
Seleniumって何?
Selenium(セレニウム)とは、Webアプリケーションの画面操作を自動化するツールで、
主に画面テストの自動化やWeb上での単純作業に使用されます。
様々なブラウザ・OS・プログラミング言語に対応しているのですが、今回使用するのは以下の通りです。
ブラウザ:Chrome
OS:Mac OS(10.14.3)
プログラミング言語:Python(3.7.1)
実行日:2019/3/22
環境構築
まずMacのターミナルを開きます。
次にターミナル上でpipをインストールします。
pipとは簡単に言うと、pythonを使いやすくする様々なファイルが格納されたものです。
以下では、pipをインストールし、pipからseleniumをインストールしていきます。
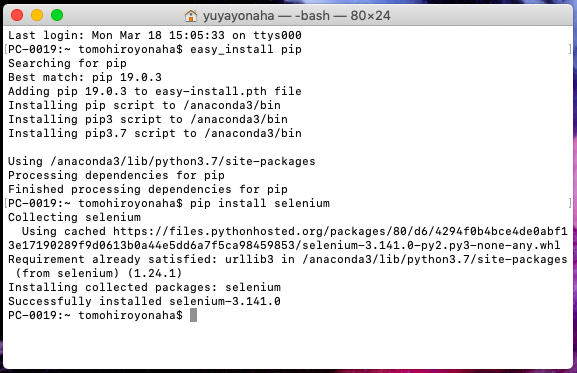
ターミナル上で「easy_install pip」と入力し「Finished processing dependencies for pip」と出力されれば成功です。
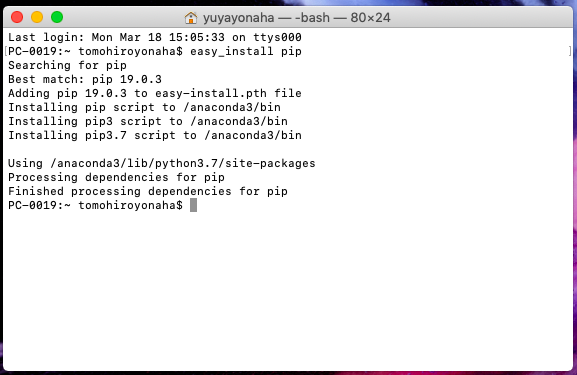
これでpipがインストールされたので「pip install selenium」でseleniumをインストールします。
※すでにpipをインストールされている方は、pipをアップグレードする必要がある場合がございます。
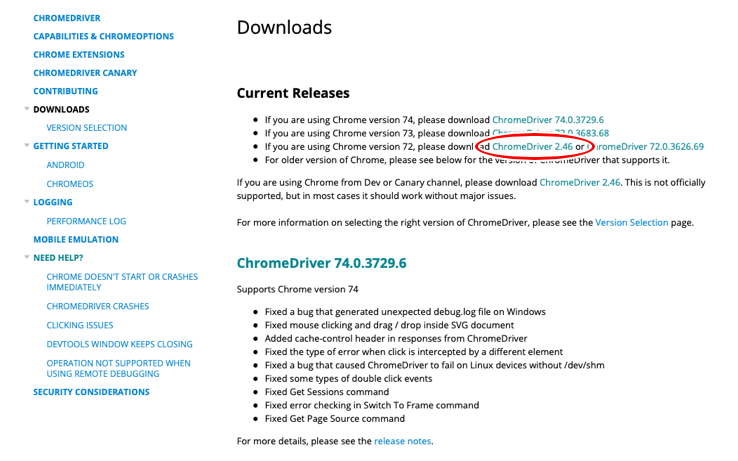
seleniumのインストールができましたら、こちらから各々のChromのバージョンに合わせたChromedriverをインストールします。
今回は以下の赤枠部分を選択し、そこから「chroedriver_mac64.zip」というものをダウンロードします。
※「開発者が未確認のため開くことができません」というエラー文が出たら、macの「システム環境開発」→「セキュリティーとプライバシー」→「このまま開く」をクリック。
ここで、まだGoogleChromeをインストールしていない方はこちらからインストールしてください。
この際にChromeが「アプリケーション」フォルダに存在しない場合は、ドラッグ&ドロップで追加しましょう。
※追加していない場合はseleniumを用いた自動化コードを実行した際に「cannot find Chrome binary」と言うエラー文が表示されます。
※ChromeがChromedriverのバージョンに対応していなければエラー文が表示されるので注意してください。
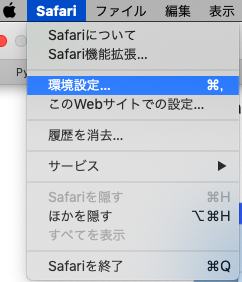
次にsafariで開発メニューを表示させます。
開発メニューを表示させる理由は、ブラウザを操作するためのHTMLを取得することができるようになるからです。
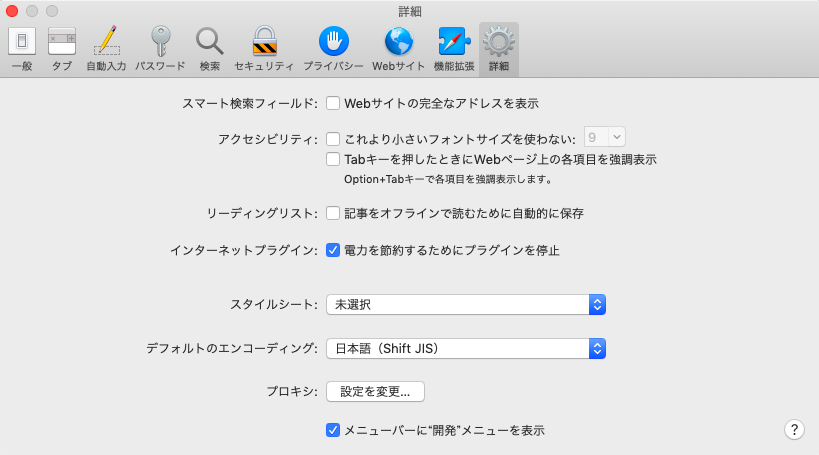
safariのウィンドウ上部から環境設定を開き、詳細→メニューバーに開発メニューを表示(一番下)にチェックを入れれば完了です。
最後に、Jupyter Notebook をインストールします。
再びターミナルに戻り、以下のコードを実行します。
〜 pipをアップグレード 〜
「pip install –upgrade setuptools」
「pip install –upgrade pip」
※ pipはpythonの機能をインストールするために必要なツール。
〜 必要な機能をインストール 〜
「pip install numpy」
「pip install scipy」
「pip install matplotlib」
「pip install Pillow」
「pip install ipython」
〜Jupiter Notebookを開く〜
「pip install jupyter」
「jupyter notebook」
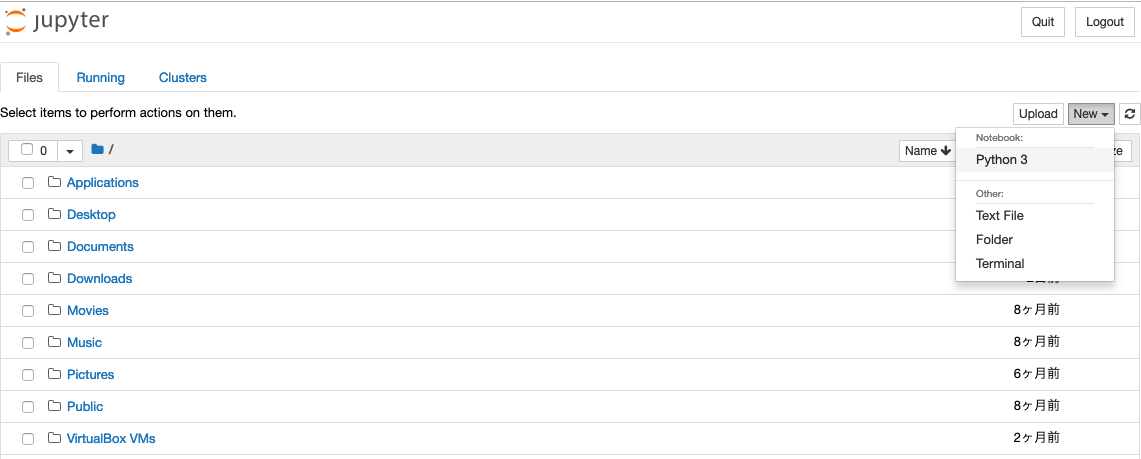
右上の「New」から「Python3」を選択して、新しいpythonファイルを作成できたら完了です。
お疲れ様でした。これで環境構築作業は終了です。
では、早速実行コードを記述していきましょう。
実行
今回は、以下の操作を自動化するコードを記述します。
【Googleの検索エンジンに入る
→”エクスチュア”で検索
→ウィンドウを最下部までスクロール
→3ページ目のボタンをクリック
→先頭のサイトにアクセス
→画面サイズに合わせたスクショを撮影
→その画像を”エクスチュア_スクショ.png”という名前で保存】
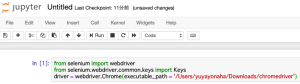
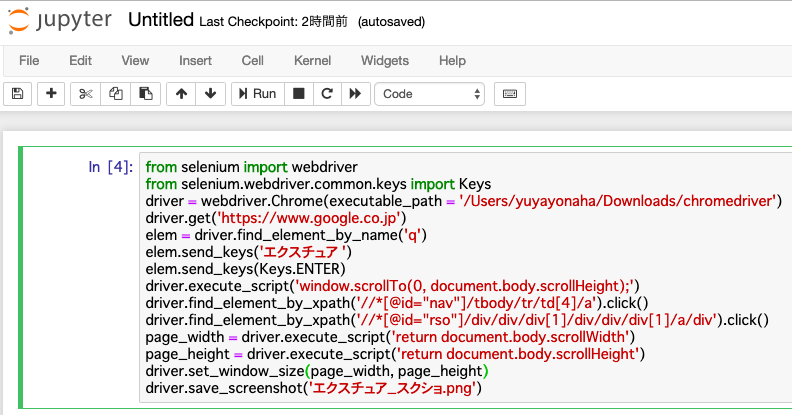
Jupyter Notebookで以下のコードを入力します。
「from selenium import webdriver」
「from selenium.webdriver.common.keys import Keys」
「driver = webdriver.Chrome(executable_path = ‘/Users/yuyayonaha/Downloads/chromedriver’)」
※この時”yuyayonaha”の部分は私のPCの名前ですので、各々は自分のchromedriverのパスを調べて入力しましょう。
※chromedriverをターミナルにドラッグ&ドロップすれば、そのファイルのパスを調べることができます。
「from 〇〇 import △△」とは、〇〇モジュールから△△の機能をインポートするという式で、
「driver = webdriver.Chrome(executable_path = ‘〇〇’)」とは、
左辺でdriverという変数を新たに定義して、右辺でChromedriverのパスを入力しChromedriverを使えるようにした式です。
※パス=そのファイルが存在する場所。
「driver.get(‘https://www.google.co.jp’)」と入力し、実行(▶︎Run)ボタンを押してください。
自動でGoogleのホームページに入れましたね!おめでとうございます
「driver.get(‘〇〇’)」とは、上で定義した変数driverで〇〇というURLに入るという式です。
グーグルHPに入った後は、画面上で検索ボックスを選択します。
全てのwebサイトには属性というものが存在し、HTMLタグを取得することで特定の要素を指定することができます。
「option + command⌘ + u」を同時に押すか、特定の要素を右クリックすることで属性と要素を取得しましょう。
※環境構築の部分で開発メニューを表示させたのは属性と要素を取得するためです。
safariで新しいブラウザを立ち上げグーグルを開きます。
検索ボックスにマウスを重ね、右クリックで「要素の詳細を表示」を選択します。
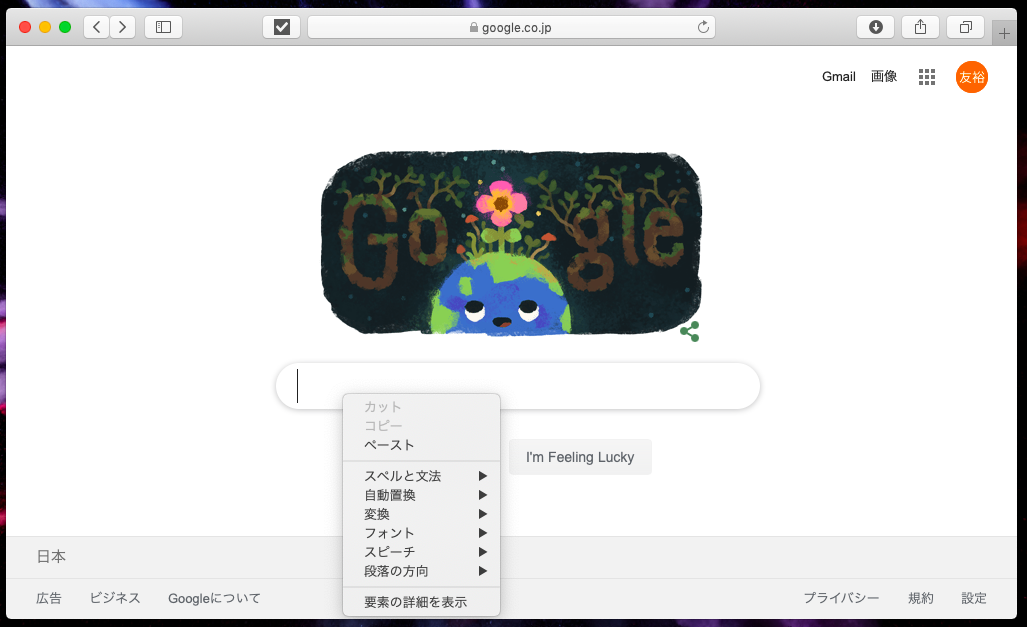
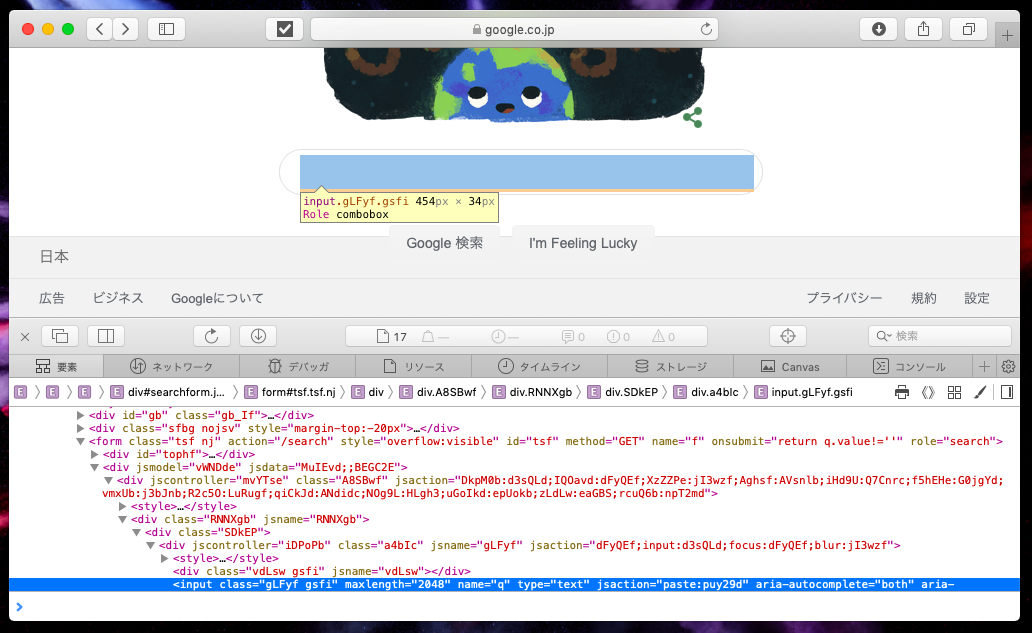
この結果からグーグルのHPで検索ボックスは、name属性が”q”であることがわかったので以下のコードを入力します。
「elem = driver.find_element_by_name(‘q’)」elemという新たに設定した変数に右辺を代入。(elemはGoogleで検索ボックスを選択するという役割)
「elem.send_keys(‘エクスチュア’)」検索ボックスに”エクスチュア”と入力する式。
「elem.send_keys(Keys.ENTER)」検索ボックスで”Enter”というキーボードを押すという式。
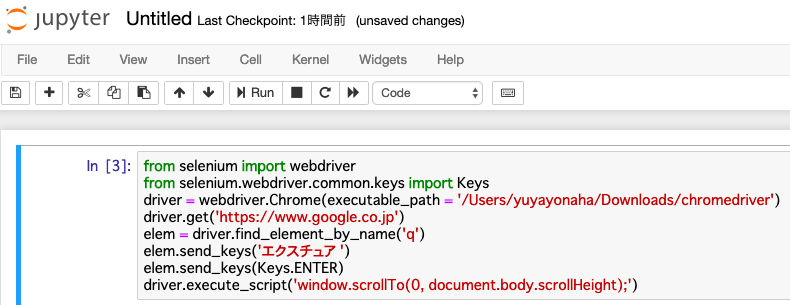
この3つが入力し終えたら試しに、実行(▶︎Run)ボタンを押してみてください。
どうでしょう。こんなに簡単に自動でブラウザ操作できるなんて感動しませんか。
次にウィンドウを下までスクロールさせます。
「driver.execute_script(‘window.scrollTo(0, document.body.scrollHeight);’)」を入力してください。
「driver.」以降の式は定石ですので、何も考えずにコピペしてください。
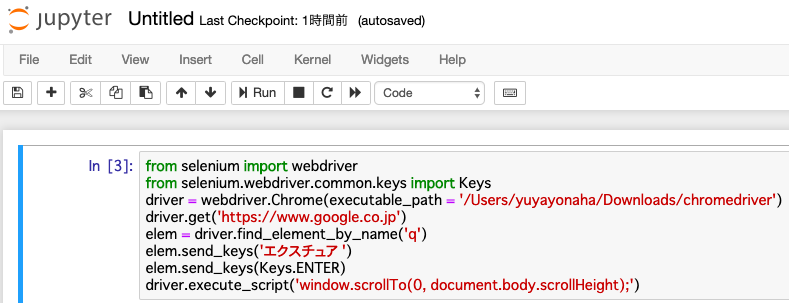
ここで3ページに遷移するボタンの属性を知りたいので、
別ブラウザでグーグルを開き3ページに遷移するボタンを右クリックで「要素の詳細を表示」を選択します。
しかし、class名などが他のボタンと重複しているので、今回はxpathを使用します。
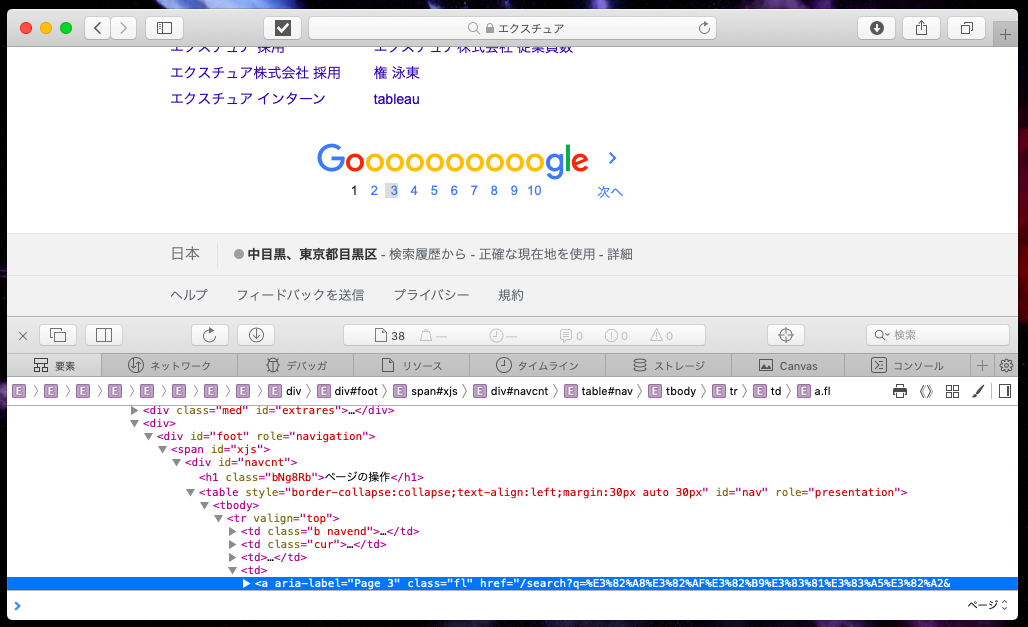
※ xpathとはサイトの特定の箇所を指定することができる言語です。
以下のようにHTMLタグを右クリックして、xpathをコピーします。
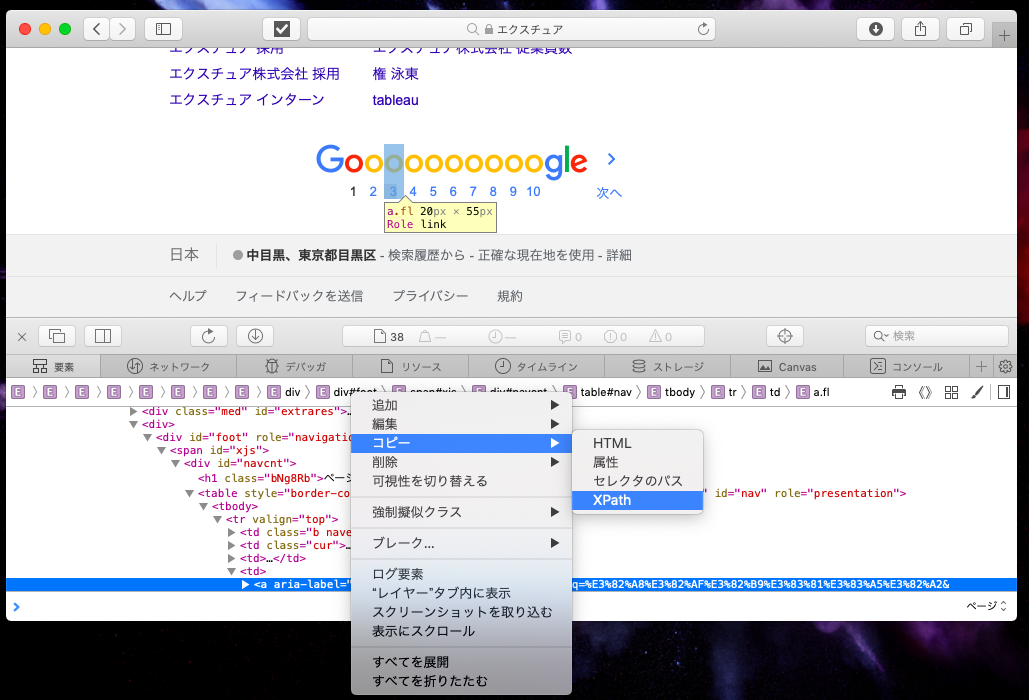
これより3ページに遷移するボタンのxpathが「//*[@id=”nav”]/tbody/tr/td[4]/a」であることがわかったので、
notebookで「driver.find_element_by_xpath(‘//*[@id=”nav”]/tbody/tr/td[4]/a’).click()」と入力。
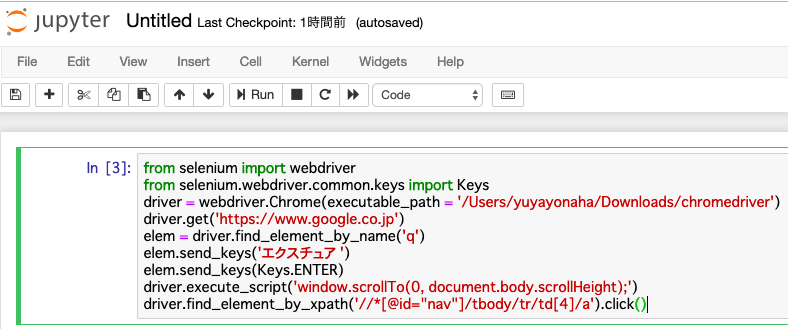
「driver.」以降がxpathを指定する式で「.click()」がクリックをする式です。
同様に先頭のサイトのxpathを取得すると「//*[@id=”rso”]/div/div/div[1]/div/div/div[1]/a/div」であるので、
notebookで「driver.find_element_by_xpath(‘//*[@id=”rso”]/div/div/div[1]/div/div/div[1]/a/div’).click()」を入力。
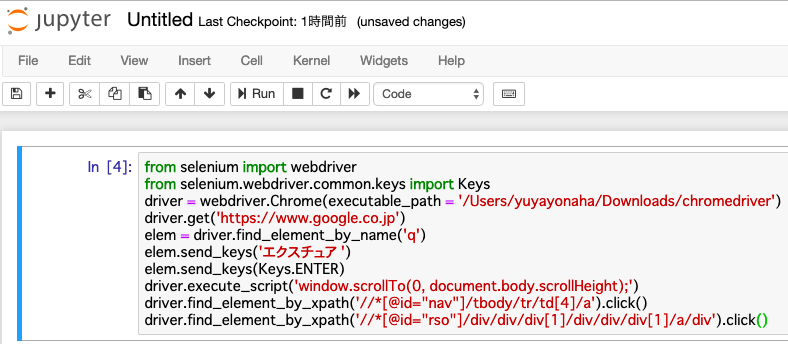
最後に、そのサイトのスクリーンショットを撮るために以下のコードを入力します。
「page_width = driver.execute_script(‘return document.body.scrollWidth’)」
「page_height = driver.execute_script(‘return document.body.scrollHeight’)」
「driver.set_window_size(page_width, page_height)」
「driver.save_screenshot(‘エクスチュア_スクショ.png’)」”エクスチュア_スクショ”という名前でPCに保存する式。
これらのコードも定石なので、何も考えずに実行しましょう。
今回は以下の画面のスクショを撮ることができました。
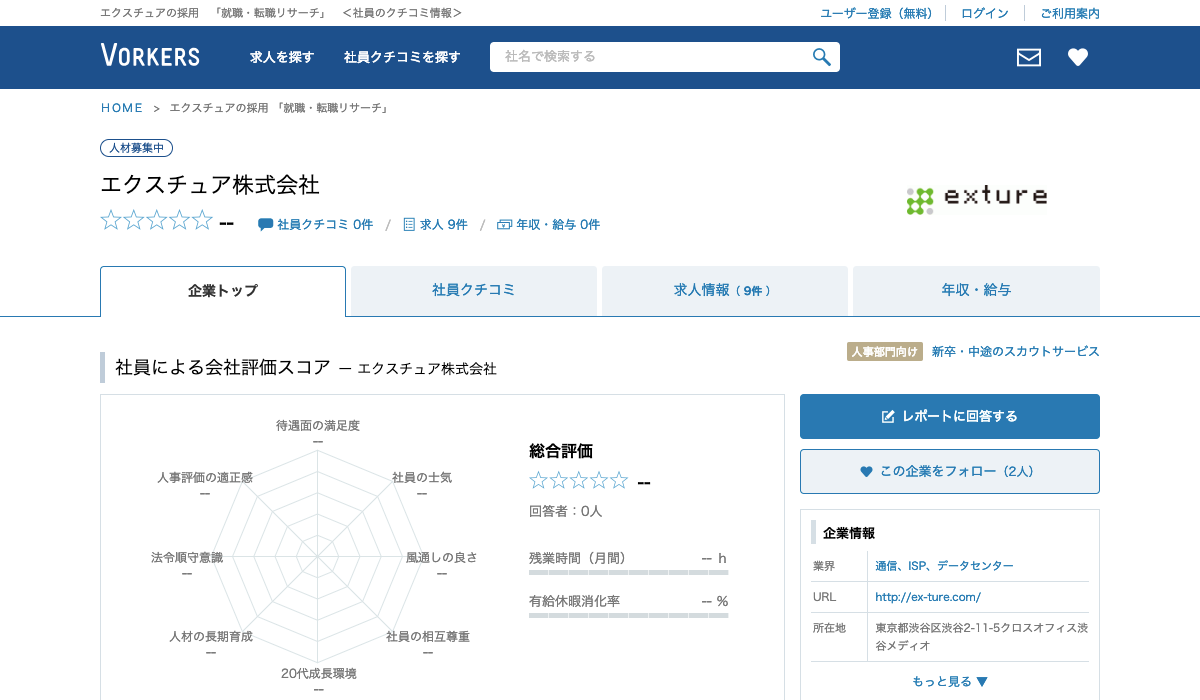
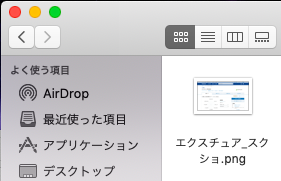
保存されていました!成功です
大変長い文章でしたが、最後まで目を通していただきありがとうございました🙇♂️
できる限り丁寧にまとめたつもりですが、何か不適切な箇所などありましたらコメント欄でご指摘ください🙏
参照元
https://qiita.com/yuji38kwmt/items/555aeb342f35ca7ce92e
https://4to.pics/article/post/54
https://joppot.info/2014/01/29/522
https://qiita.com/sy_125/items/7e68127c5ea0df04b82f
https://www.sejuku.net/blog/50417
https://begi.net/read/base/03.html
https://pc-karuma.net/safari-menu-development/
https://qiita.com/VA_nakatsu/items/0095755dc48ad7e86e2f
https://qiita.com/mzmiyabi/items/b1677e66474933d9a6fc
https://qiita.com/shinno21/items/93c4e379032edb1d6771







この記事へのコメントはありません。