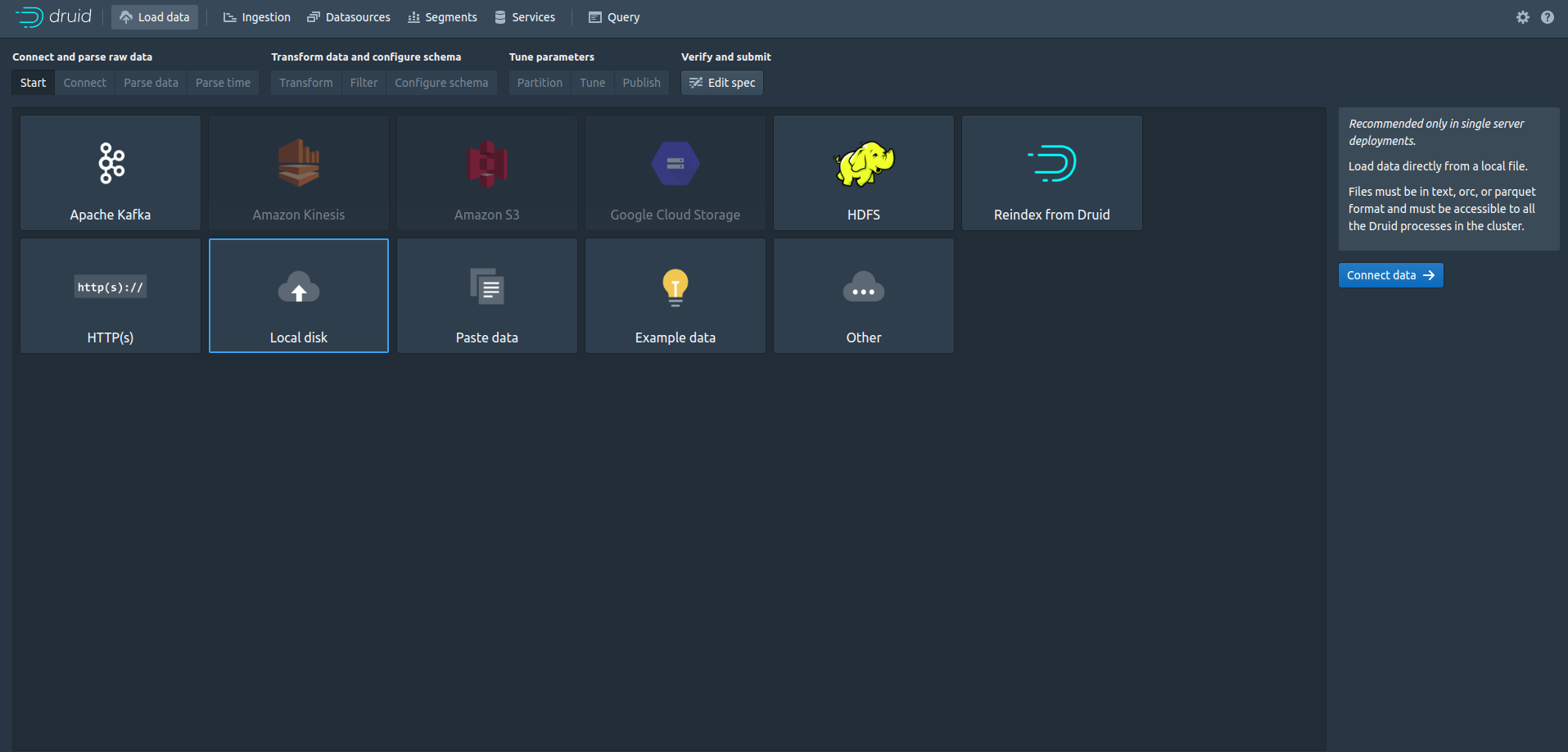
この中の[Local disk]を選んで[Connect data] に進みます。
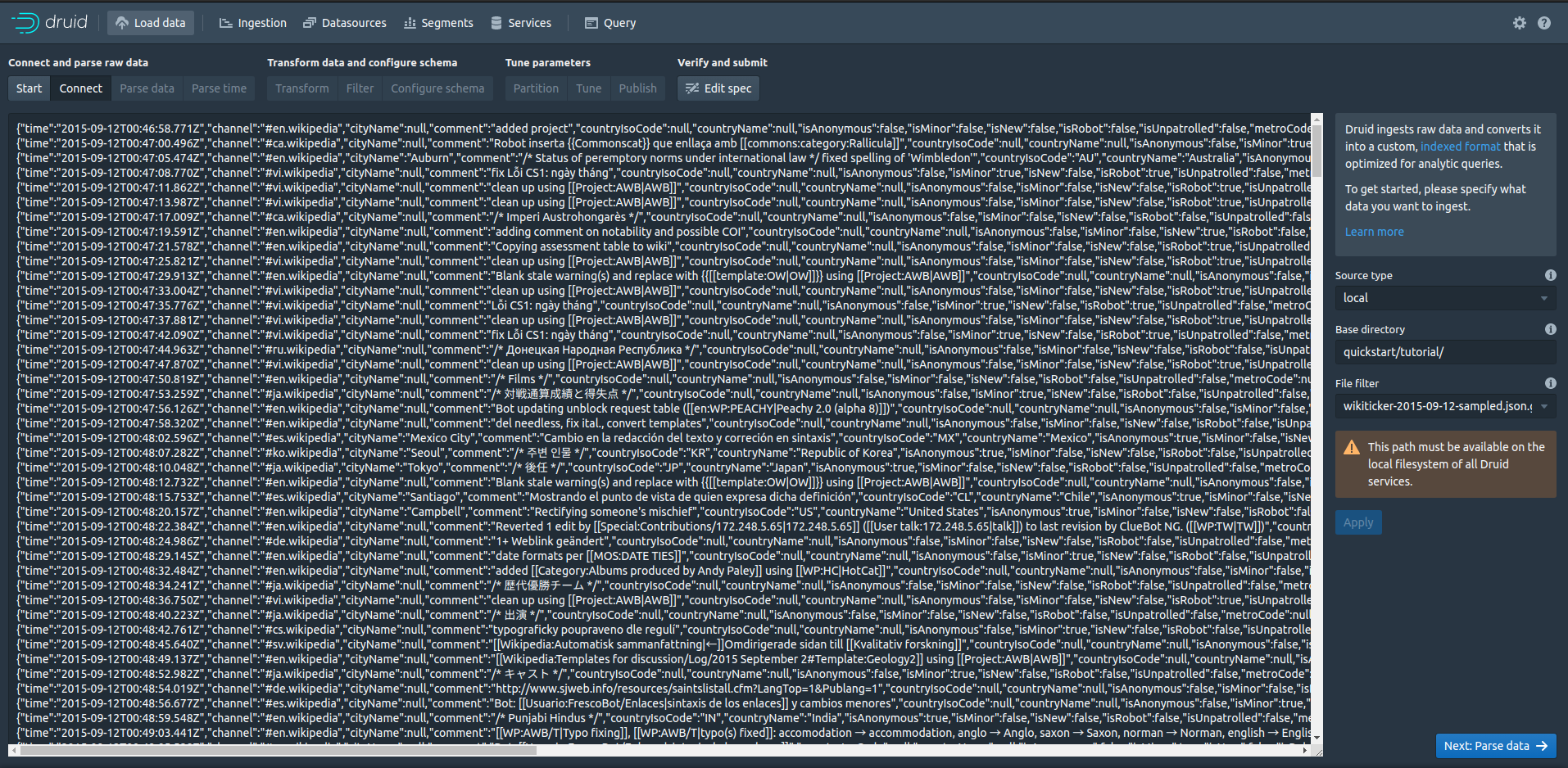
次の画面で下記を入力します:
- Base directory: quickstart/tutorial/
- File filter: wikiticker-2015-09-12-sampled.json.gz
そして[Appl]を押すと下記のようにデータをプレビュー出来ます。
で、ここから先はデフォルトのまま3ステップ飛ばすので、
- Next: Parse time
- Next: Transform
- Next: Filter
の順番にボタンを押して進みます。
すると[Configure schema]の画面になるので、ここでは[Rollup]のチェックを外します。
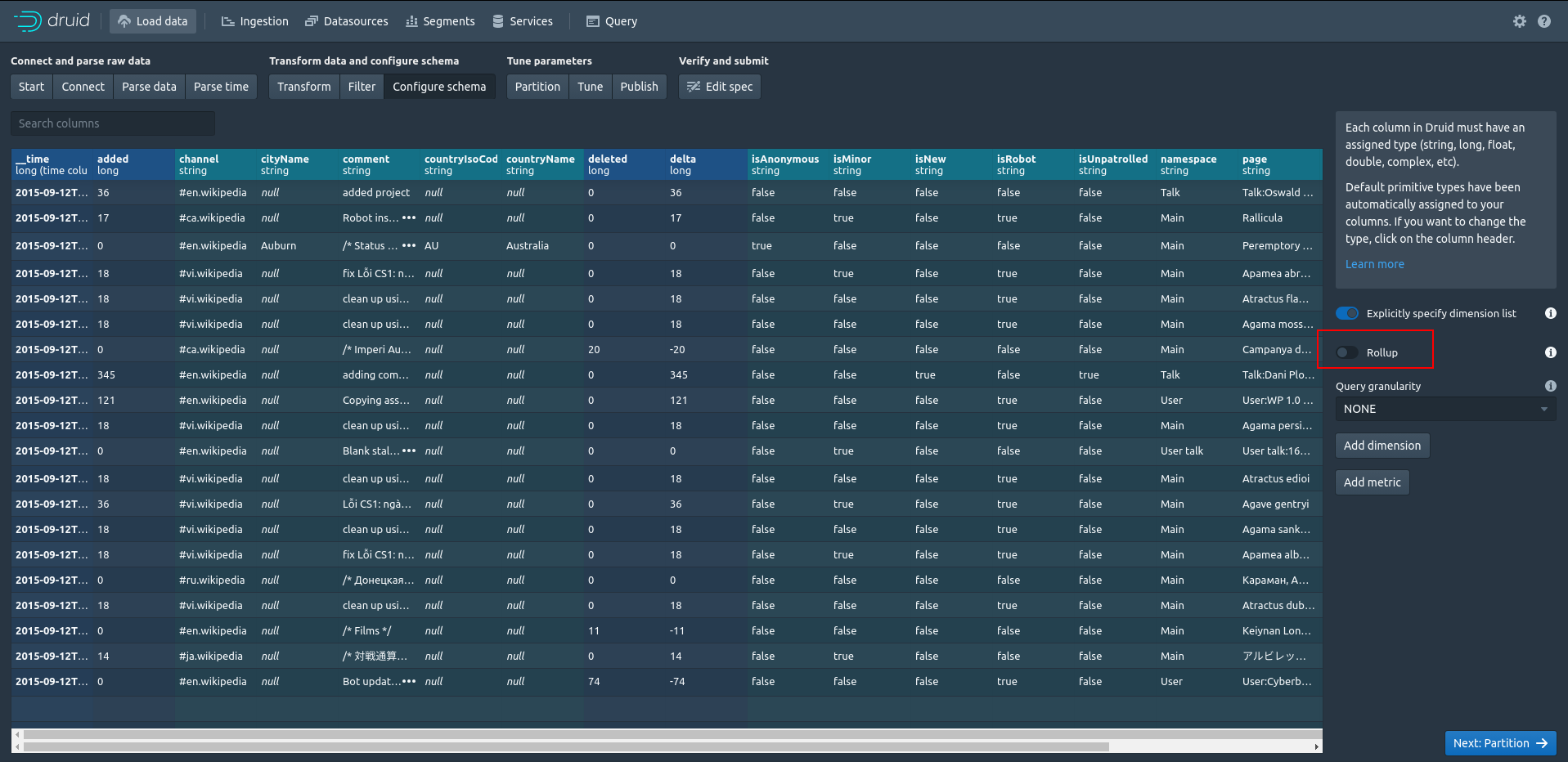
続いて[Next: Partition]に進みます。
ここでは、[Segment granularity] を [DAY] にします。
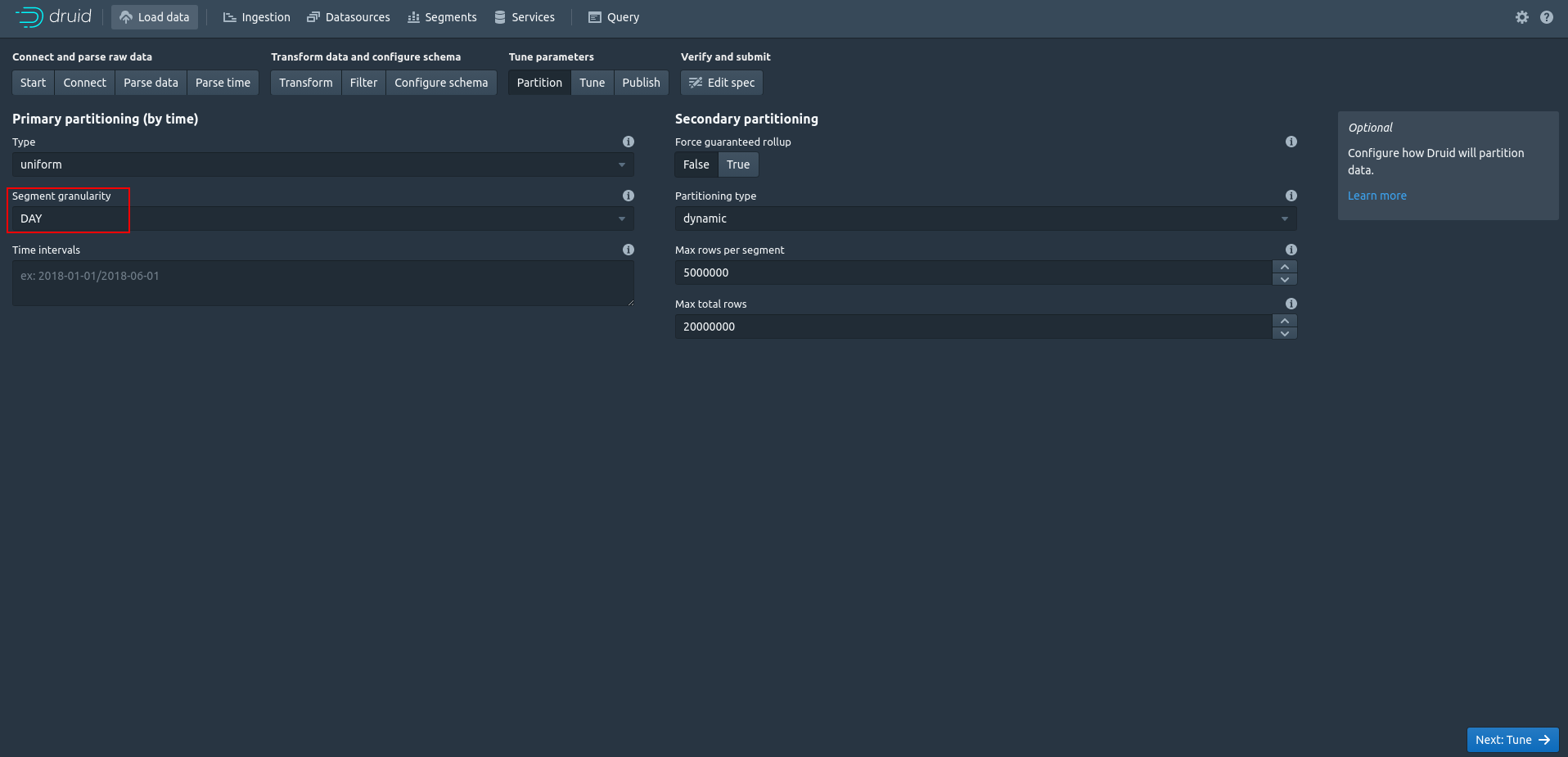
続いて[Next: Tune]に進みます。
[Datasource name]にわかりやすい名前をつけます。
ここでは[wikipedia]という名前にしました。
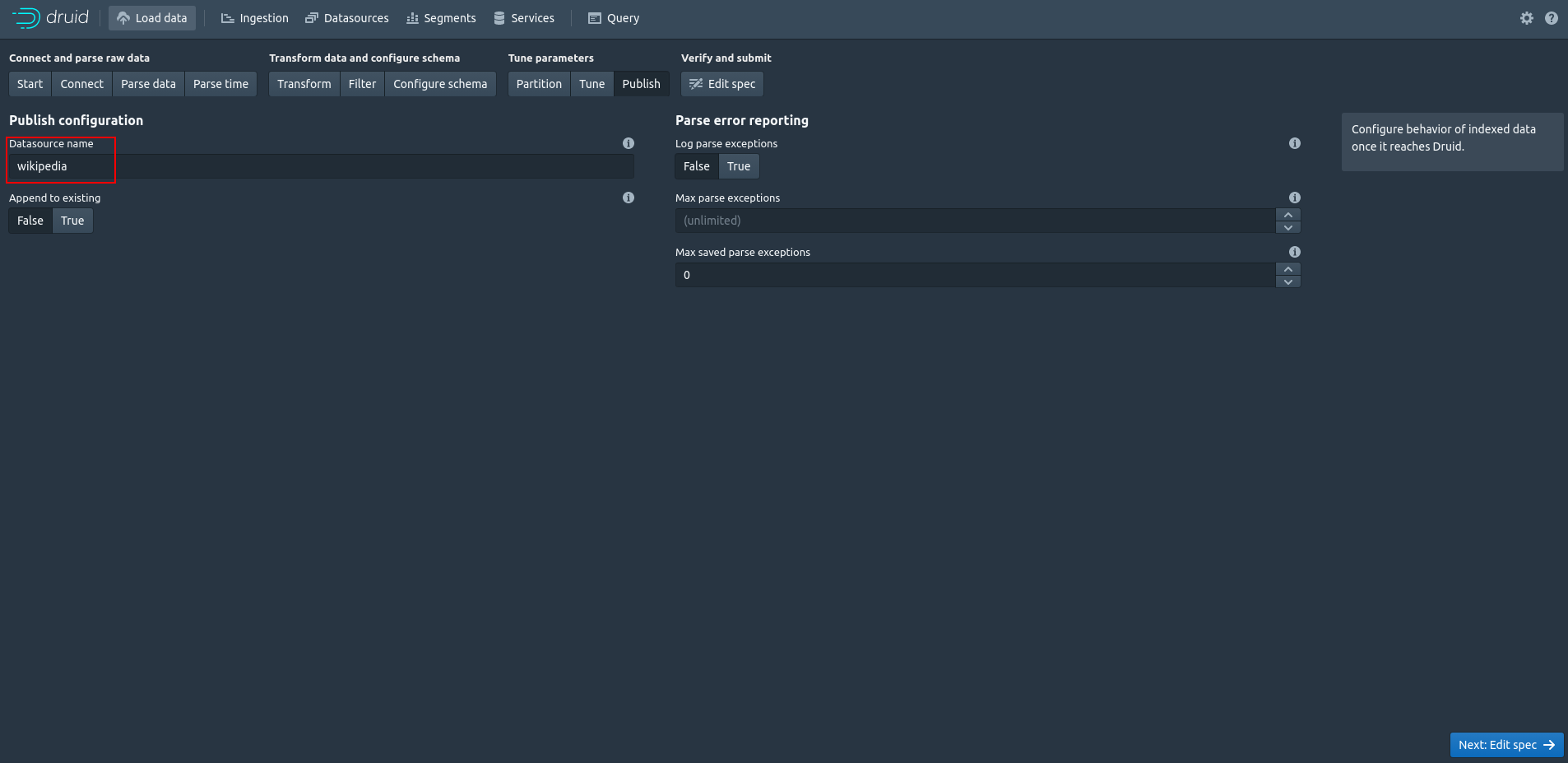
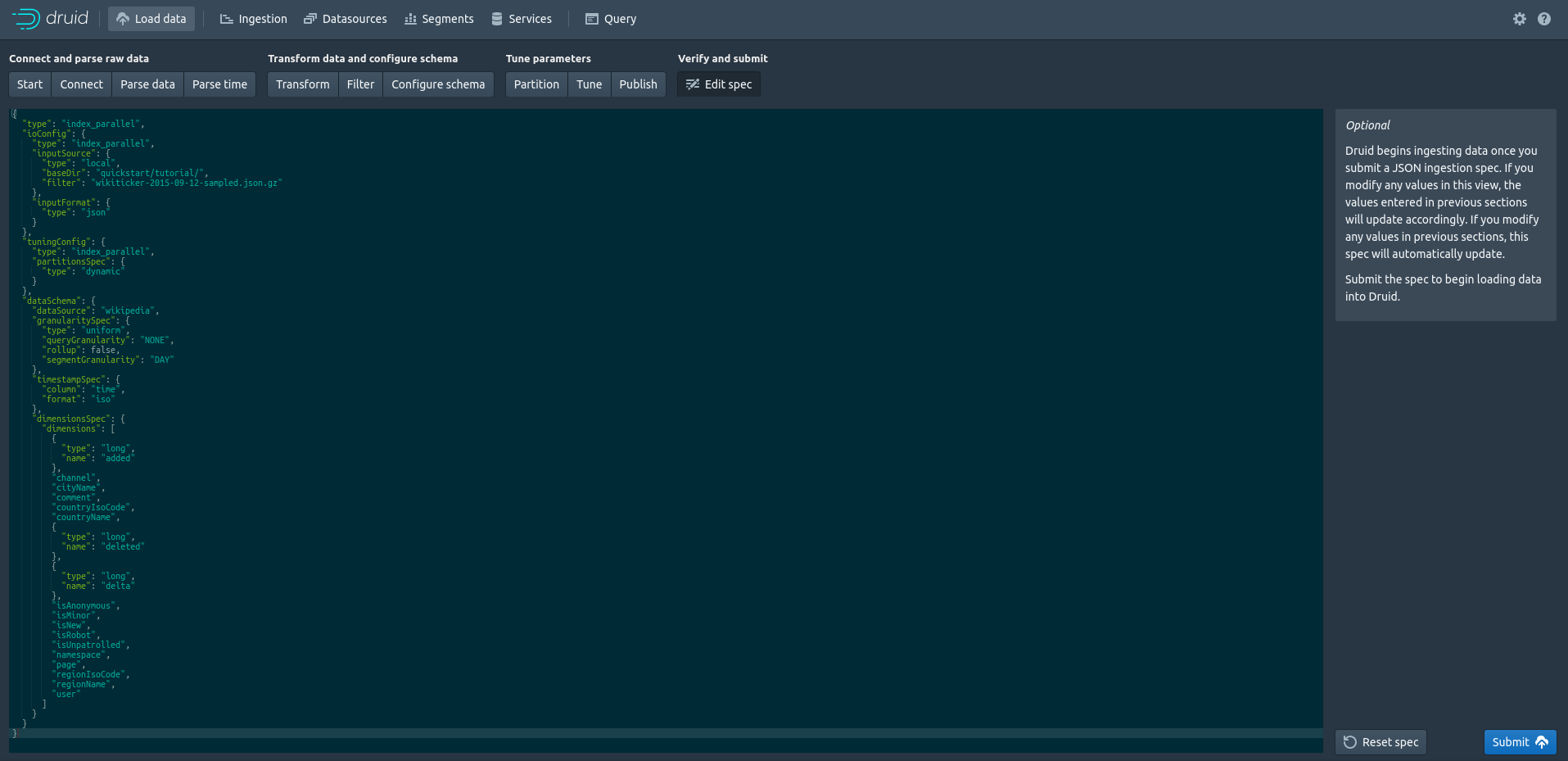
それから[Edit spec]に進み、[Submit]を押すとデータロードが始まります。
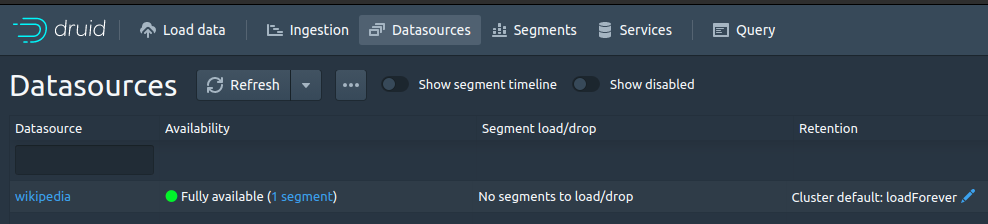
アップロードが終わると[Datasources]に表示されます。
SQLを実行
それではSQLでクエリを実行します。
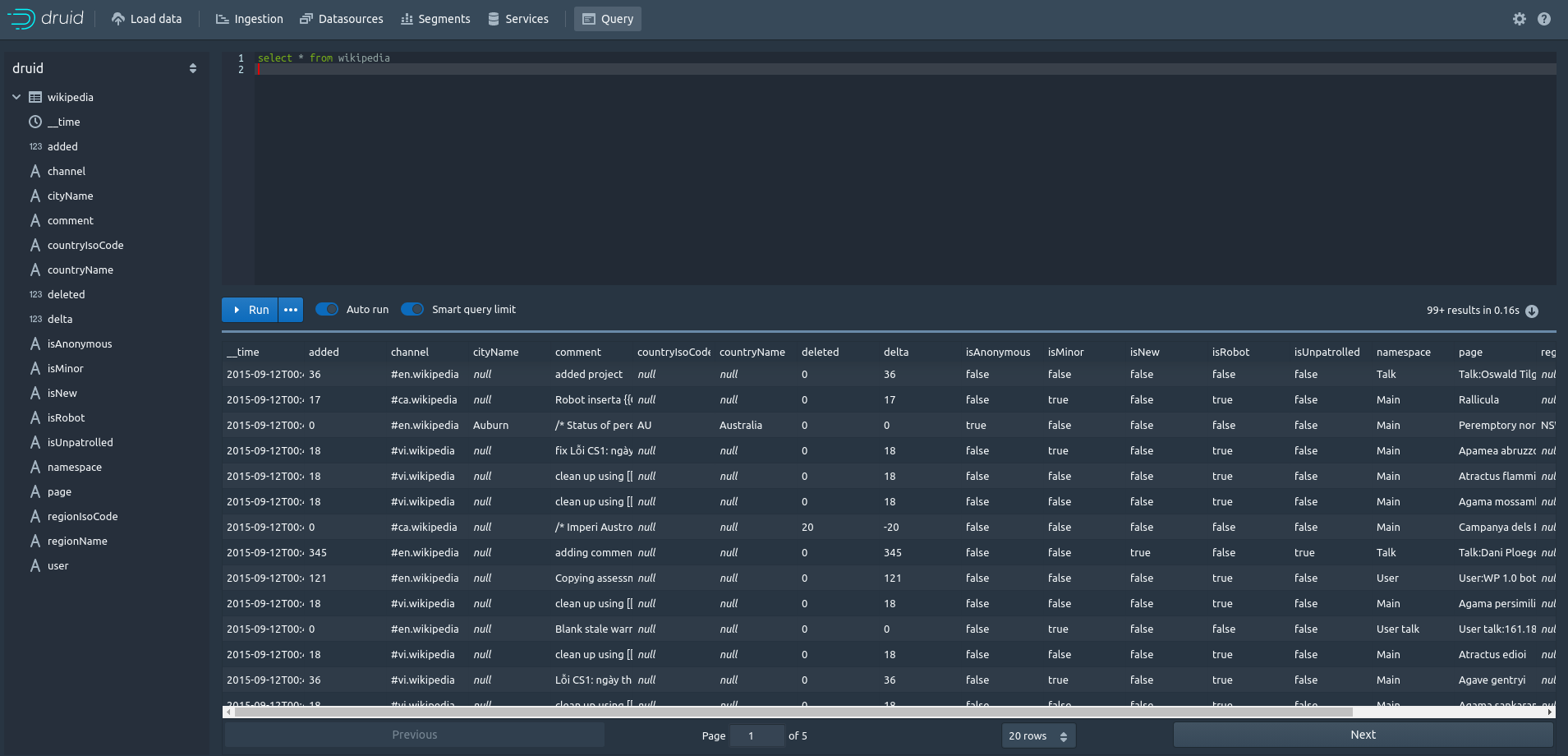
[Query]を開いて、下記のSQLを記入して[Run]を押すと実行します。
select * from wikipedia
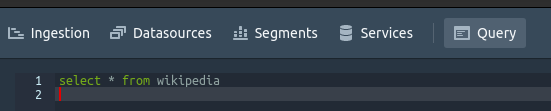
結果がすぐに返って来ます。
まとめ
今回はApache Druidのnano-quickstartを、n1-standard-1タイプのVMを1台使って動かして見ました。
さらにパフォーマンスを求める場合は、ハイメモリマシンを複数台使ったクラスタを構成する事で、より高速なクエリを実行できる事が期待されます。
今後弊社ではApache Druidを使った分析基盤構築を提供して行く予定です。
お問い合わせはこちらからどうぞ。