Fivetranからdbtプロジェクトを実行する

こんにちは、インターン生の大石です。
前回に引き続き、Fivetranの機能をご紹介いたします。
前回記事はこちら:https://ex-ture.com/blog/2025/11/25/fivetran-bigquery-setup/
前回は、データ活用基盤においてFivetranが担う機能と、スプレッドシートからBigQueryにデータをロードする方法をご紹介しました。
しかし、データをロードしただけでは、データの品質や形式が統一されておらず、“データ活用基盤” としてはまだ不十分です。
実際に価値ある分析を行うためには、データソースの統合や同期に加えて、分析で使える形へデータを整える工程(データ変換)が不可欠です。
そこで今回は、Fivetran を用いて、ロードしたデータをどのように変換するのかを紹介していきます。
目次
概要
FivetranはELTツールであり、データ変換機能(Transformations)を備えています。
ロードしてから変換するので、BigQueryやSnowflakeなどロード先のDWHで実行されます。
公式ドキュメント:https://fivetran.com/docs/transformations#exploreyouroptions
データ変換をFivetranから実行するメリットとして、以下が挙げられます。
・実行スケジュールをFivetran側で一元管理できる
Fivetranがデータソースを最新化、その完了をトリガーにデータ変換を実行する、という連携が自動で行われます。そのため、古いデータを参照して変換してしまうという事故を防ぎ、個別にスケジュールを設定する必要がありません。
・コスト最適化につながる
Fivetranはデータが更新された場合のみデータ変換を行うため、無駄な実行を防止することができます。
事前準備
Transformationsを実装する方法はいくつかありますが、今回はdbt coreのプロジェクトをGithub経由で読み込んで実行します。
まず、dbt coreをインストールし、プロジェクトを作成しておきます。
以下は、今回使用するファイルの内容です。
# models/example/dbt_core_test_model.sql
{{ config(materialized='table') }}
select
customer_name,
sum(total) as total_rev
from
{{ source('google_sheets', 'test') }}
group by
customer_name# models/example/schema.yml
version: 2
models:
- name: dbt_core_test_model
description: "dbt test model"
columns:
- name: customer_name
description: "customer name"
tests:
- unique
- not_null# models/example/src_google_sheets.yml
version: 2
sources:
- name: google_sheets
schema: google_sheets
tables:
- name: test
test:
- not_nullGithubにリポジトリを用意して、dbtプロジェクトを保存しておきます。
注意点
Fivetranは、一時的にprofiles.ymlを作成してプロジェクトを実行します。
実際のprofiles.ymlには機密情報(ユーザー名・パスワードなど)が記載されているため、.gitignoreに追加しておき、リポジトリには含めないようにしてください。
Fivetran側の設定
Transformationsの設定は、プロジェクトを作成してから、それをもとにジョブを作成するというステップを踏みます。
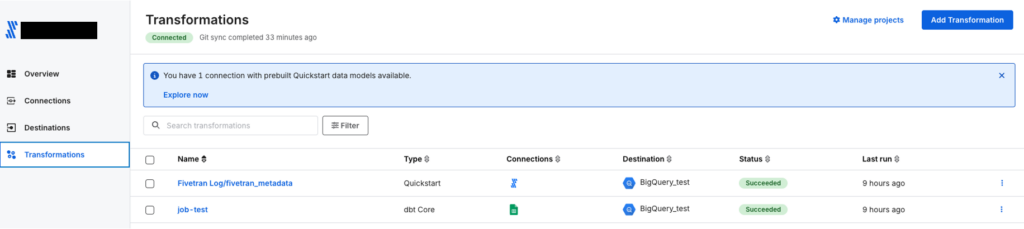
プロジェクト設定
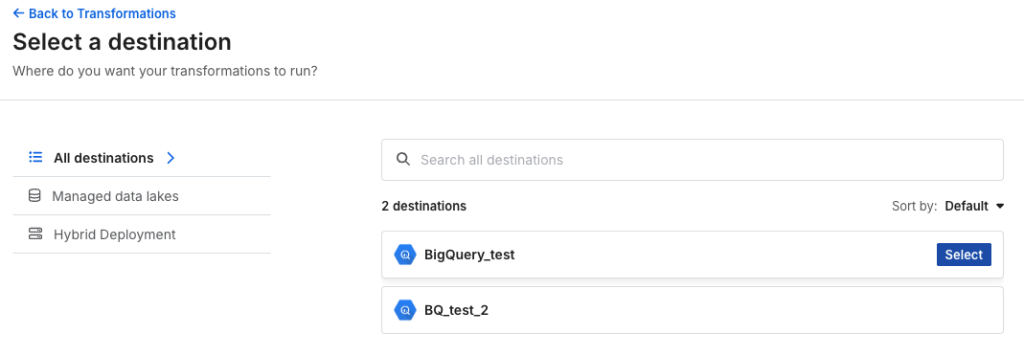
Add Transformationから、データ変換が実行されるdestinationを選択します。
GCPのプロジェクトやデータセット名は、事前に設定したdestinationの情報が参照されます。
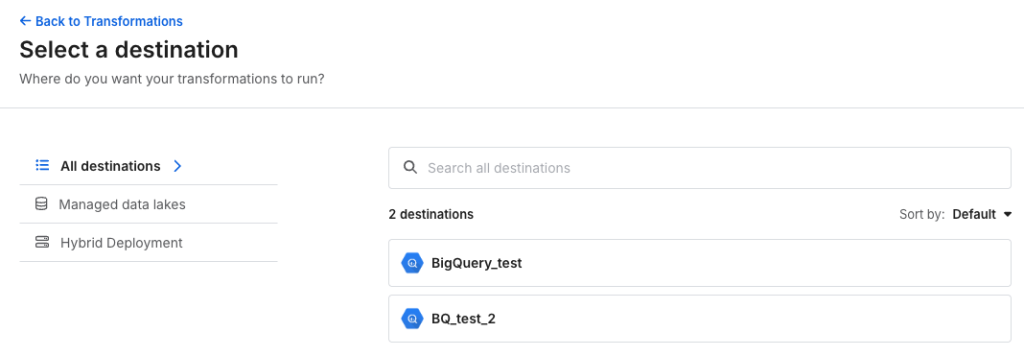
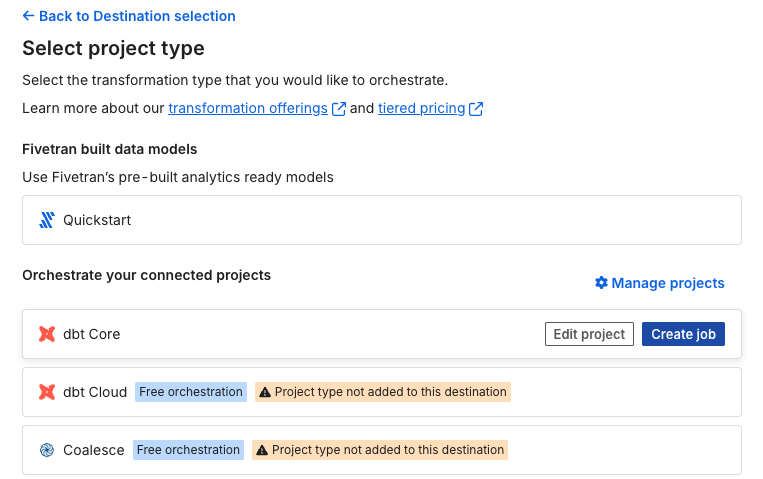
利用する変換ツールを選択して、プロジェクトを作成します。
destination*変換ツールの組み合わせごとに、プロジェクトを設定する方式です。
(同じdestinationでも、dbt coreとdbt cloudでは別のプロジェクトになります)
今回はdbt coreを選択します。
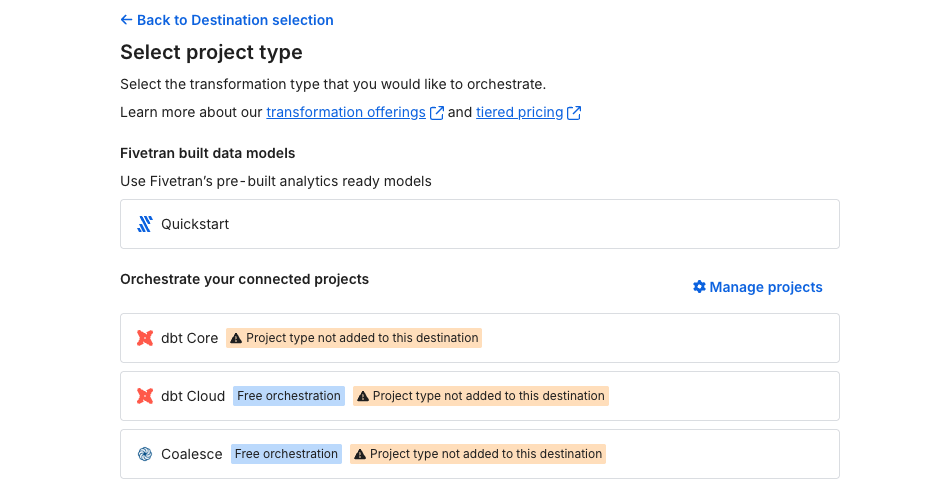
設定画面では、コネクタと同様に右側にドキュメントが表示されます。
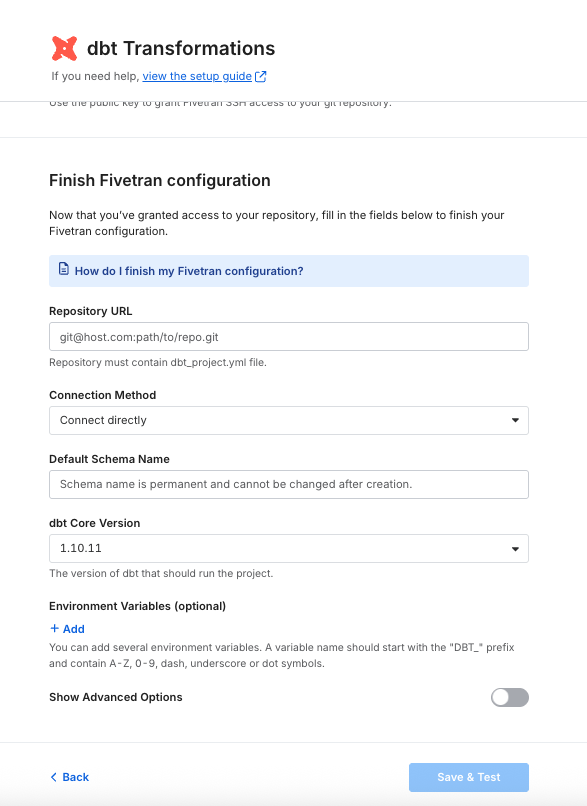
Fivetranがリポジトリを読み取るために、公開鍵をコピーしてGithub側のリポジトリに登録して秘密鍵を発行します。
リポジトリのSetting→Deploy Keysから発行できます。
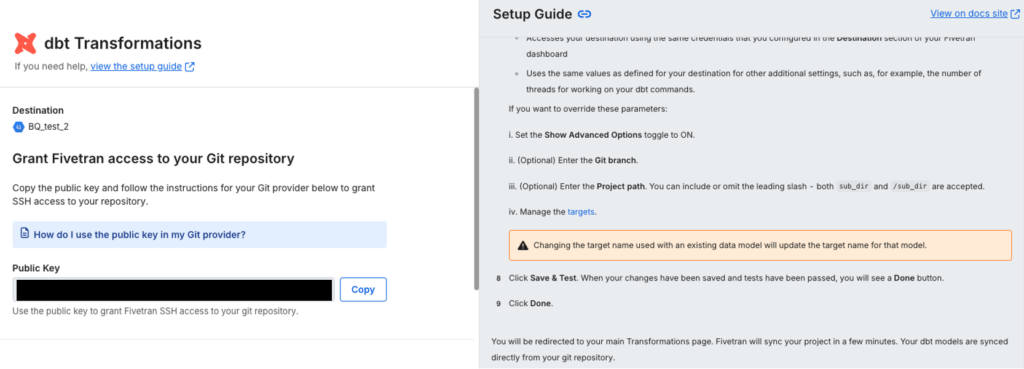
リポジトリのURL・接続方法・デフォルトのスキーマ名・dbt coreのバージョンを設定します。
- 接続方法はConnect directlyを選択
- デフォルトのスキーマ名が、BQのテーブル名になります
- dbt coreのバージョンは、1.10.11(選択できる最新バージョン)を選択
Save & Testで接続をテストします。
Manage projectsから、作成したプロジェクトを確認できます。
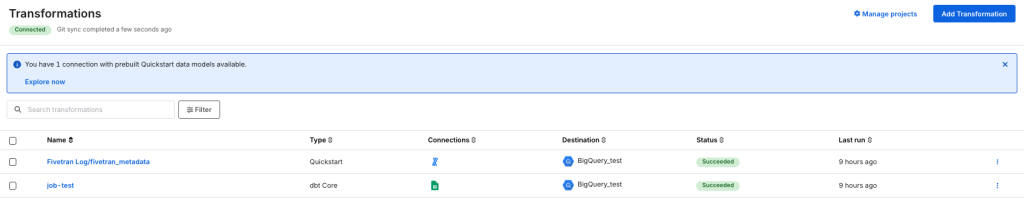
今回は、BigQuery_testに対してdbt coreを利用してデータ変換を行うプロジェクトを作成しました。

ジョブ設定
Add Transformationから、作成したプロジェクトのdestinationsを選択します。
プロジェクトが作成済みの変換ツールは、Create jobと表示されます。
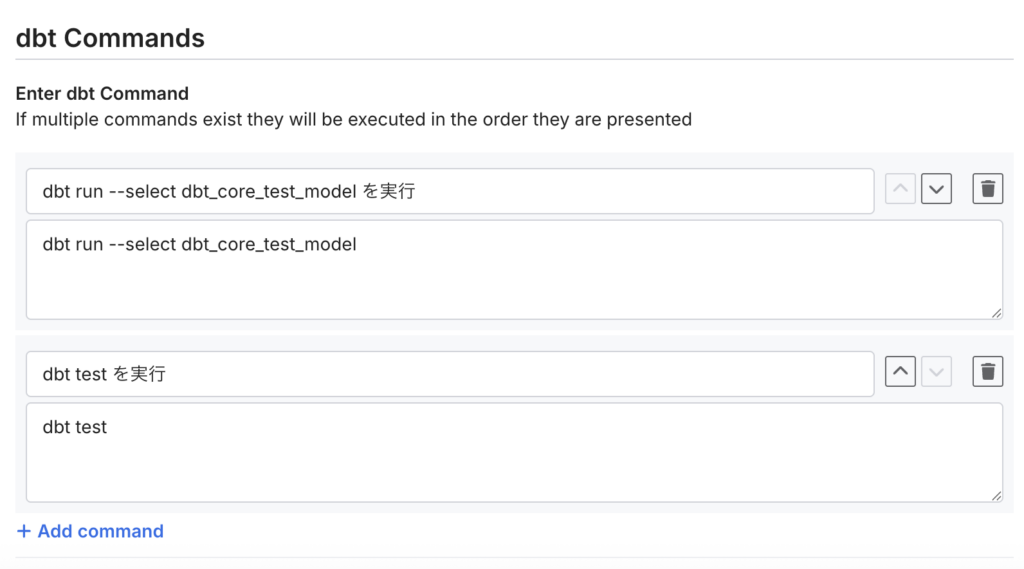
ジョブの名前 / 実行するdbtコマンド / 実行スケジュールを入力します。
dbt run, dbt test など複数のコマンドを一つのジョブ内に定義できます。
この例では、dbt_core_test_modelの実行と、dbt testの実行を定義しています。
サポートされているコマンド一覧
https://fivetran.com/docs/transformations/dbt/dbt-commands
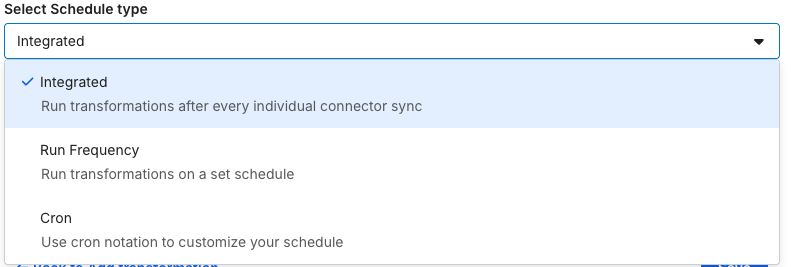
実行スケジュールでは、コネクタが同期するごと / 曜日と頻度を指定 / Cron表記で指定が可能です。
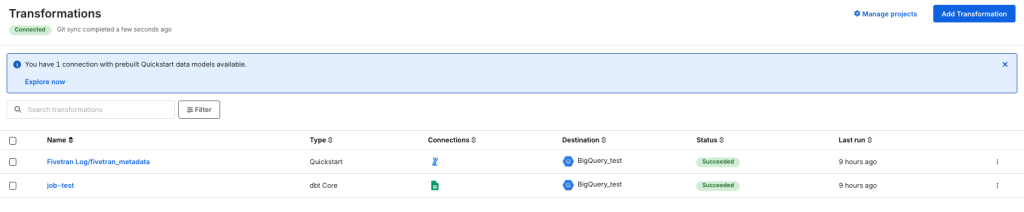
保存して設定できれば、Transformation画面にジョブが表示されます。
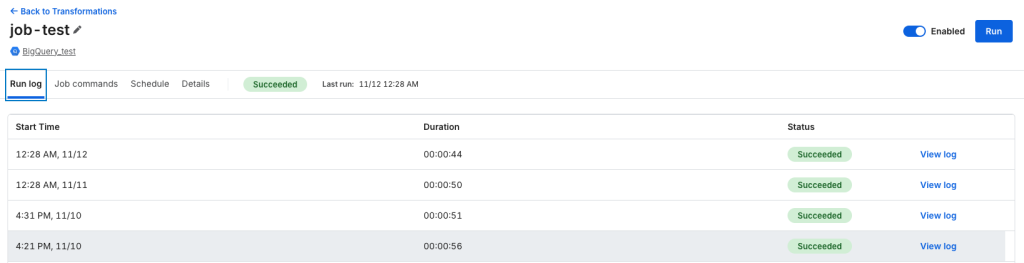
ジョブの詳細から、
実行ログ / dbtコマンドの変更 / スケジュールの変更 /
ジョブの一時停止 / 手動実行 が可能です。
実行結果の確認
Fivetranでの設定が完了したので、BigQuery側で実行結果を確認してみしょう。
プレビューが表示されているのが、コネクタでロードしたテーブルです。
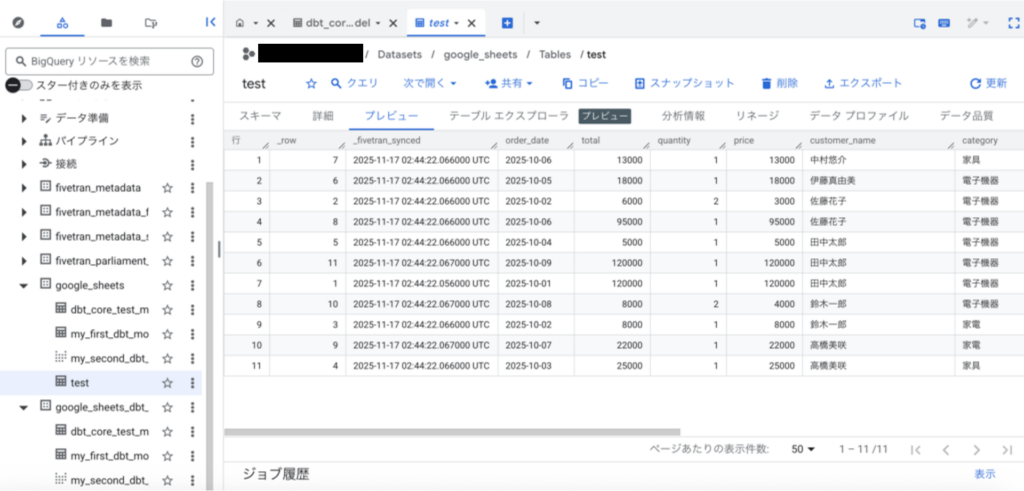
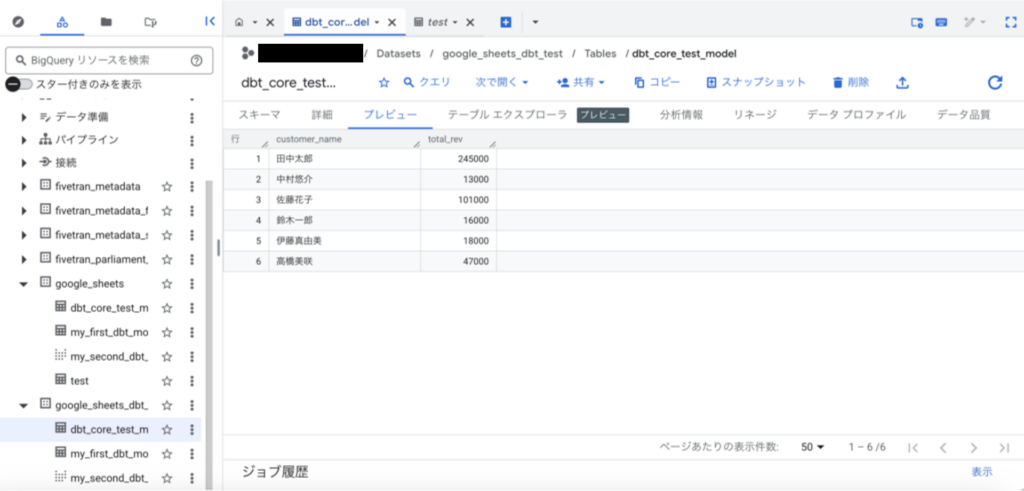
dbt coreで定義した、dbt_core_test_modelテーブルも作成されていることが確認できました。
また、dbtプロジェクトで記述されているデータ変換が実行されていることもわかります。
(顧客ごとの売上の合計が計算されています)
まとめ
今回は、Fivetranからdbtプロジェクトを実行して、データの取得から変換まで一連のプロセスを自動化する方法を解説しました。
前回紹介したデータロードと組み合わせることで、データの取得から整形までを運用負荷を抑えつつ安定して実行できるようになります。
個人的には、複数のプラットフォームやサービスを行き来してログを確認したり、別々のドキュメントを参照したりしなくて済む点がとても便利だと感じました。
Fivetran内で処理の流れが一元的に把握できるので、運用が楽になりそうです!
この記事が、データ活用基盤の構築や、ETLの自動化に取り組む方の参考になれば幸いです。




